Download to read offline







![Example: WordCount
scala> counts.toDebugString
(2) ShuffledRDD[8] at reduceByKey at <console>:23 []
+-(2) MapPartitionsRDD[7] at map at <console>:23 []
| MapPartitionsRDD[6] at flatMap at <console>:23 []
| MapPartitionsRDD[5] at textFile at <console>:21 []
| hdfs: //xxx HadoopRDD[4] at textFile at <console>:21 []](https://image.slidesharecdn.com/spark-160716060651/75/Spark-10-2048.jpg)






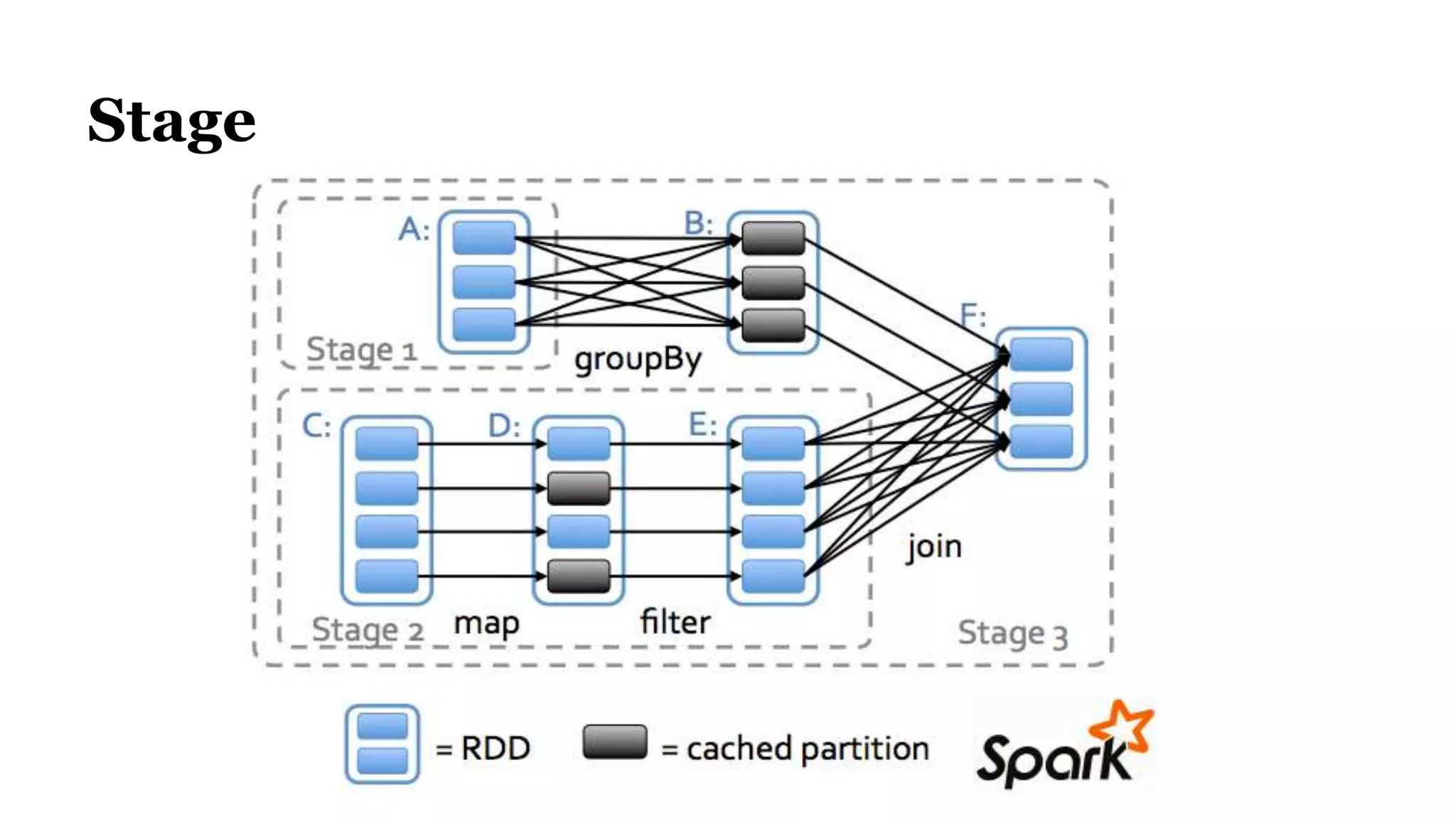
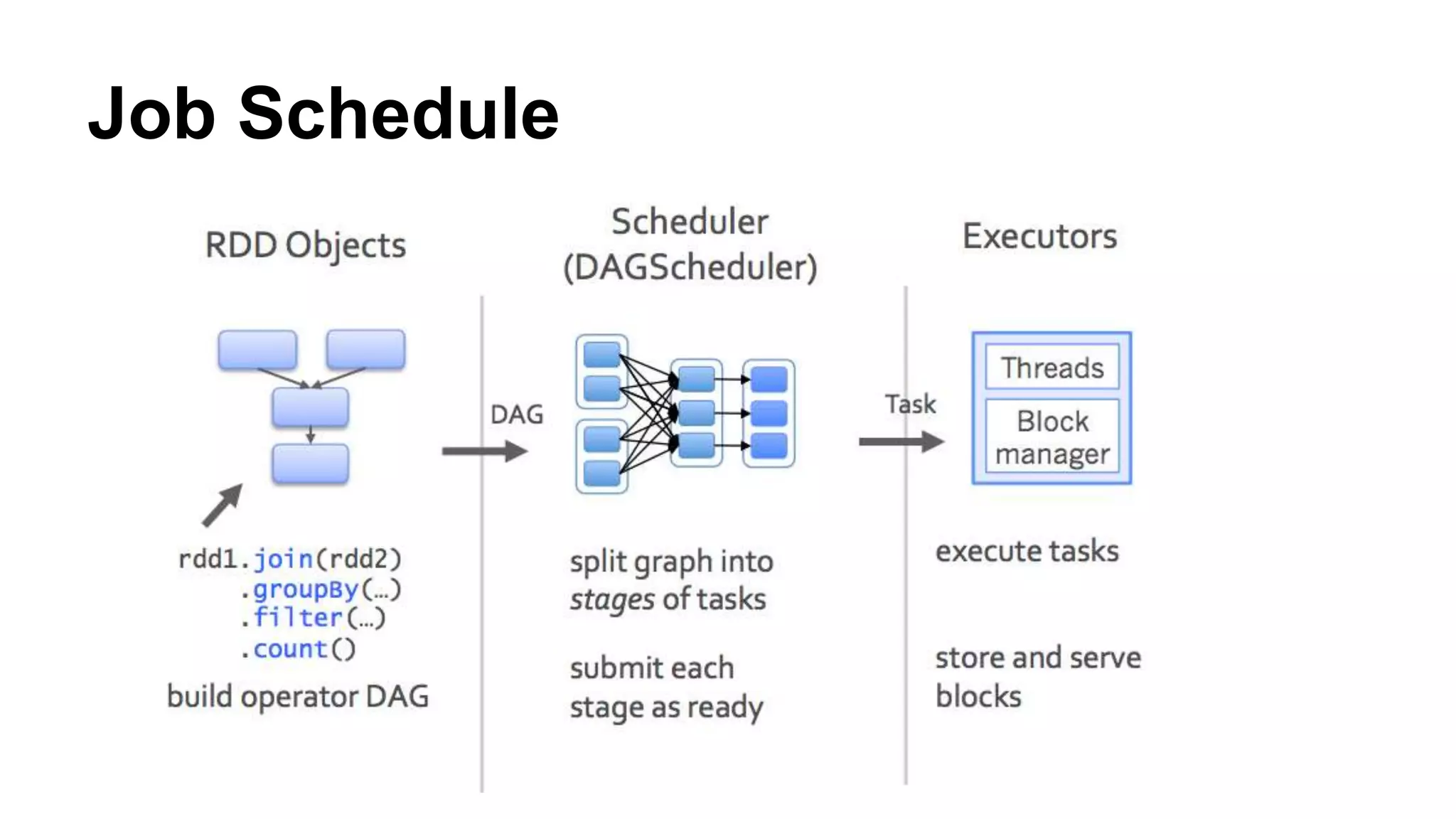

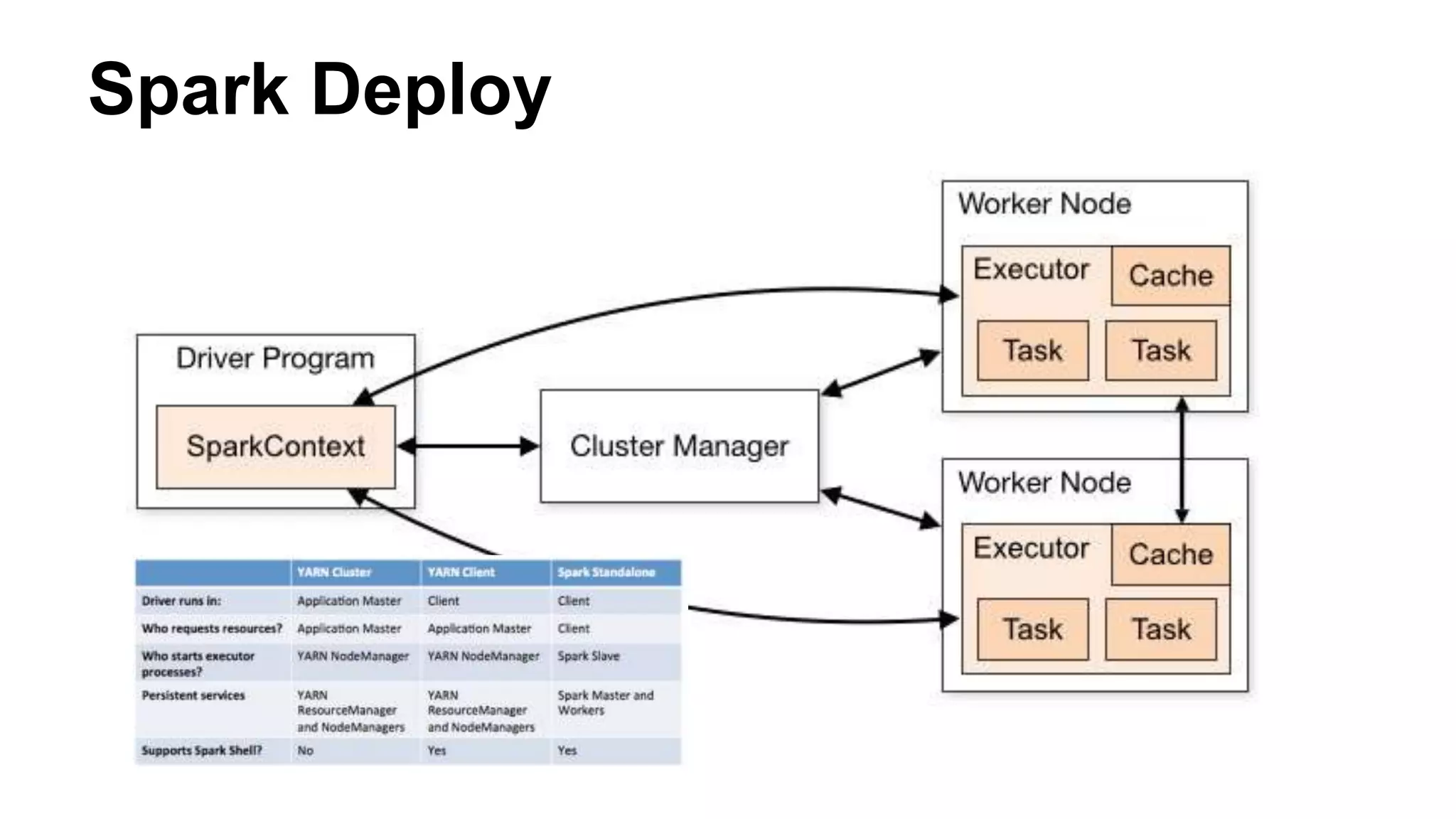


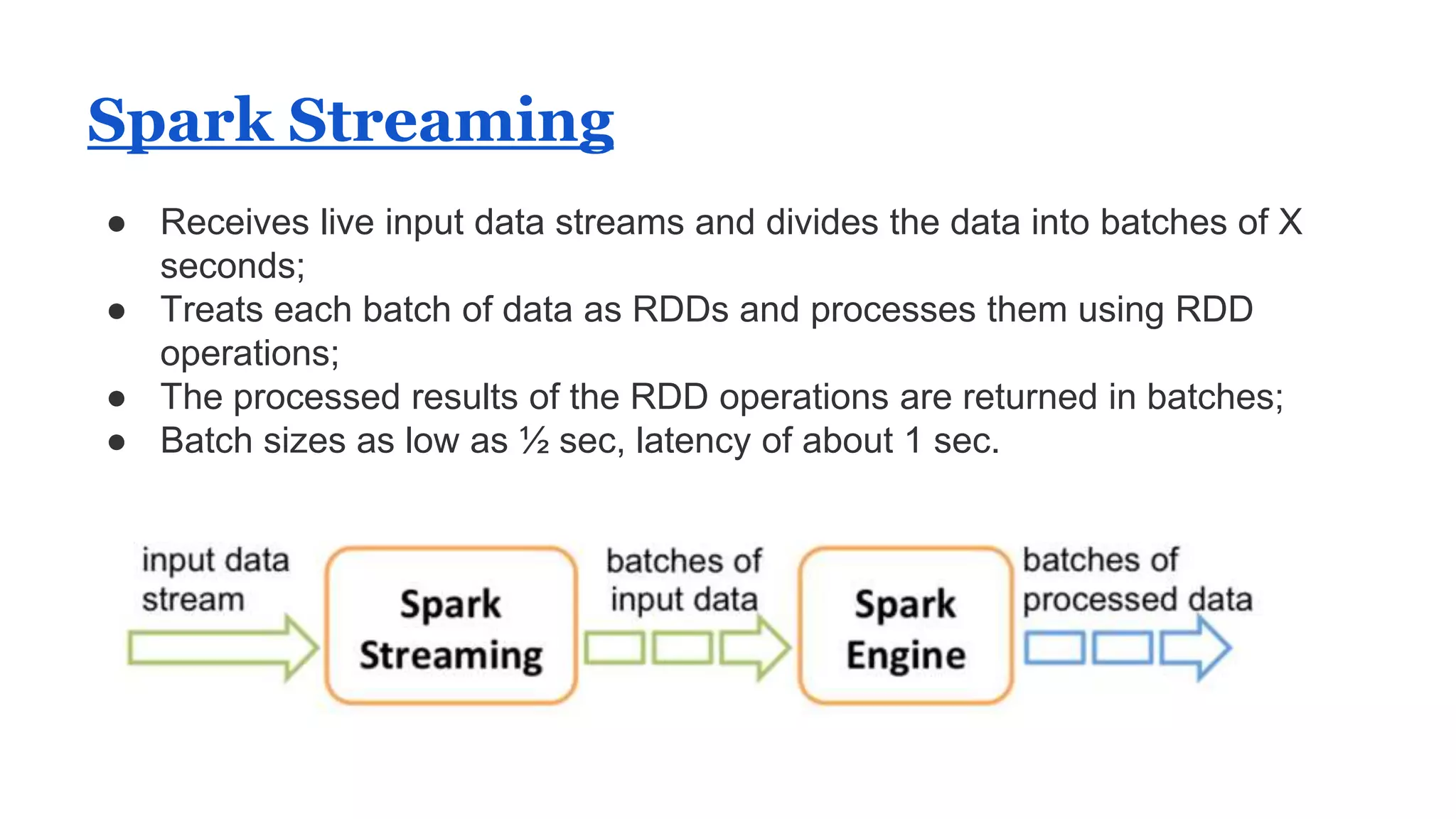





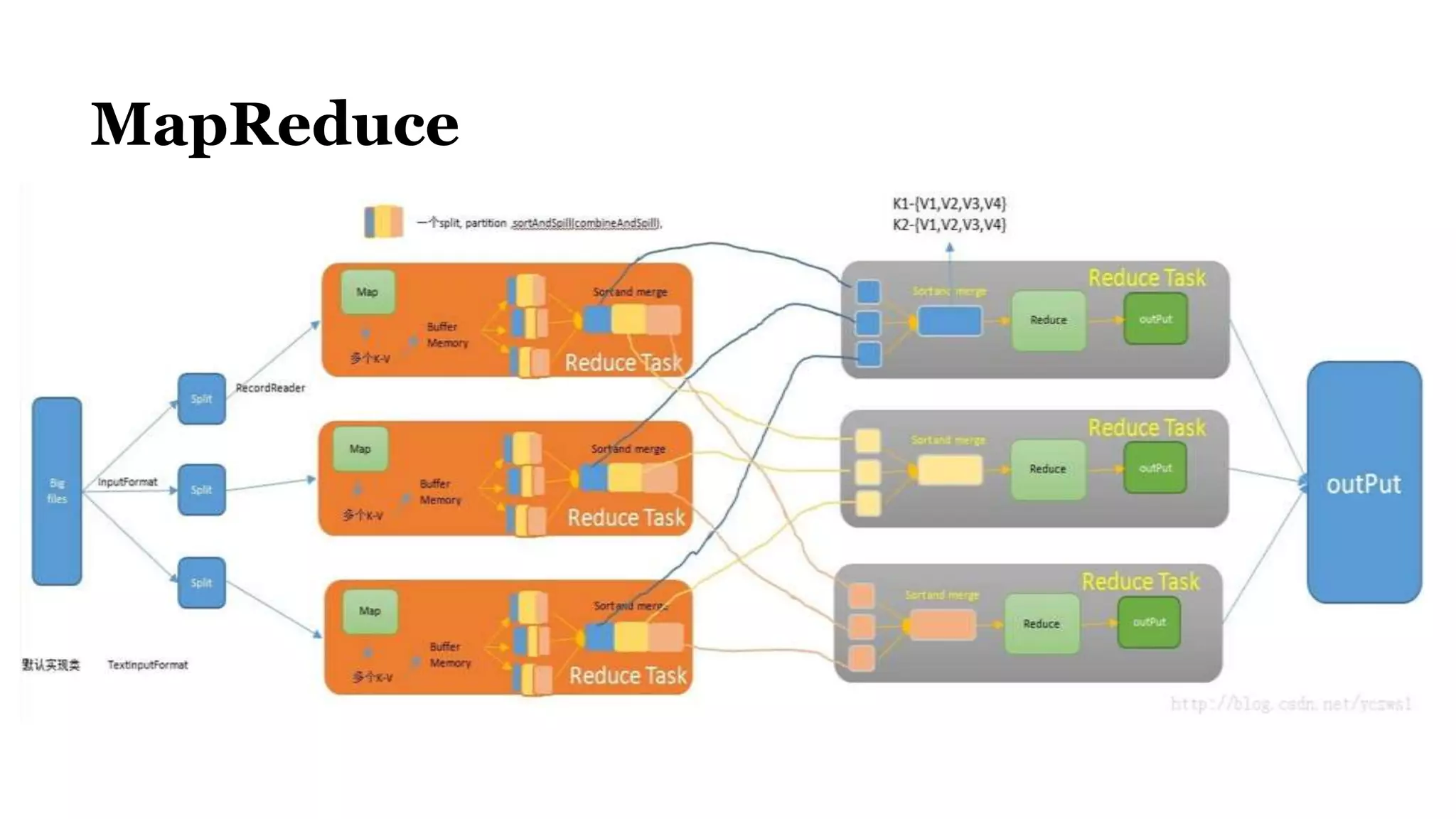
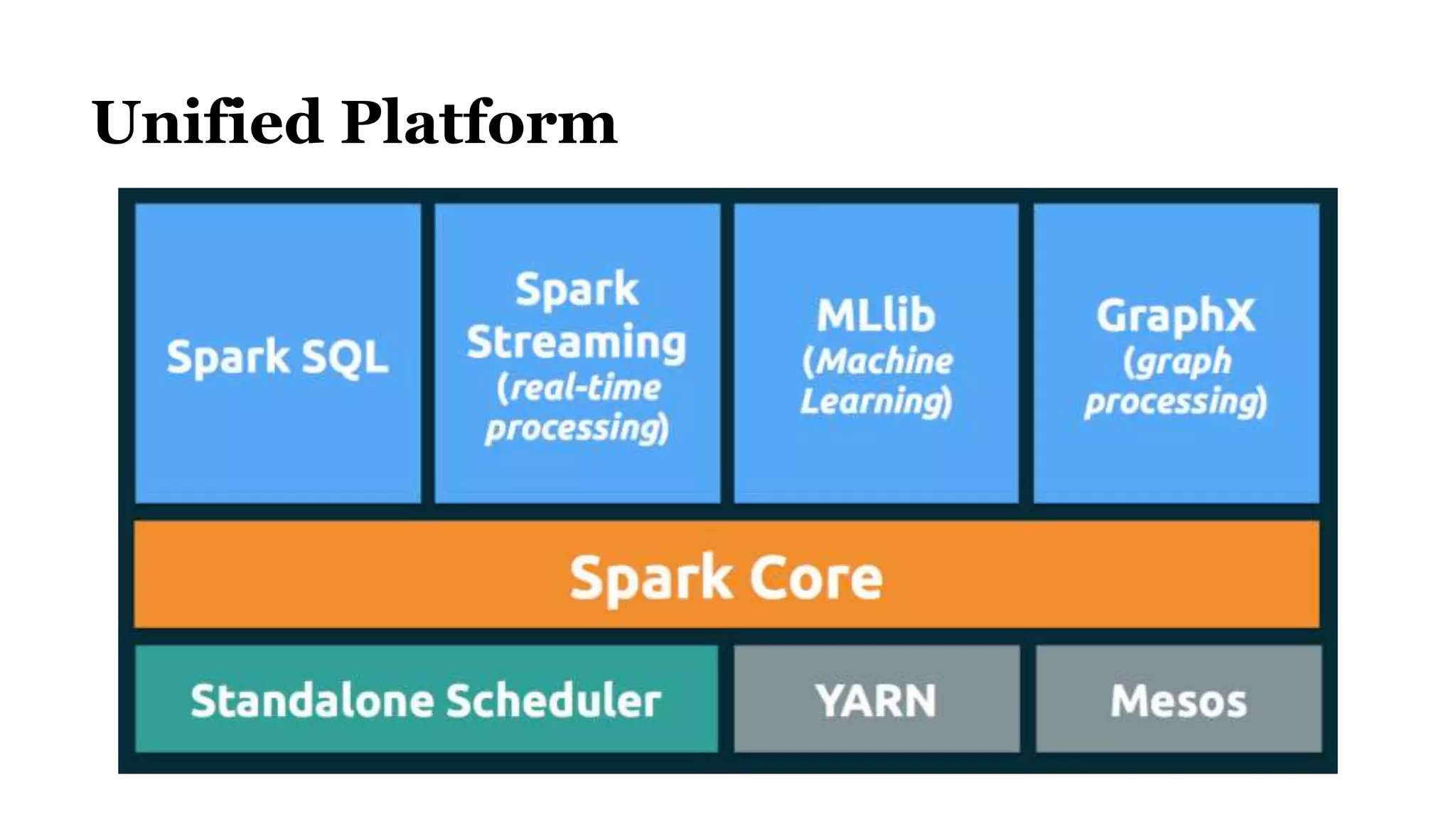
The document discusses Spark, an open-source cluster computing framework. It describes Spark's Resilient Distributed Dataset (RDD) as an immutable and partitioned collection that can automatically recover from node failures. RDDs can be created from data sources like files or existing collections. Transformations create new RDDs from existing ones lazily, while actions return values to the driver program. Spark supports operations like WordCount through transformations like flatMap and reduceByKey. It uses stages and shuffling to distribute operations across a cluster in a fault-tolerant manner. Spark Streaming processes live data streams by dividing them into batches treated as RDDs. Spark SQL allows querying data through SQL on DataFrames.


















































































