Download as PDF, PPTX




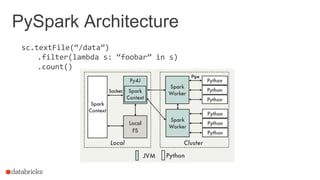
![Moving beyond Python performance
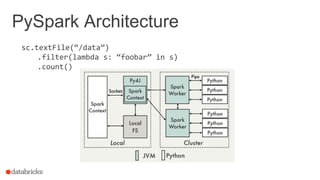
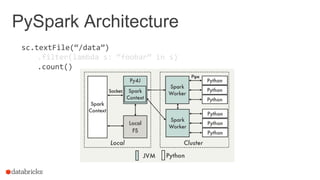
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
11](https://image.slidesharecdn.com/sseu-sparkinproduction-151029122932-lva1-app6891/85/Spark-Summit-EU-2015-Lessons-from-300-production-users-11-320.jpg)
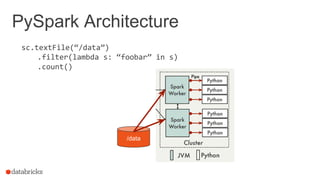
![Moving beyond Python performance
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
12](https://image.slidesharecdn.com/sseu-sparkinproduction-151029122932-lva1-app6891/85/Spark-Summit-EU-2015-Lessons-from-300-production-users-12-320.jpg)
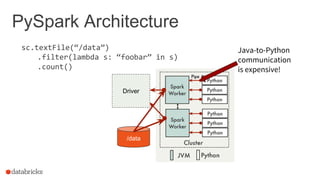
![Moving beyond Python performance
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
13
(At least as much as possible!)](https://image.slidesharecdn.com/sseu-sparkinproduction-151029122932-lva1-app6891/85/Spark-Summit-EU-2015-Lessons-from-300-production-users-13-320.jpg)



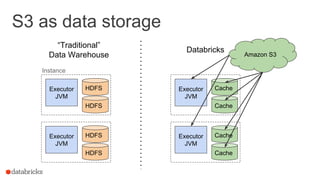


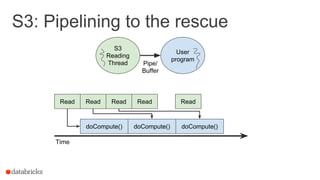
val numRead = s3File.read(bytes)
numRead = ?
8999 1 8999 1 8999 1 8999 1 8999 1 8999 1
Answer: buffering!](https://image.slidesharecdn.com/sseu-sparkinproduction-151029122932-lva1-app6891/85/Spark-Summit-EU-2015-Lessons-from-300-production-users-19-320.jpg)















The document outlines key lessons learned from over 100 production users of Spark at Databricks, focusing on performance challenges, optimizations, and common pitfalls in using Spark with Python and R. It emphasizes the importance of DataFrames for performance improvements and managing data efficiently, while addressing issues related to data processing and storage, particularly with S3. Additionally, it presents best practices for avoiding common mistakes, such as inappropriate use of RDD operations and the significance of join conditions in SQL.





























































































