Download as PDF, PPTX



















![DataFrame
noun – [dey-tuh-freym]
1. A distributed collection of rows
organized into named columns.
2. An abstraction for selecting, filtering,
aggregating and plotting structured
data (cf. R, Pandas).
3. Archaic: Previously SchemaRDD
(cf. Spark < 1.3).](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-20-320.jpg)







![Write Less Code: Compute an Average
private
IntWritable
one
=
new
IntWritable(1)
private
IntWritable
output
=
new
IntWritable()
proctected
void
map(
LongWritable
key,
Text
value,
Context
context)
{
String[]
fields
=
value.split("t")
output.set(Integer.parseInt(fields[1]))
context.write(one,
output)
}
IntWritable
one
=
new
IntWritable(1)
DoubleWritable
average
=
new
DoubleWritable()
protected
void
reduce(
IntWritable
key,
Iterable<IntWritable>
values,
Context
context)
{
int
sum
=
0
int
count
=
0
for(IntWritable
value
:
values)
{
sum
+=
value.get()
count++
}
average.set(sum
/
(double)
count)
context.Write(key,
average)
}
data
=
sc.textFile(...).split("t")
data.map(lambda
x:
(x[0],
[x.[1],
1]))
.reduceByKey(lambda
x,
y:
[x[0]
+
y[0],
x[1]
+
y[1]])
.map(lambda
x:
[x[0],
x[1][0]
/
x[1][1]])
.collect()](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-28-320.jpg)
![Write Less Code: Compute an Average
Using RDDs
data
=
sc.textFile(...).split("t")
data.map(lambda
x:
(x[0],
[int(x[1]),
1]))
.reduceByKey(lambda
x,
y:
[x[0]
+
y[0],
x[1]
+
y[1]])
.map(lambda
x:
[x[0],
x[1][0]
/
x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name",
avg("age"))
.collect()
Using SQL
SELECT
name,
avg(age)
FROM
people
GROUP
BY
name](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-29-320.jpg)






![Machine Learning Pipelines
tokenizer
=
Tokenizer(inputCol="text", outputCol="words”)
hashingTF
=
HashingTF(inputCol="words", outputCol="features”)
lr
=
LogisticRegression(maxIter=10,
regParam=0.01)
pipeline
=
Pipeline(stages=[tokenizer,
hashingTF,
lr])
df
=
sqlCtx.load("/path/to/data")
model
=
pipeline.fit(df)
df0 df1 df2 df3tokenizer hashingTF lr.model
lr
Pipeline Model](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-36-320.jpg)







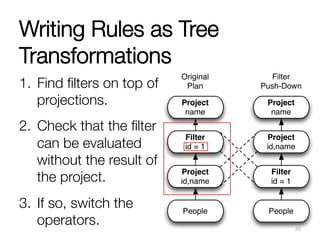
![Tree Transformations
Developers express tree transformations as
PartialFunction[TreeType,TreeType]
1. If the function does apply to an operator, that
operator is replaced with the result.
2. When the function does not apply to an
operator, that operator is left unchanged.
3. The transformation is applied recursively to all
children.
44](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-44-320.jpg)









![Future Work – Project Tungsten
Consider “abcd” – 4 bytes with UTF8 encoding
java.lang.String
object
internals:
OFFSET
SIZE
TYPE
DESCRIPTION
VALUE
0
4
(object
header)
...
4
4
(object
header)
...
8
4
(object
header)
...
12
4
char[]
String.value
[]
16
4
int
String.hash
0
20
4
int
String.hash32
0
Instance
size:
24
bytes
(reported
by
Instrumentation
API)](https://image.slidesharecdn.com/melbourne-150603054503-lva1-app6891/85/Spark-SQL-Deep-Dive-Melbourne-Spark-Meetup-55-320.jpg)



This document summarizes a presentation on Spark SQL and its capabilities. Spark SQL allows users to run SQL queries on Spark, including HiveQL queries with UDFs, UDAFs, and SerDes. It provides a unified interface for reading and writing data in various formats. Spark SQL also allows users to express common operations like selecting columns, joining data, and aggregation concisely through its DataFrame API. This reduces the amount of code users need to write compared to lower-level APIs like RDDs.























































































