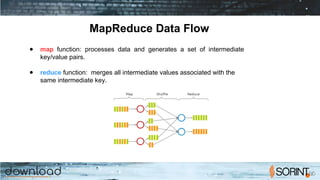
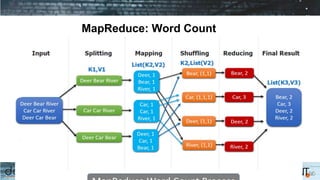
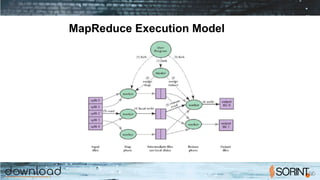
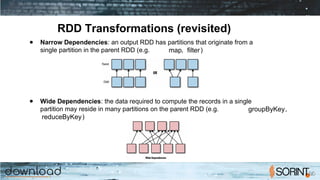
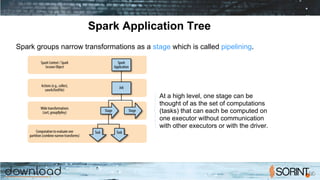
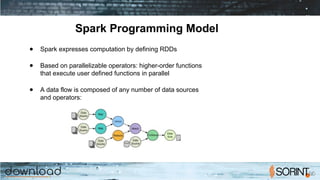
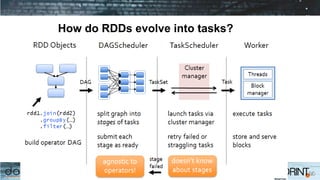
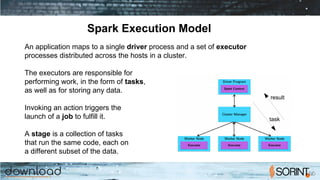
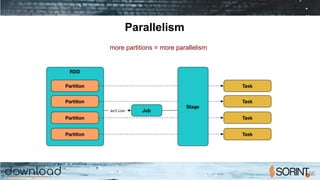
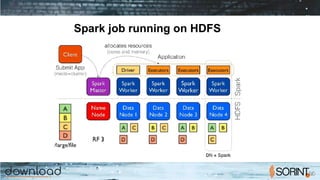
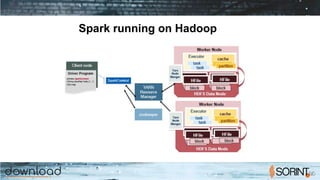
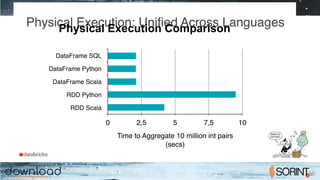
Apache Spark is a cluster computing framework that allows for fast, easy, and general processing of large datasets. It extends the MapReduce model to support iterative algorithms and interactive queries. Spark uses Resilient Distributed Datasets (RDDs), which allow data to be distributed across a cluster and cached in memory for faster processing. RDDs support transformations like map, filter, and reduce and actions like count and collect. This functional programming approach allows Spark to efficiently handle iterative algorithms and interactive data analysis.










![Scala Crash Course (cont.)
// Tuples
// Immutable lists
val captainStuff = ("Picard", "EnterpriseD", "NCC1701D")
//> captainStuff : (String, String, String) = ...
// Lists
// Like a tuple with more functionality, but it cannot hold items of different types.
val shipList = List("Enterprise", "Defiant", "Voyager", "Deep Space Nine") //> shipList : List[String]
// Access individual members using () with ZEROBASED index
println(shipList(1)) //> Defiant
// Let's apply a function literal to a list. map() can be used to apply any function to every item in a collection.
val backwardShips = shipList.map( (ship: String) => {ship.reverse} )
//> backwardShips : List[String] = ...
//| pS peeD)
for (ship <backwardShips) { println(ship) } //> esirpretnE
//| tnaifeD
//| regayoV
//| eniN ecapS peeD](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-14-320.jpg)
![Scala Crash Course (cont.)
// reduce() can be used to combine together all the items in a collection using some function.
val numberList = List(1, 2, 3, 4, 5) //> numberList : List[Int] = List(1, 2, 3, 4, 5)
val sum = numberList.reduce( (x: Int, y: Int) => x + y )
//> sum : Int = 15
println(sum) //> 15
// filter() can remove stuff you don't want. Here we'll introduce wildcard syntax while we're at it.
val iHateFives = numberList.filter( (x: Int) => x != 5 )
//> iHateFives : List[Int] = List(1, 2, 3, 4)
val iHateThrees = numberList.filter(_ != 3) //> iHateThrees : List[Int] = List(1, 2, 4, 5)](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-15-320.jpg)













![Interactive Spark application
$ bin/sparkshell
Using Spark's default log4j profile: org/apache/spark/log4jdefaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.1.137:4041
Spark context available as 'sc' (master = local[*], app id = local1534089873554).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@281963c
scala>](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-35-320.jpg)























![Netcat Streaming Example
...
Time: 1535630570000 ms
(how,1)
(into,1)
(go,1)
(what,1)
(program,,1)
(want,1)
(looks,1)
(program,1)
(Spark,2)
(a,4)
...
Time: 1535630580000 ms
[sparkuser@horst ~]$ nc lk 9999
...
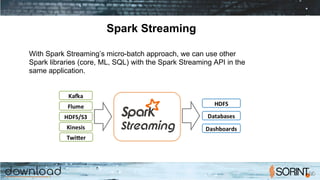
Spark Streaming is a special SparkContext
that you can use for processing data quickly
in neartime. It’s similar to the standard
SparkContext, which is geared toward batch
operations. Spark Streaming uses a little
trick to create small batch windows (micro
batches) that offer all of the advantages of
Spark: safe, fast data handling and lazy
evaluation combined with realtime
processing. It’s a combination of both batch
and interactive processing.
...](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-66-320.jpg)








































































