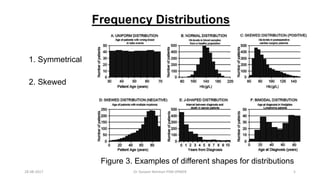
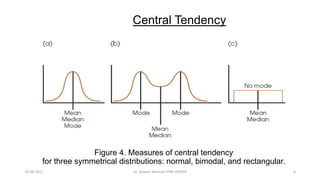
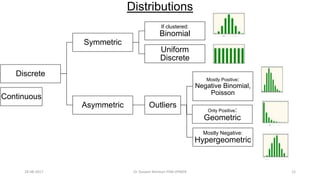
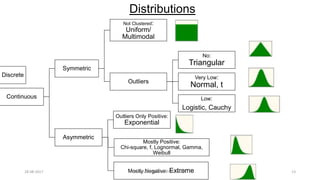
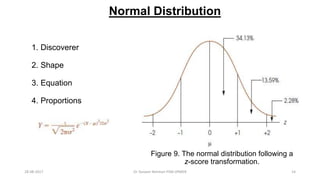
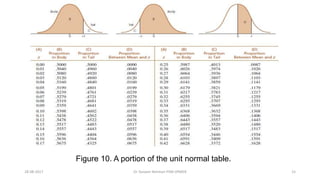
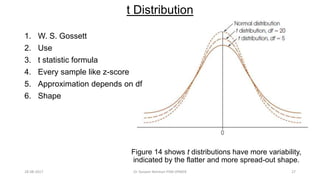
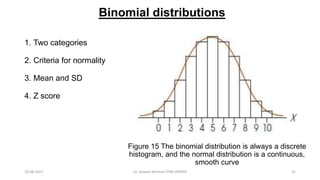
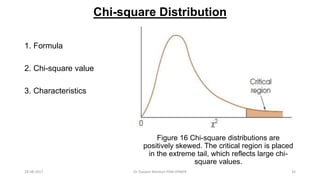
This document provides an outline and slides for a presentation on statistical distributions. It begins with an introduction to frequency distributions, measures of central tendency, variability, z-scores, and theoretical distributions. Examples of different types of distributions are shown including normal, binomial, t and chi-square distributions. The document concludes with examples of how to apply these distributions to calculate probabilities and test hypotheses related to health data.



















![AP Stats Chapter 1 Exploring Data [Autosaved] (1).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/apstatschapter1exploringdataautosaved1-240908213027-9f0b3ffa-thumbnail.jpg?width=640&height=640&fit=bounds)








































































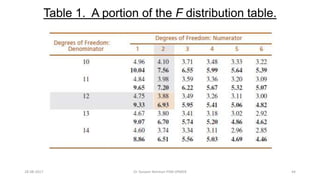
![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)













