Download to read offline













![// convert RDD -> DF with column names
parsedDF = parsedRDD.toDF("project", "sprint", "numStories")
// filter, groupBy, sum, and then agg()
parsedDF.filter(lambda x: x[1] === "finance")
.groupBy("sprint")
.agg(sum("numStories").as("count"))
.limit(100)
.show(100)
project sprint numStories
finance 3 20
finance 4 22](https://image.slidesharecdn.com/pyconlt19-nomorestruggleswithapachesparkpysparkworkloadsinproduction-190526103244/75/PyConLT19-No_more_struggles_with_Apache_Spark_-PySpark-_workloads_in_production-16-2048.jpg)




![● Pandas - Analyze small datasets.
● Spark - Analyze large size of datasets.
Pandas DataFrame Spark DataFrame
Column df['col'] df['col']
Mutability Mutable Immutable
Add a Column df['Z'] = df['X'] +
df['Y']
df.withColumn('Z',
df['X'] + df['Y'])
Rename columns df.columns = ['X', 'Y'] df.select(df['Q1'].as('X'
), df['P1'].as('Y'))
Ref Example, https://github.com/chetkhatri/PyConLT2019](https://image.slidesharecdn.com/pyconlt19-nomorestruggleswithapachesparkpysparkworkloadsinproduction-190526103244/75/PyConLT19-No_more_struggles_with_Apache_Spark_-PySpark-_workloads_in_production-21-2048.jpg)



























![[1] Koalas: pandas API on Apache Spark
[URL] https://github.com/databricks/koalas
[2] An open-source storage layer that brings scalable, ACID transactions
to Apache Spark™ and big data workloads. https://delta.io
[URL] https://github.com/delta-io/delta
[3] Leveraging Spark Speculation To Identify And Re-Schedule Slow Running
Tasks.
https://blog.yuvalitzchakov.com/leveraging-spark-speculation-to-identify-
and-re-schedule-slow-running-tasks/](https://image.slidesharecdn.com/pyconlt19-nomorestruggleswithapachesparkpysparkworkloadsinproduction-190526103244/75/PyConLT19-No_more_struggles_with_Apache_Spark_-PySpark-_workloads_in_production-58-2048.jpg)



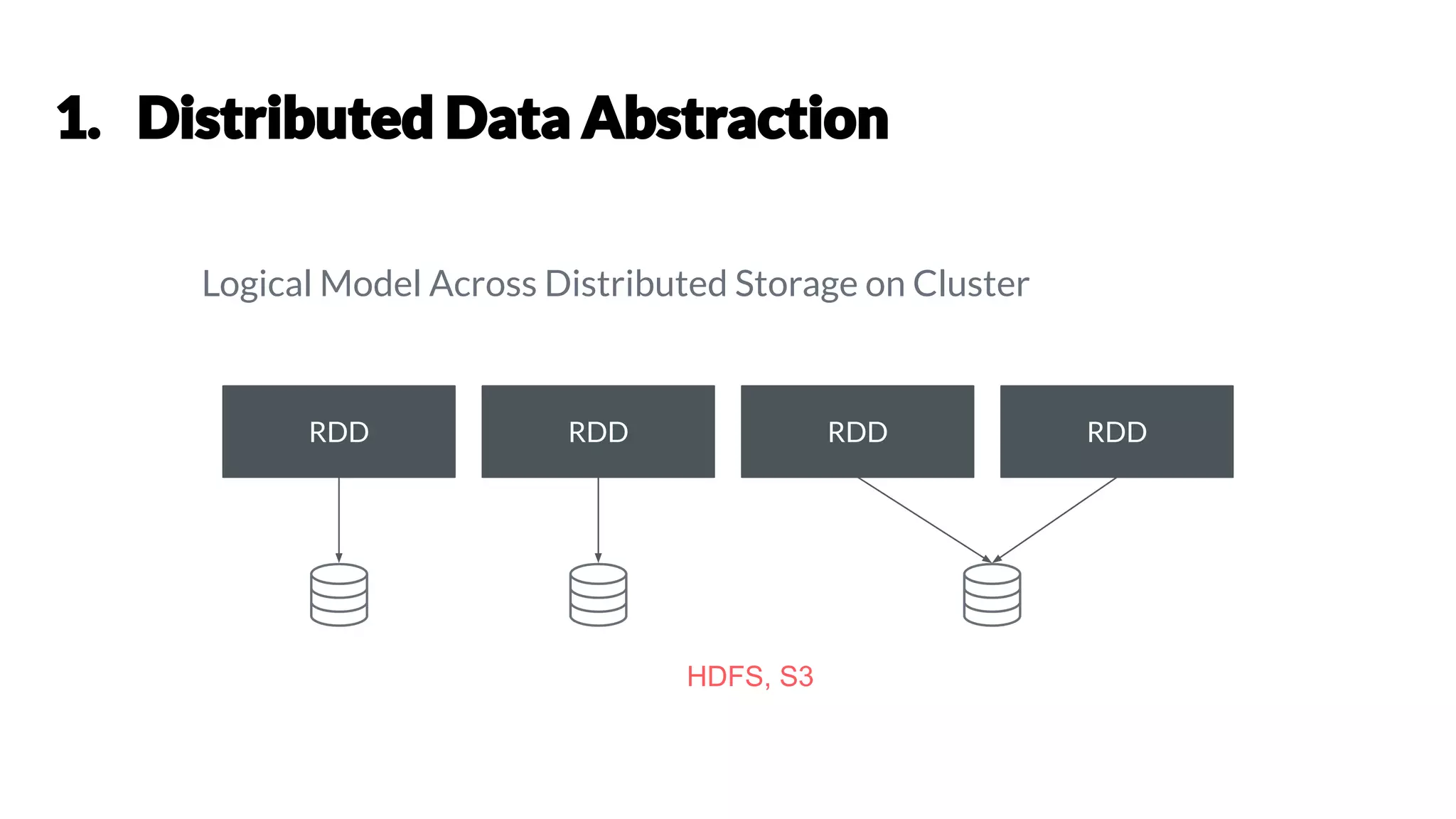
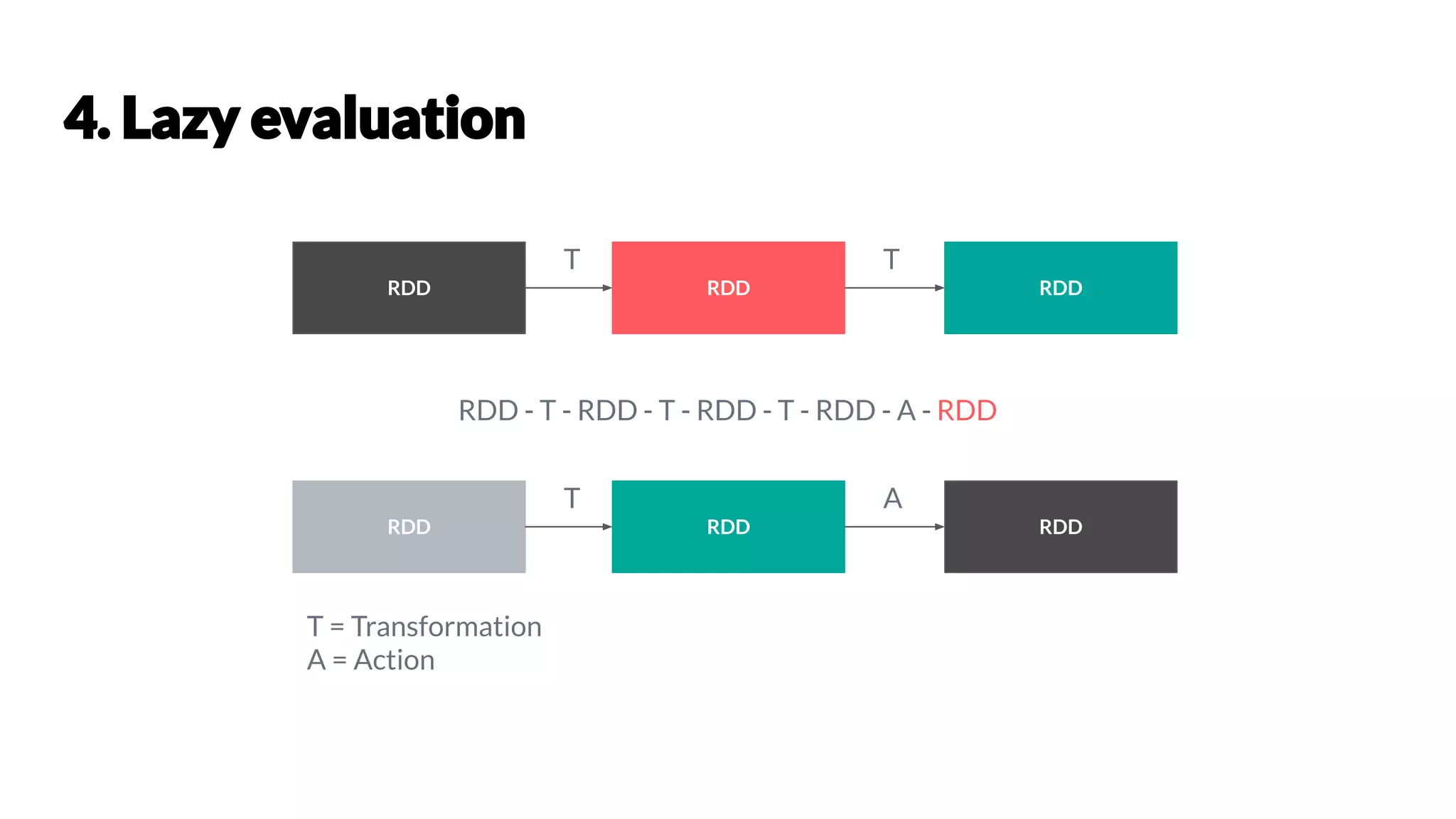
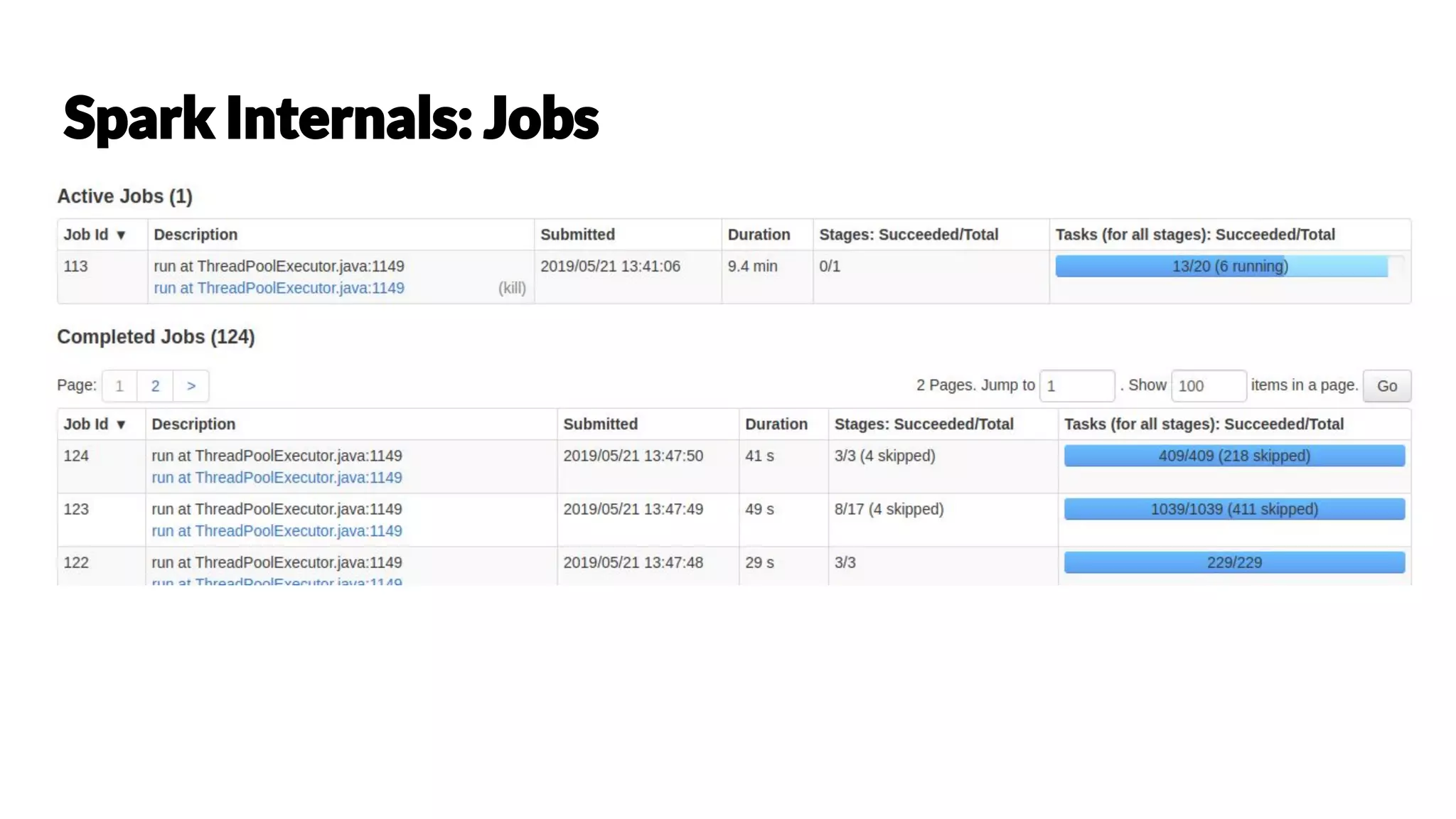
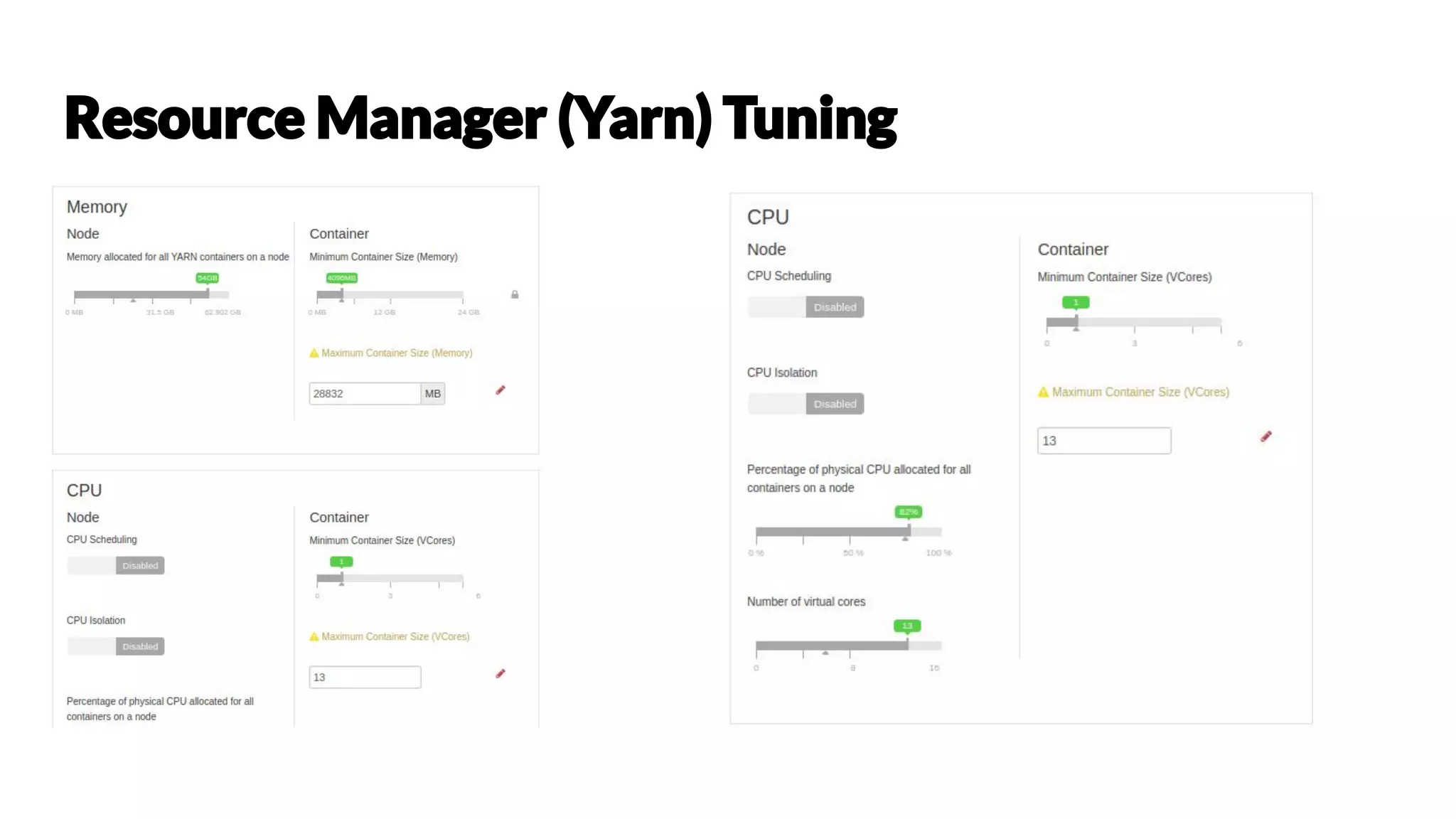
Chetan Khatri is a Data Science Practice Leader at Accion Labs India with expertise in Apache Spark and data engineering. The document covers various aspects of Apache Spark, including its capabilities, architecture, optimization strategies, and practical examples for data processing. It discusses the differences between Pandas and Spark DataFrames, along with execution planning and resource management techniques within Spark.





































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)




