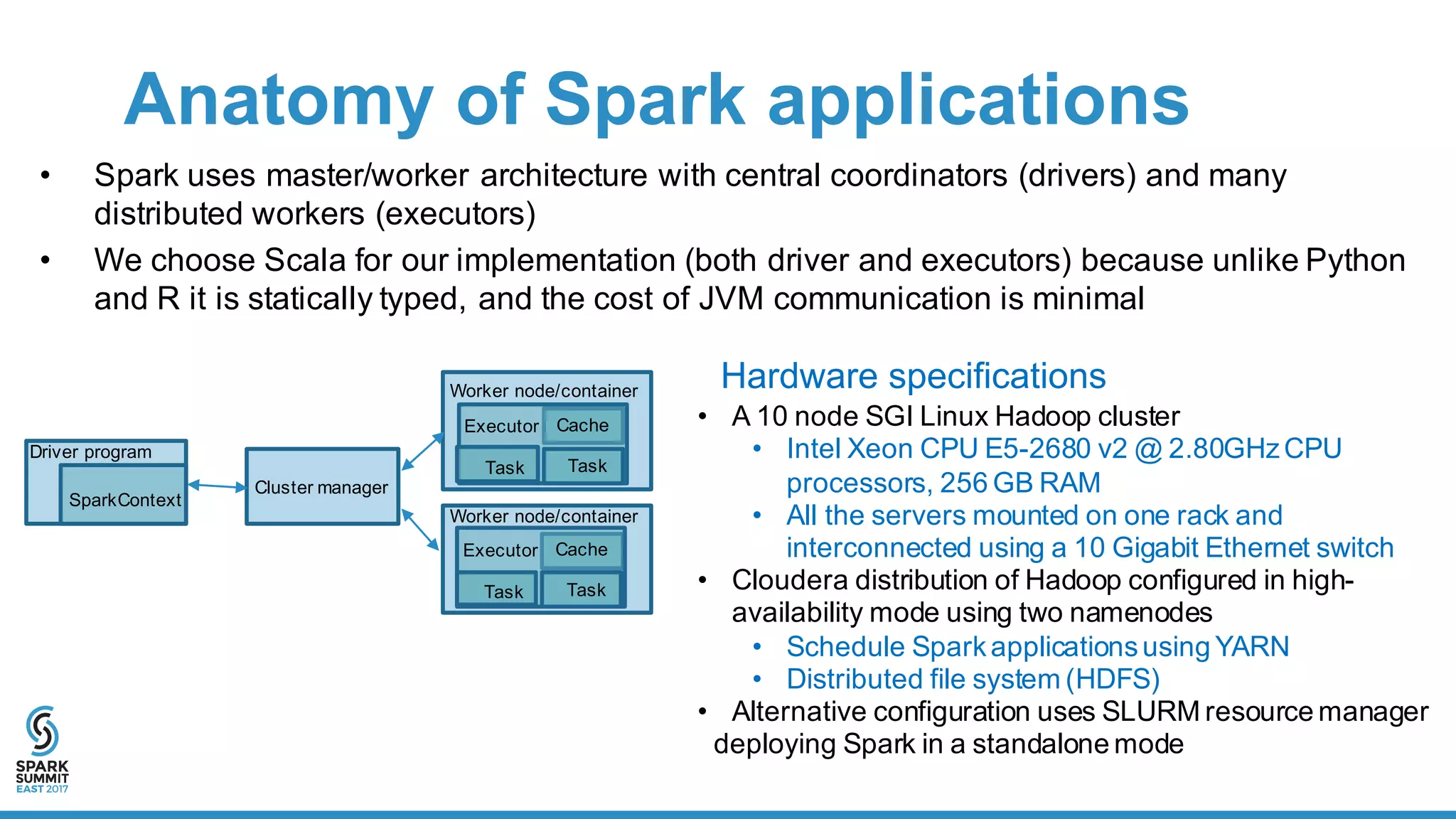
Downloaded 132 times









![Similarity measures
• The Jaccard similarity between two sets is the size of their intersection divided by the size
of their union:
J(𝐴, 𝐵) =
|-∩/|
|-∪/|
=
|-∩/|
- 1 / 2|-∩/|
– Key distance: consider feature vectors as sets of indices
– Hash distance: consider dense vector representations
• Cosine distance between feature vectors
C(A,B)=
(-6/)
|-|6|/|
– Convert distances to similarities assuming inverse proportionality,
rescaling it to [0,100] range, adding a regularization term
Feature type Similarity measure
Workflow1: K-means
clustering
Unigram, TF-IDF, truncated
SVD
Cosine, Euclidean
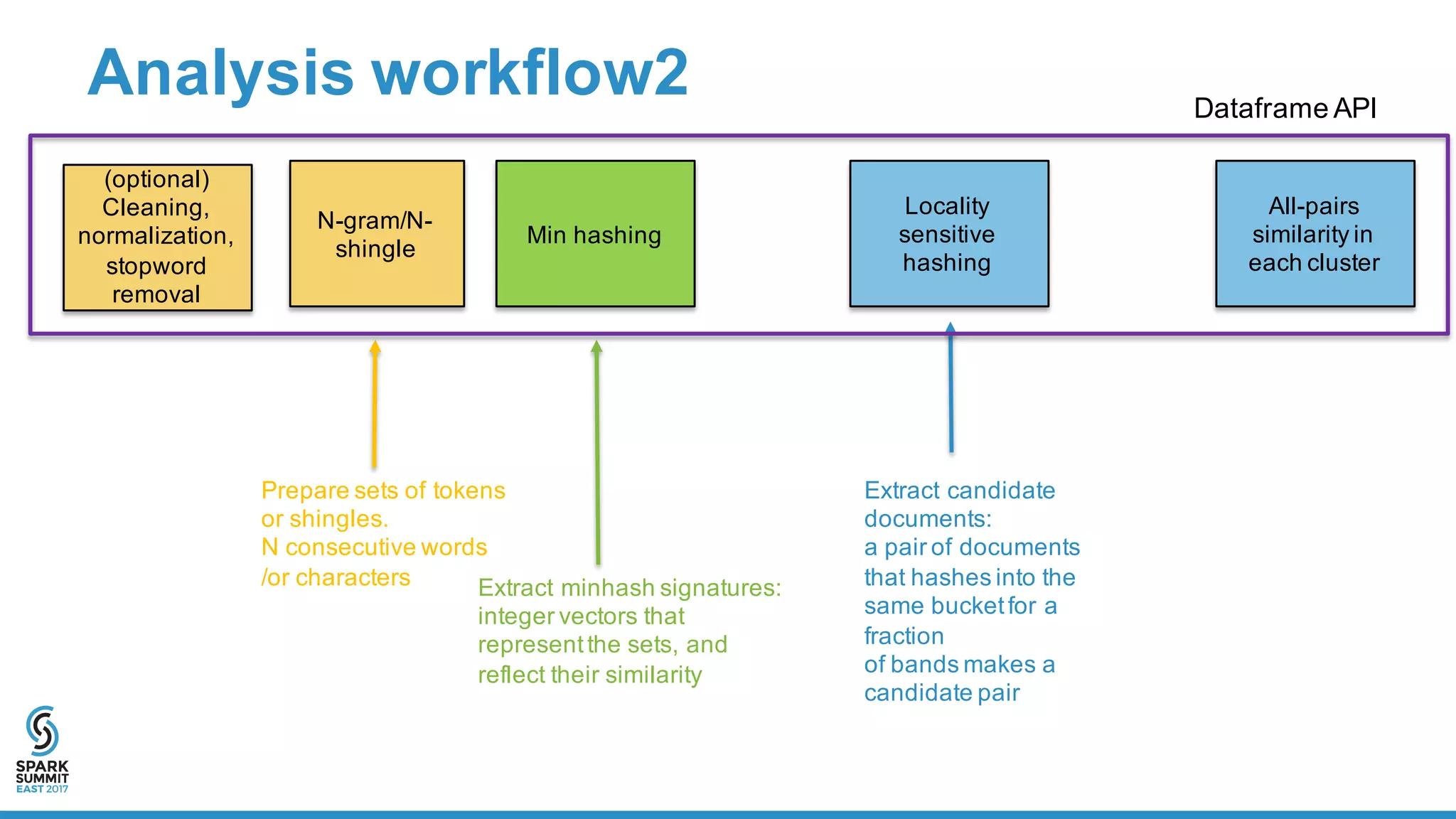
Workflow2: LSH N-gram with N=5, MinHash Jaccard
𝐴
𝐵](https://image.slidesharecdn.com/3312alexeysvyatkovskiy-170215225218/75/Large-Scale-Text-Processing-Pipeline-with-Spark-ML-and-GraphFrames-Spark-Summit-East-talk-by-Alexey-Svyatkovskiy-14-2048.jpg)








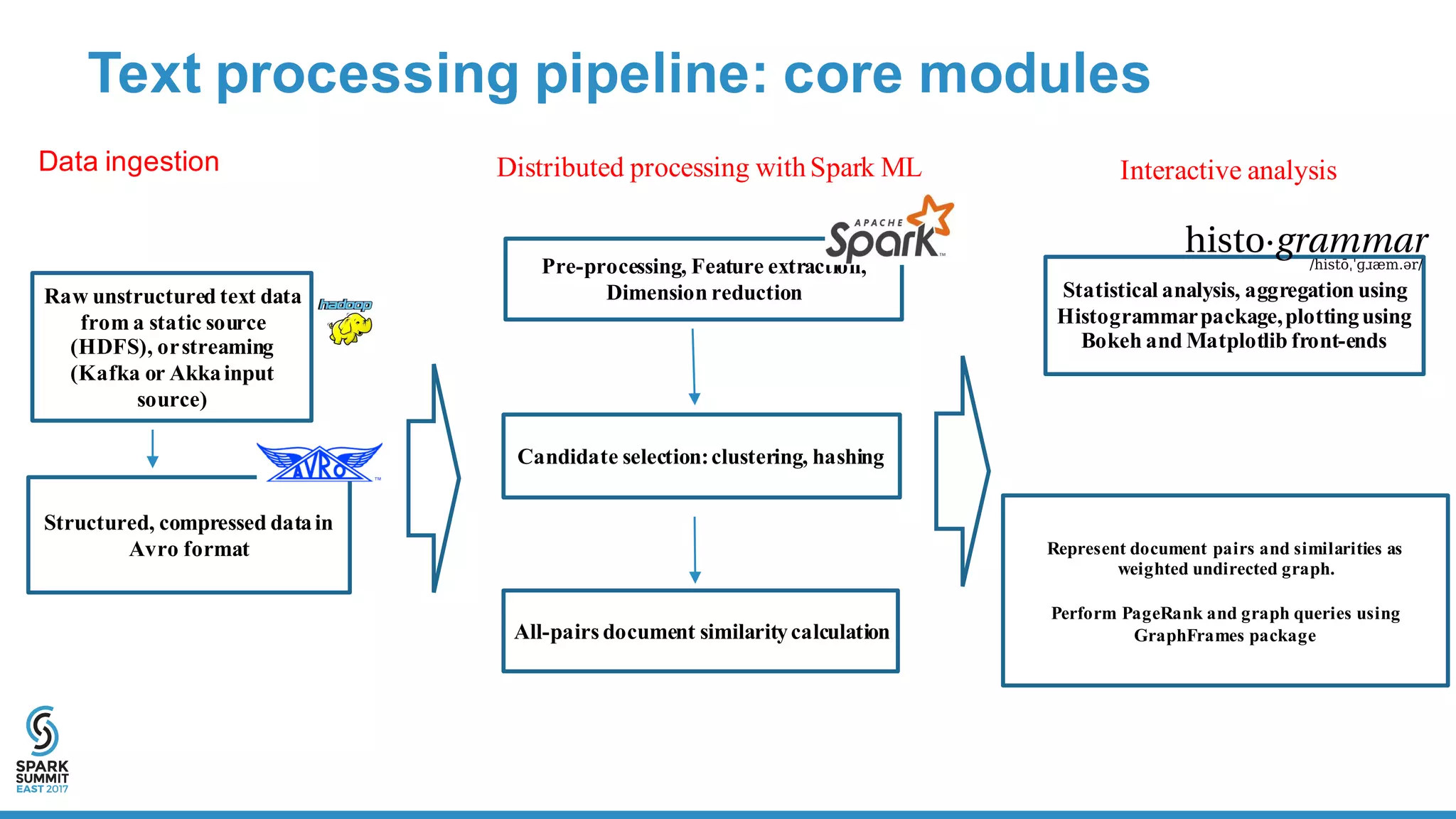
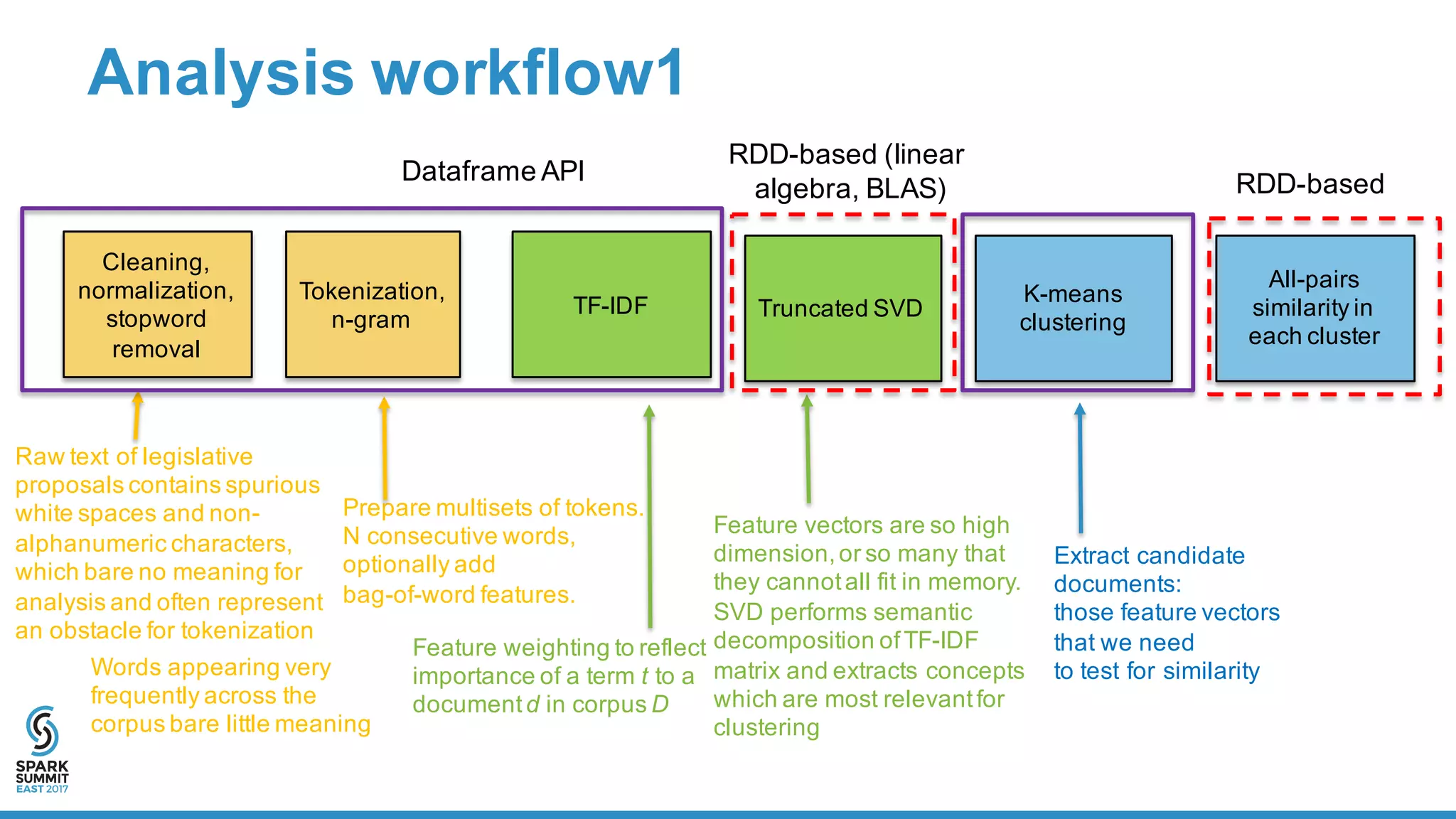
The document outlines a large-scale text processing pipeline utilizing Apache Spark and GraphFrames to address policy diffusion detection in U.S. legislatures. It details the methodologies applied for text processing, feature extraction, and all-pairs similarity calculations among legislative bills using techniques like clustering and locality sensitive hashing. The research aims to provide a scalable framework for analyzing similarities in bill texts and understanding the influences of policy diffusion across states.























































































