Downloaded 76 times





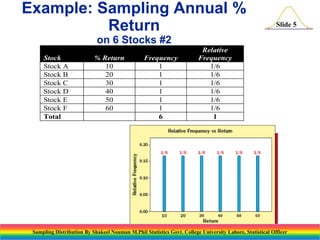


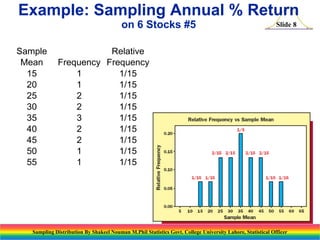






















This document, presented by Shakeel Nouman, discusses sampling distributions, particularly the sampling distribution of the sample mean and sample proportion. It provides examples of calculating sample means from stock returns and illustrates key principles such as the Central Limit Theorem and properties of sampling distributions. The document emphasizes that the sample mean is an unbiased estimate of the population mean and outlines the importance of sample size in achieving accurate estimates.








































































































