Download to read offline




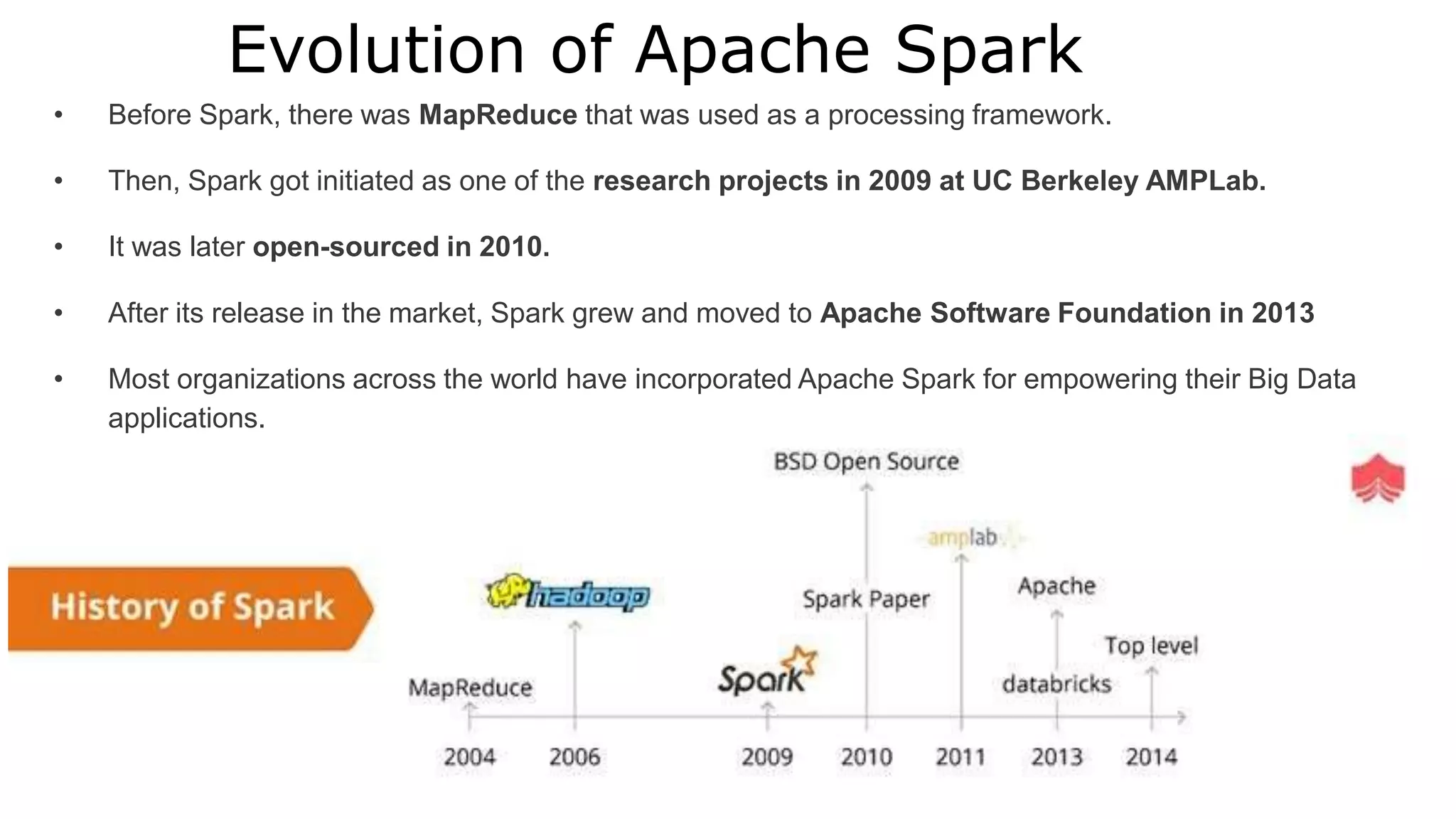
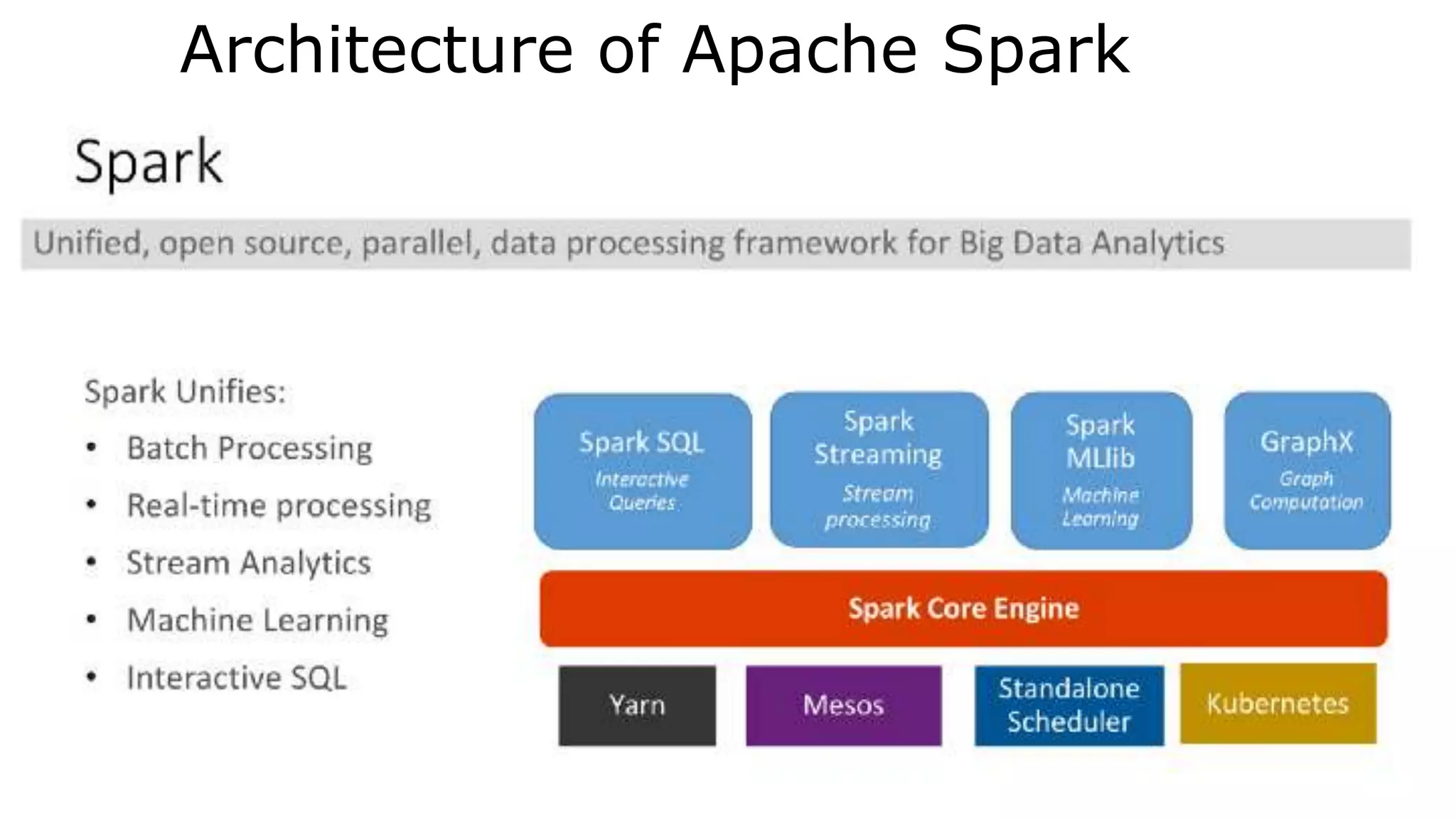





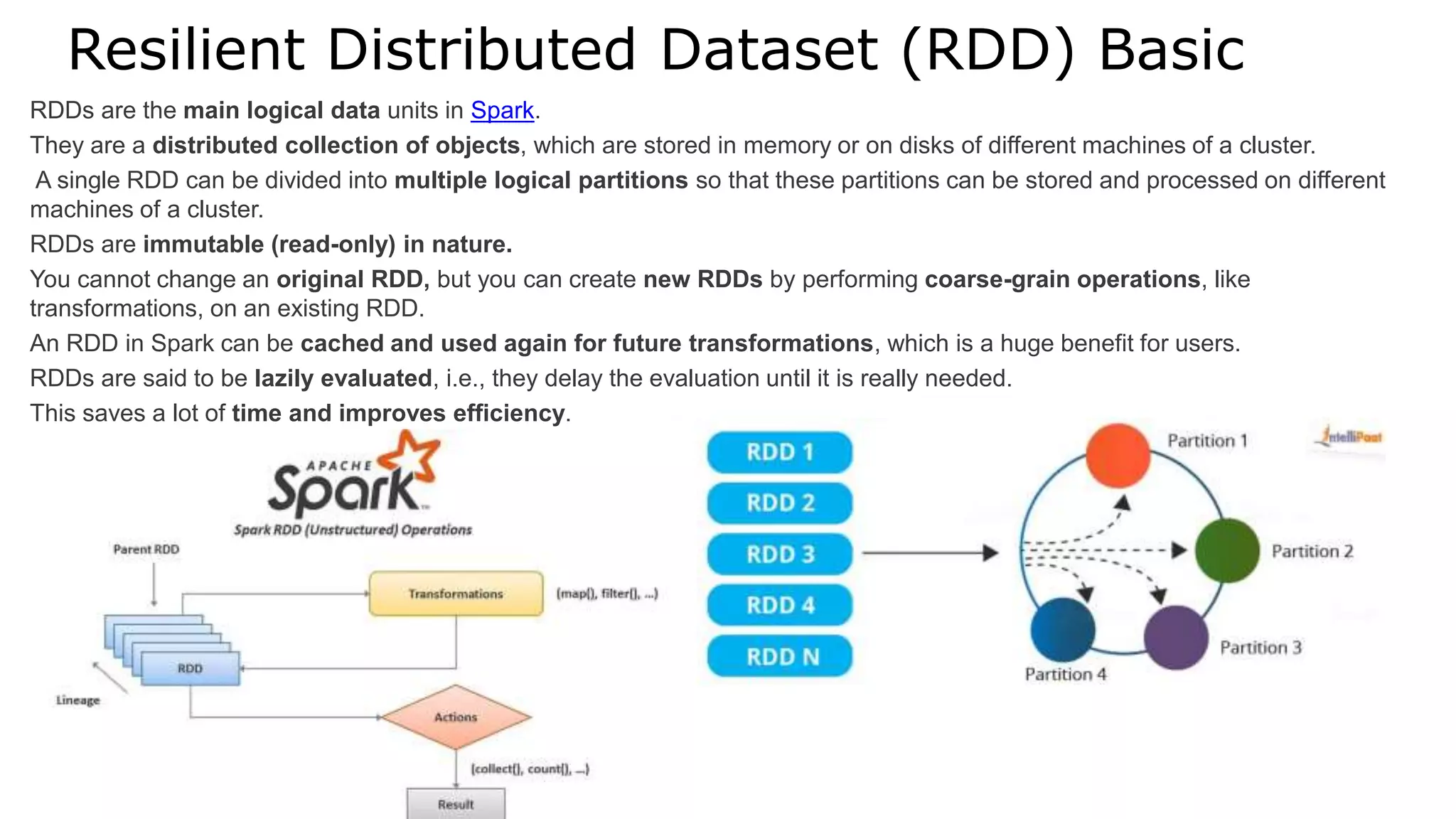
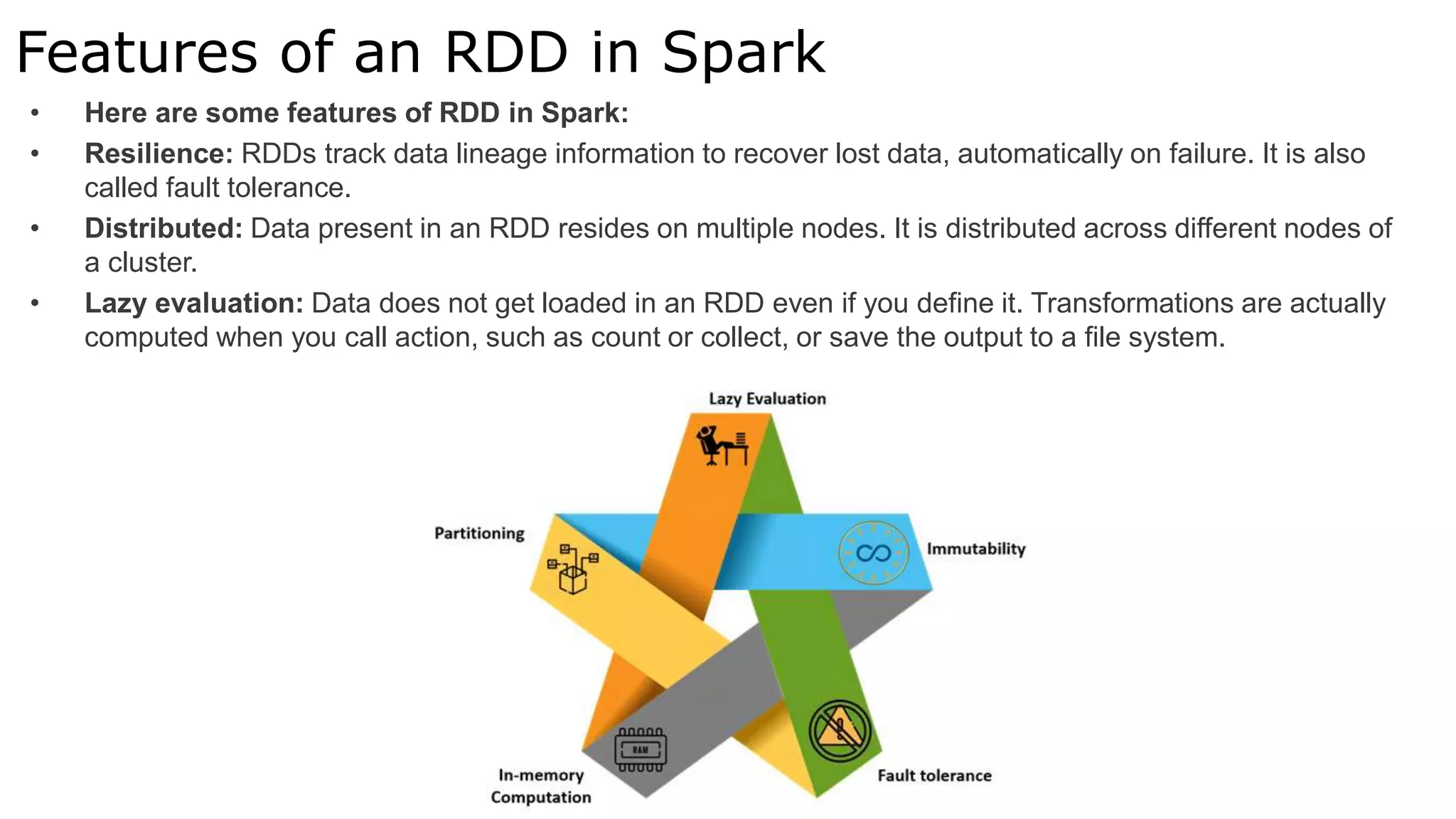



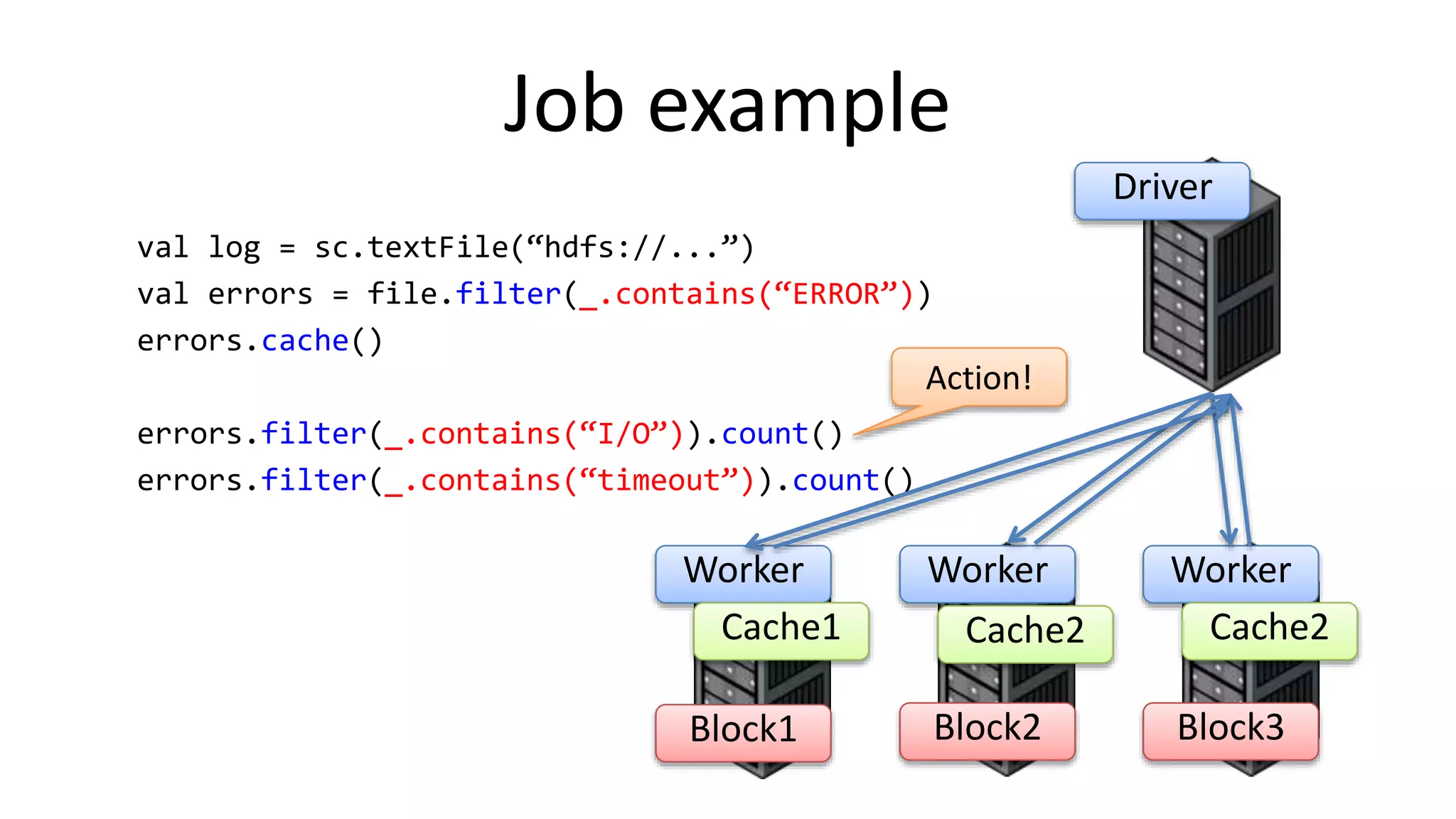
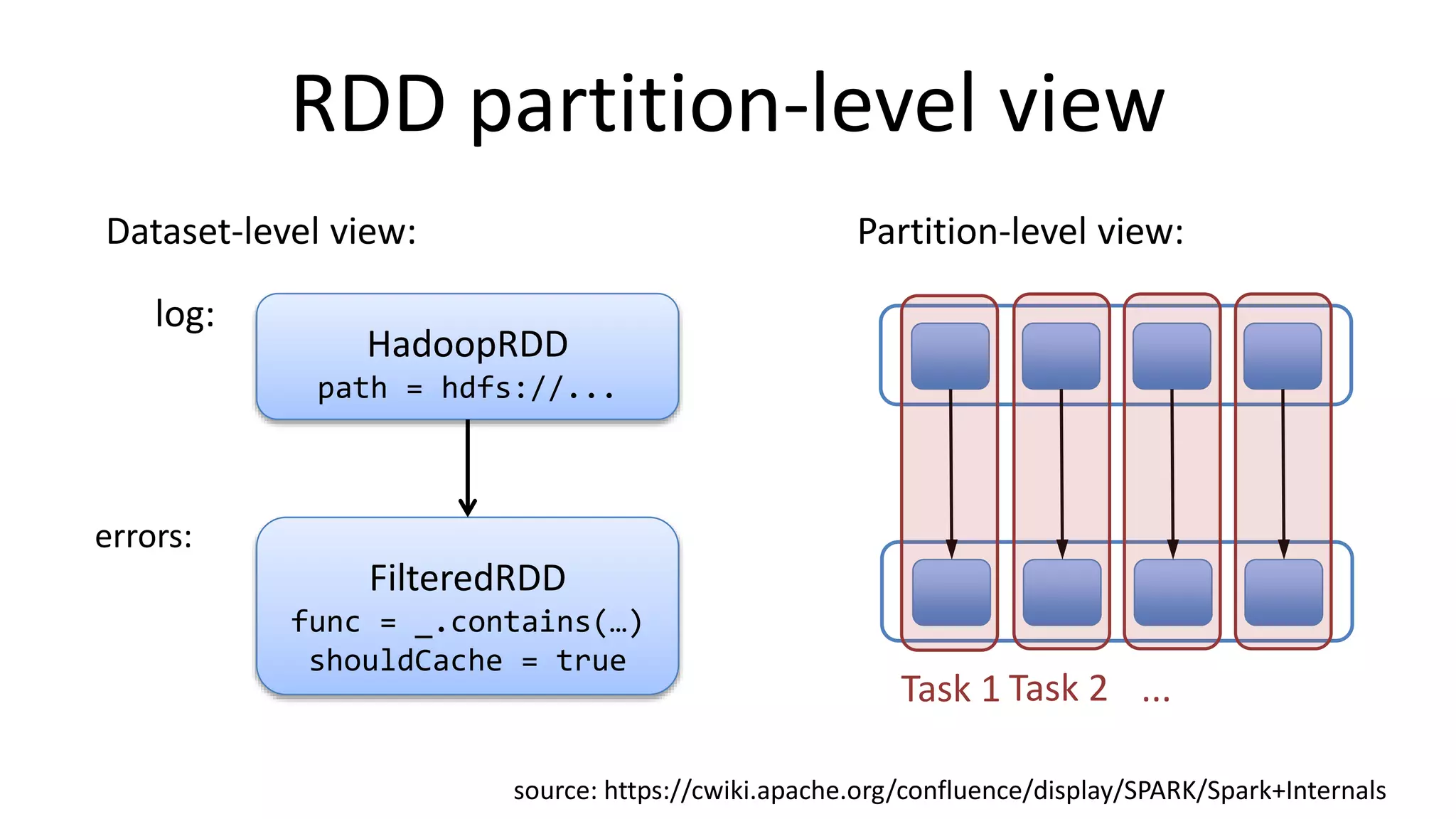
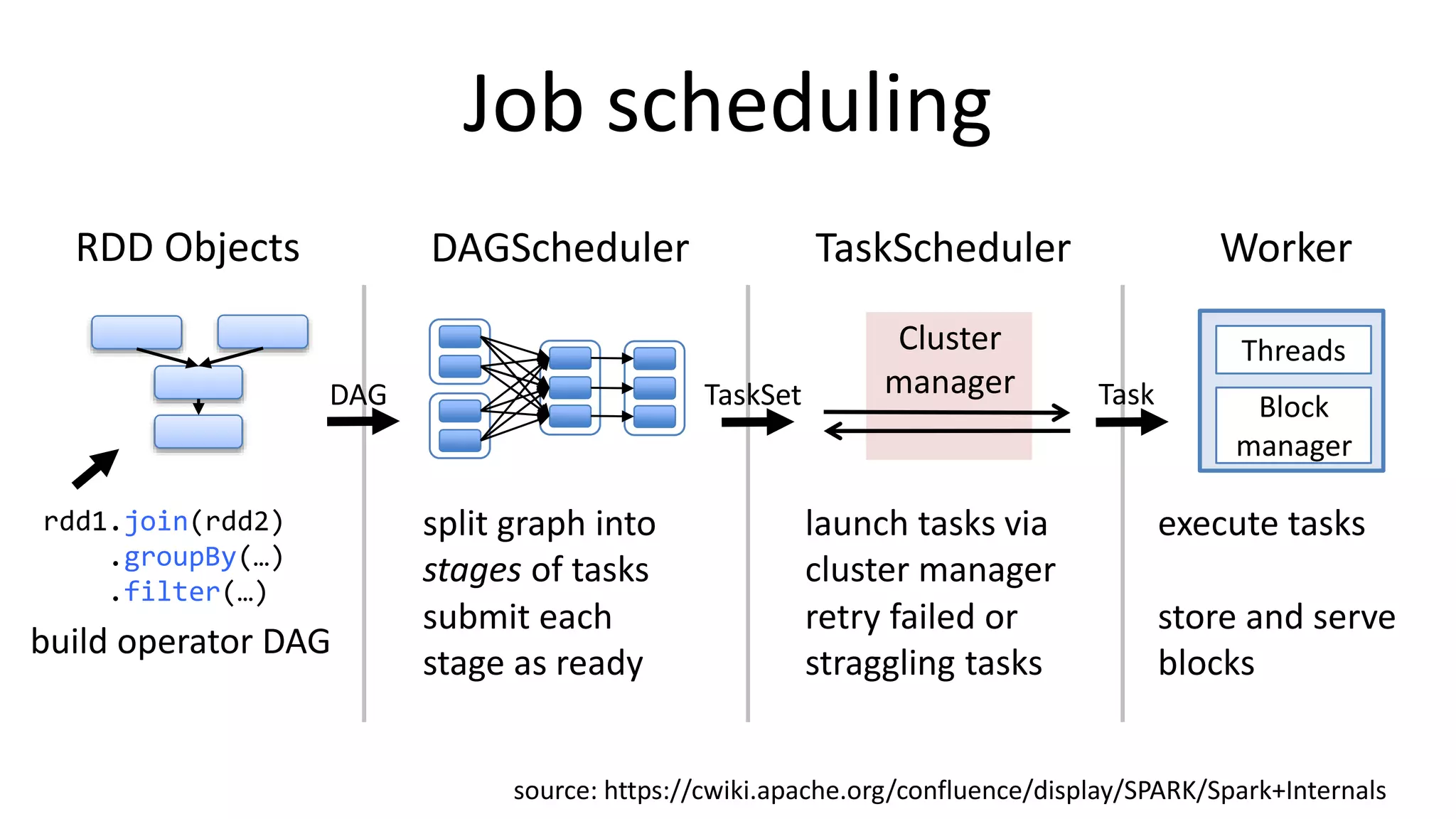





Apache Spark is a lightning-fast cluster computing framework designed for real-time processing. It overcomes limitations of Hadoop by running 100 times faster in memory and 10 times faster on disk. Spark uses resilient distributed datasets (RDDs) that allow data to be partitioned across clusters and cached in memory for faster processing.