Downloaded 117 times







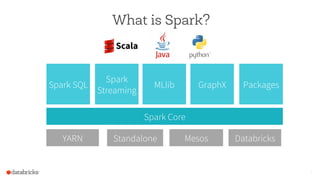
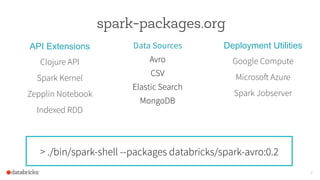

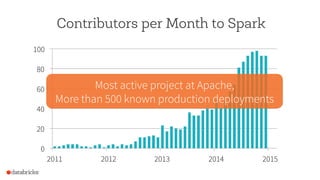

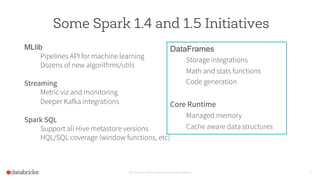


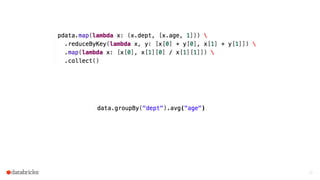





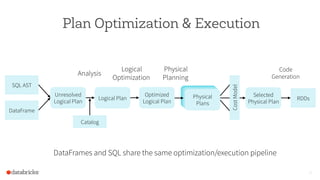

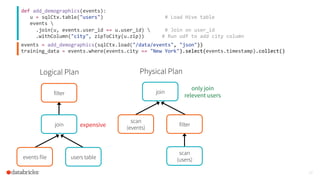
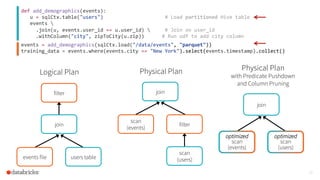
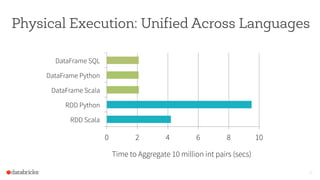

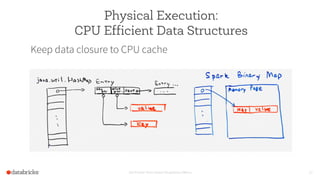
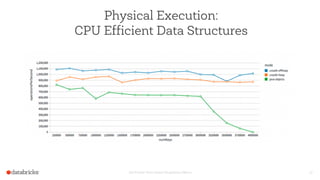

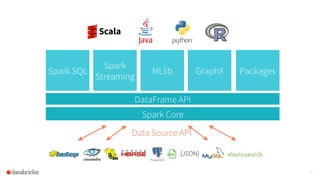



The document discusses the advancements and features of Apache Spark, highlighting its capabilities for big data processing with APIs in Python, Java, and Scala. New features in versions 1.4 and 1.5 include enhanced machine learning pipelines, dataframes for optimized data manipulation, and improved SQL support. The importance of Databricks as a key contributor to Spark and the ongoing commitment to an open-source platform is emphasized.























































































