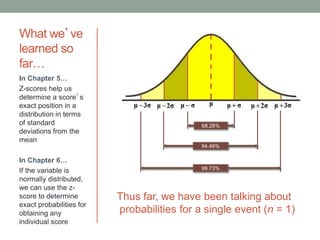
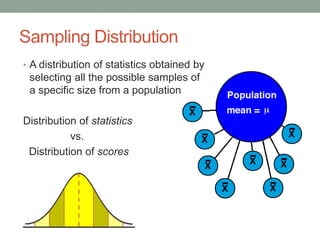
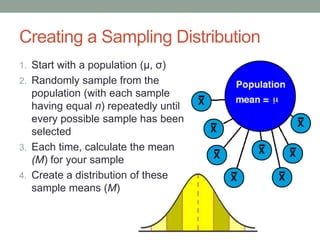
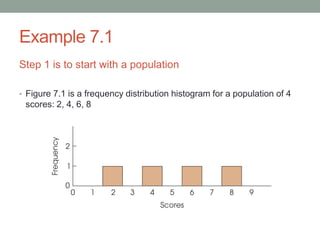
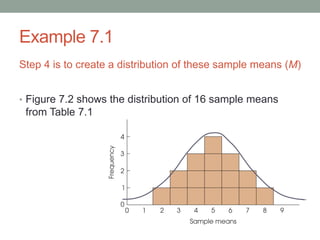
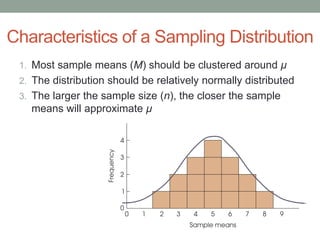
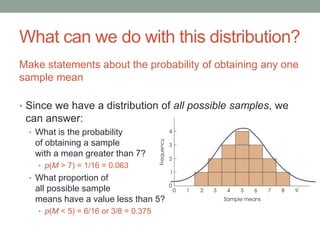
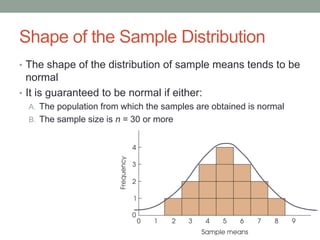
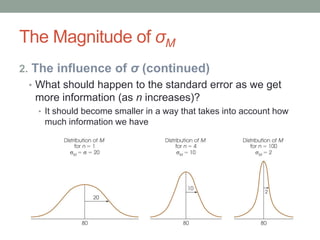
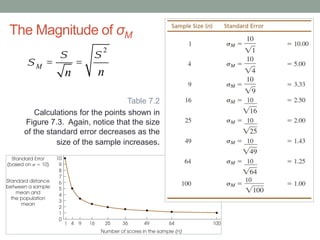
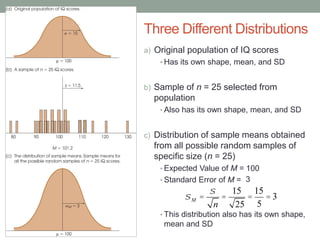
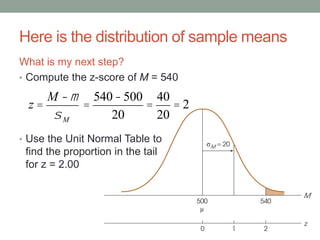
This document discusses the distribution of sample means and the central limit theorem. It begins by explaining how sampling distributions allow us to consider probabilities for groups of scores rather than single scores. It then discusses how the distribution of all possible sample means from a population follows a predictable pattern. Specifically, the central limit theorem states that the distribution of sample means will be normally distributed with a mean equal to the population mean and a standard deviation related to the sample size. This allows probabilities and z-scores to be calculated for sample means. The document provides examples to illustrate these concepts.