Download as PDF, PPTX










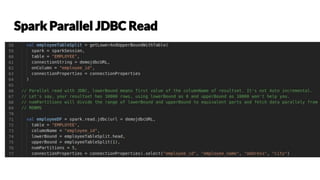
![val employeesDF = spark.read.json("employees.json")
// Convert data to domain objects.
case class Employee(name: String, age: Int)
val employeesDS: Dataset[Employee] = employeesDF.as[Employee]
val filterDS = employeesDS.filter(p => p.age > 3)
Type-safe: operate on domain
objects with compiled lambda
functions.](https://image.slidesharecdn.com/parisscalagroup23rd-may-2019nomorestruggleswithapachesparkworkloadsinproduction-190527051811/85/No-more-struggles-with-Apache-Spark-workloads-in-production-14-320.jpg)

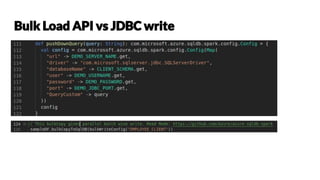
![Strongly Typing
Ability to use powerful lambda functions.
Spark SQL’s optimized execution engine (catalyst, tungsten)
Can be constructed from JVM objects & manipulated using Functional
transformations (map, filter, flatMap etc)
A DataFrame is a Dataset organized into named columns
DataFrame is simply a type alias of Dataset[Row]](https://image.slidesharecdn.com/parisscalagroup23rd-may-2019nomorestruggleswithapachesparkworkloadsinproduction-190527051811/85/No-more-struggles-with-Apache-Spark-workloads-in-production-16-320.jpg)

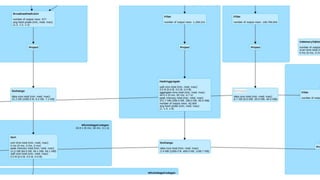
![DataFrame
Dataset
Untyped API
Typed API
Dataset
(2016)
DataFrame = Dataset [Row]
Alias
Dataset [T]](https://image.slidesharecdn.com/parisscalagroup23rd-may-2019nomorestruggleswithapachesparkworkloadsinproduction-190527051811/85/No-more-struggles-with-Apache-Spark-workloads-in-production-18-320.jpg)


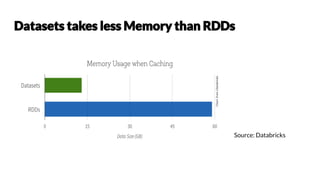
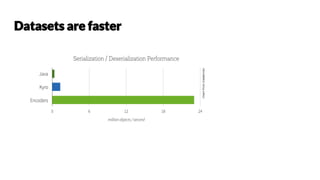


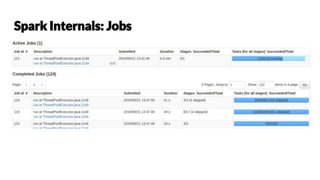

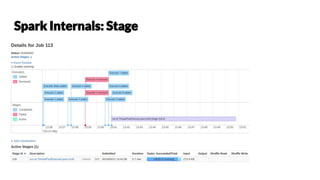























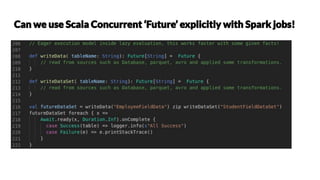




Chetan Khatri leads data science at Accion Labs India and is involved with Apache Spark and HBase, emphasizing the importance of optimization and best practices in data processing. The document covers various aspects of Apache Spark including data structures, execution strategies, and transformation actions. It also highlights the significance of type safety and performance optimization strategies for effective data handling.




















![Introduction to Pandas and Time Series Analysis [Budapest BI Forum]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysis-170617163829-thumbnail.jpg?width=640&height=640&fit=bounds)


































































