Downloaded 20 times








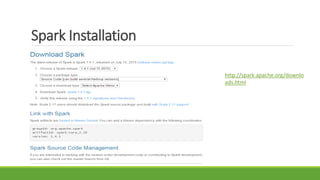
![Spark Installation
• Extract compressed folder spark-1.3.0-binhadoop2.4
• From terminal, go to spark-1.3.0-bin-hadoop2.4/
bin
• Run pyspark
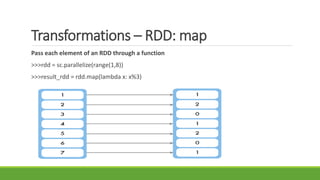
• Run rdd = sc.parallelize([0, 1, 2]);
rdd.map(lambda x: x*x).collect()
• Get result [0,1,4]
• It’s that easy!
Windows users might need to download and
run additional winutils.exe for smooth
running of applications
Download winutils here
http://www.srccodes.com/p/article/39/error
-util-shell-failed-locate-winutils-binary-
hadoop-binary-path.
and add to $HADOOP_HOME/bin
• Download a bigger zip (1.9GB) from
http://bit.ly/1FpZAXH](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-11-320.jpg)



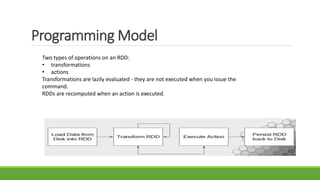
![FIRST STEP IN DATA ANALYSIS :
Create an RDD
Read data from a text file on local machine , S3 or HDFS into RDD.
Give life to an RDD using Spark Context
# Convert a python collection to an RDD
# Turn a Python collection into an RDD
>sc.parallelize ([7, 8, 9])
# Load text file from local FS, HDFS, or S3
>sc.textFile(“textfile.txt”)
>sc.textFile(“directory/*.txt”)
>sc.textFile(“hdfs://namenode:9000/path/file”)](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-19-320.jpg)
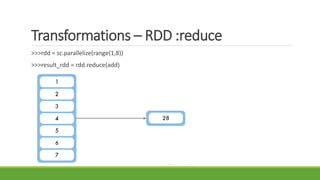
![RDD Transformations: Reduce By Key
>>>rdd = sc.parallelize([(‘Alice’,23), (‘Bob’,17), (‘Alice’,27)])
>>>result_rdd = rdd.reduceByKey(add)](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-22-320.jpg)
![Some more RDD Transformations
rdd.flatMap(f): Return a new RDD by first applying a function to all elements of this RDD, and
then flattening the results.
>>> rdd = sc.parallelize([2,3,4])
sorted(rdd.flatMap(lambda x: range(1,x)).collect() ?/* Collect is the action applied on
transformation
[1,1,1,2,2,3]
rdd.filter(f) : Return a new RDD containing only the elements that satisfy a predicate.
>>> rdd = sc.parallelize([1,2,3,4,5])
rdd.filter(lambda x: x%2 ==0).collect()
[2,4]](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-23-320.jpg)
![Some more RDD Transformations
sortBy(self, keyfunc, ascending=True, numPartitions=None)
Sorts this RDD by given keyfunc
>> rdd= [(‘a’,1),(’b’, 2) , (‘1’,3), (‘d’,4),(‘2’,5) ]
rdd = sc.parallelize(rdd).sortBy(lambda x:x[0]).
rdd.cache() : Cache RDD in memory for repeated use
countByKey(self):
rdd= sc.parallelize([ (“a”,1) , (“b”,1), (“a”,1) ])
rdd.countByKey().items()
join(self,other, numPartitions = None): Return an RDD containing all pairs of elements with
matching keys in self and others.](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-24-320.jpg)

![Some RDD Actions
RDD Transformations are lazily evaluated . Actions kick off computation on transformations.
Eg: Collect(), glom() etc
rdd.collect() : Return RDD content as a list
rdd = sc.parallelize([1,2,3], 3)
rdd2 = rdd.map(lambda x: x*x)
rdd2.glom().collect(): [1, 4, 9]
rdd.glom().collect():
rdd = sc.parallelize([0,1,2], 3)
rdd2 = rdd.map(lambda x: x*x)
rdd2.collect(): [[0], [1], [4]]
saveAsTextFile(path): Write the elements of the dataset as a text file (or set of text files) in a
given directory in the local filesystem, HDFS or any other Hadoop-supported file system.
take(n) :Return an array with the first n elements of the dataset.
first() : return the first element of the dataset. Similar to take(1)](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-26-320.jpg)

![Fault tolerant - Persistent
RDDs track lineage information that can be used to efficiently re compute lost data
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”))
.map(lambda s: s.split(“t”)[2])
Spark will persist or cache RDD slices in memory on each node during operations.
You can mark an RDD to be persisted with the cache method on an RDD along with a storage level.](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-29-320.jpg)



![K-Means
# Import the required pyspark functions
from pyspark.mllib.clustering import KMeans
from numpy import array
from math import sqrt
from pyspark import SparkContext
sc =SparkContext()
data = sc.textFile("C:UserssnehachallaDownloadsspark-1.4.1-bin-hadoop2.4spark-1.4.1-bin-hadoop2.4binkmeans_data.txt")
parsedData = data.map(lambda line:array([float(x) for x in line.split(' ')])).cache()](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-33-320.jpg)
![K-Means (Cont..)
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 2, maxIterations = 10,runs = 1, initializationMode = "k-means||")
# Evaluate clustering by computing the sum of squared errors
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
cost = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x + y)
print("Sum of squared error = " + str(cost))](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-34-320.jpg)
![Logistic Regression
from pyspark.mllib.classification import LogisticRegressionWithSGD
from numpy import array
# Load and parse the data
data = sc.textFile("mllib/data/sample_svm_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
model = LogisticRegressionWithSGD.train(parsedData)
# Build the model
labelsAndPreds = parsedData.map(lambda point: (int(point.item(0)),
model.predict(point.take(range(1, point.size)))))
# Evaluating the model on training data
trainErr = labelsAndPreds.filter(lambda (v, p): v != p).count() / float(parsedData.count())
print("Training Error = " + str(trainErr)](https://image.slidesharecdn.com/apachespark-snehachalla-googlepittsburgh-aug25th-150825232102-lva1-app6891/85/Apache-spark-sneha-challa-google-pittsburgh-aug-25th-35-320.jpg)
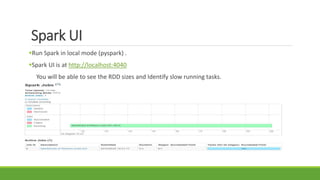






The document is a presentation about Apache Spark given on August 25th, 2015 in Pittsburgh by Sneha Challa. It introduces Spark as a fast and general cluster computing engine for large-scale data processing. It discusses Spark's Resilient Distributed Datasets (RDDs) and transformations/actions. It provides examples of Spark APIs like map, reduce, and explains running Spark on standalone, Mesos, YARN, or EC2 clusters. It also covers Spark libraries like MLlib and running machine learning algorithms like k-means clustering and logistic regression.


























































































