4/23
予測平均
T
1
0
( , )( ) ( )
M
j
j jy w f f
-
=
= =å x ww xx (3.3)
回帰関数
T
N Nb= S Φm t
パラメータの事後分布の平均
(3.53)
予測平均
T
1
T T T
( ) ( )( , )) ( )(N N N N n n
N
n
y tf bf bf f
=
= == åx x Φ xSxx m m S t (3.60)
5.
5/23
等価カーネル
予測平均
T
1
T T T
() ( )( , )) ( )(N N N N n n
N
n
y tf bf bf f
=
= == åx x Φ xSxx m m S t (3.60)
等価カーネル,平滑化行列
T
(( , ) ) ( )Nk bf f ¢=¢ x S xx x
データ集合の入力値に依存
目標変数の線形結合
6.
6/23
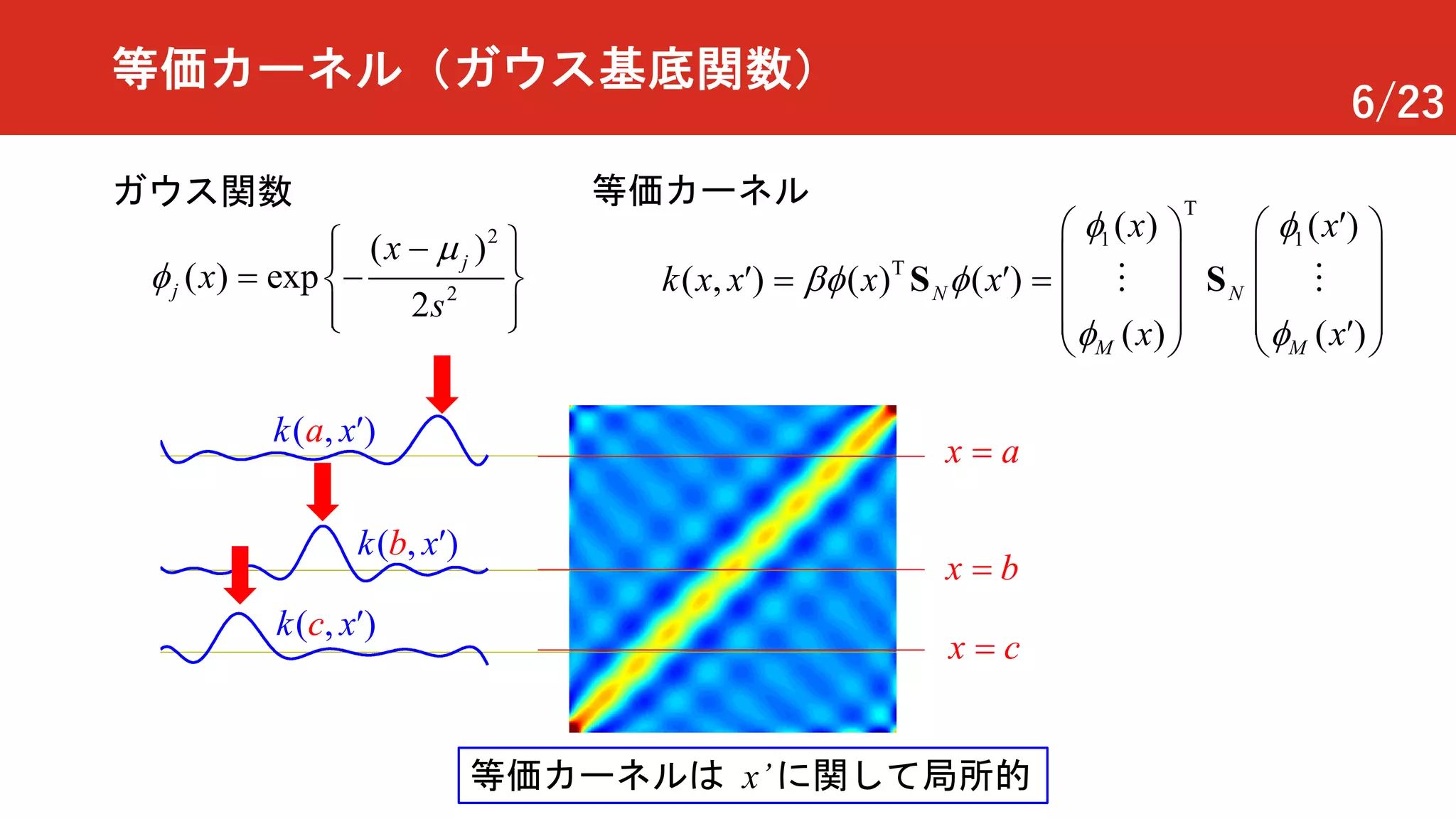
等価カーネル(ガウス基底関数)
2
2
( )
( )exp
2
j
j
x
x
s
µ
f
ì ü-ï ï
= -í ý
ï ïî þ
ガウス関数 等価カーネル T
1 1
T
( ) ( )
( , )
(
( ) ( )
) ( )
N N
M M
x x
k x x
x
x
x
x
f f
bf f
f f
¢æ ö æ ö
ç ÷ ç ÷
¢ ¢ = ç ÷ ç ÷
ç ÷ ç ÷¢è è
=
ø ø
SS ! !
( , )k a x¢
( , )k b x¢
( , )k c x¢
x a=
x c=
x b=
等価カーネルは x’に関して局所的
8/23
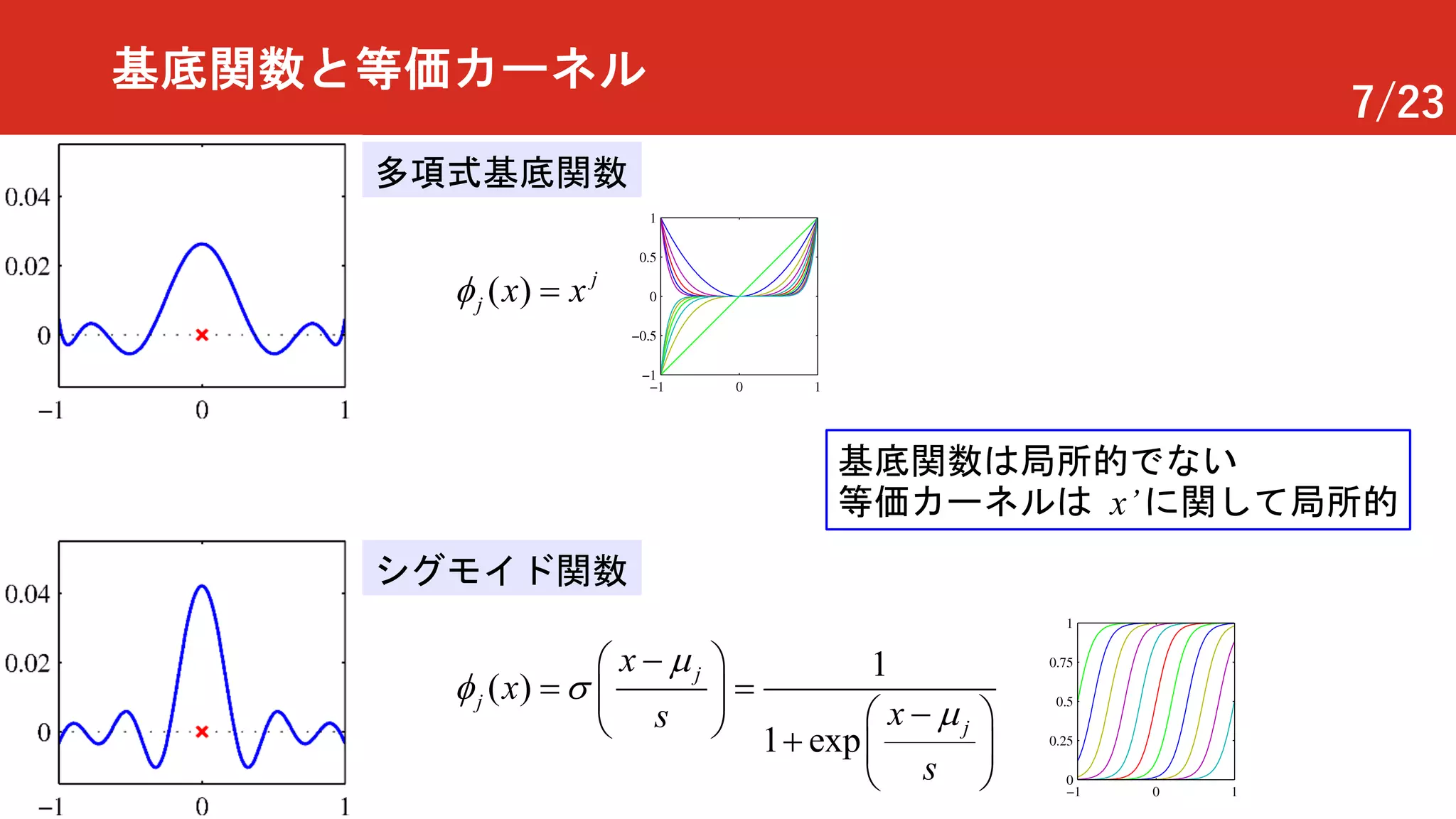
注意:ガウス基底関数とガウスカーネル
2
2
( )
( )exp
2
j
j
x
x
s
µ
f
ì ü-ï ï
= -í ý
ï ïî þ
ガウス基底関数
2
2
) ex( p,
2
k
s
æ ö- ¢
ç ÷¢ = -
ç ÷
è ø
x x
x x
ガウスカーネル
9.
9/23
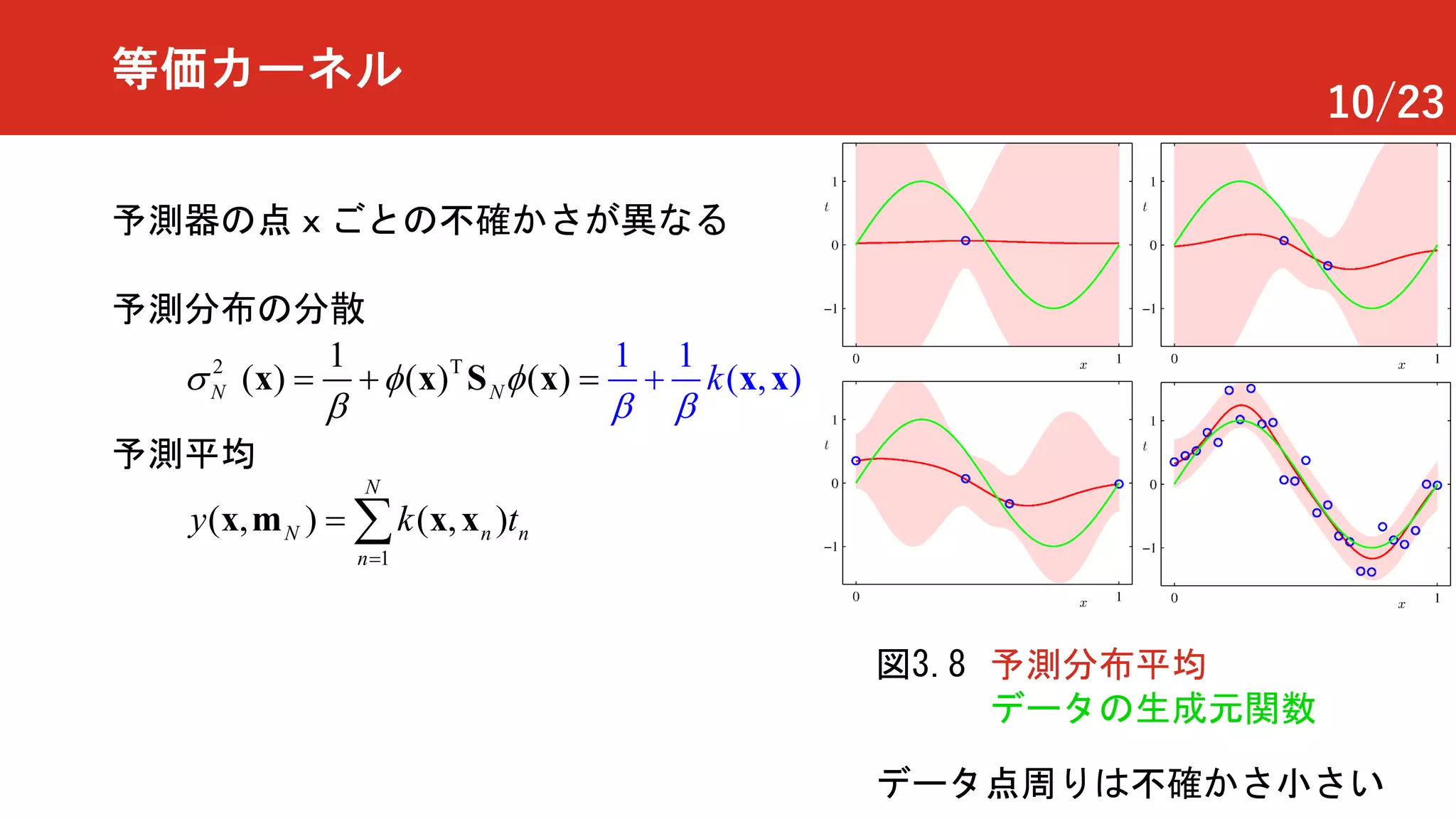
異なる 𝒙の値における予測値同士の共分散
[ ]T T
T 1
( ), ( ) ( ) , ( )
( ) (
cov c v
),)
o
(N k
y y f f
f f b -
é¢ ¢
=
ù= ë
= ¢ ¢
ûw w
S x
x x
x x x
x x
(3.63)
等価カーネルノイズの仮定
近傍点での予測平均は強い相関
離れた点での予測平均の相関は小さい
16/23
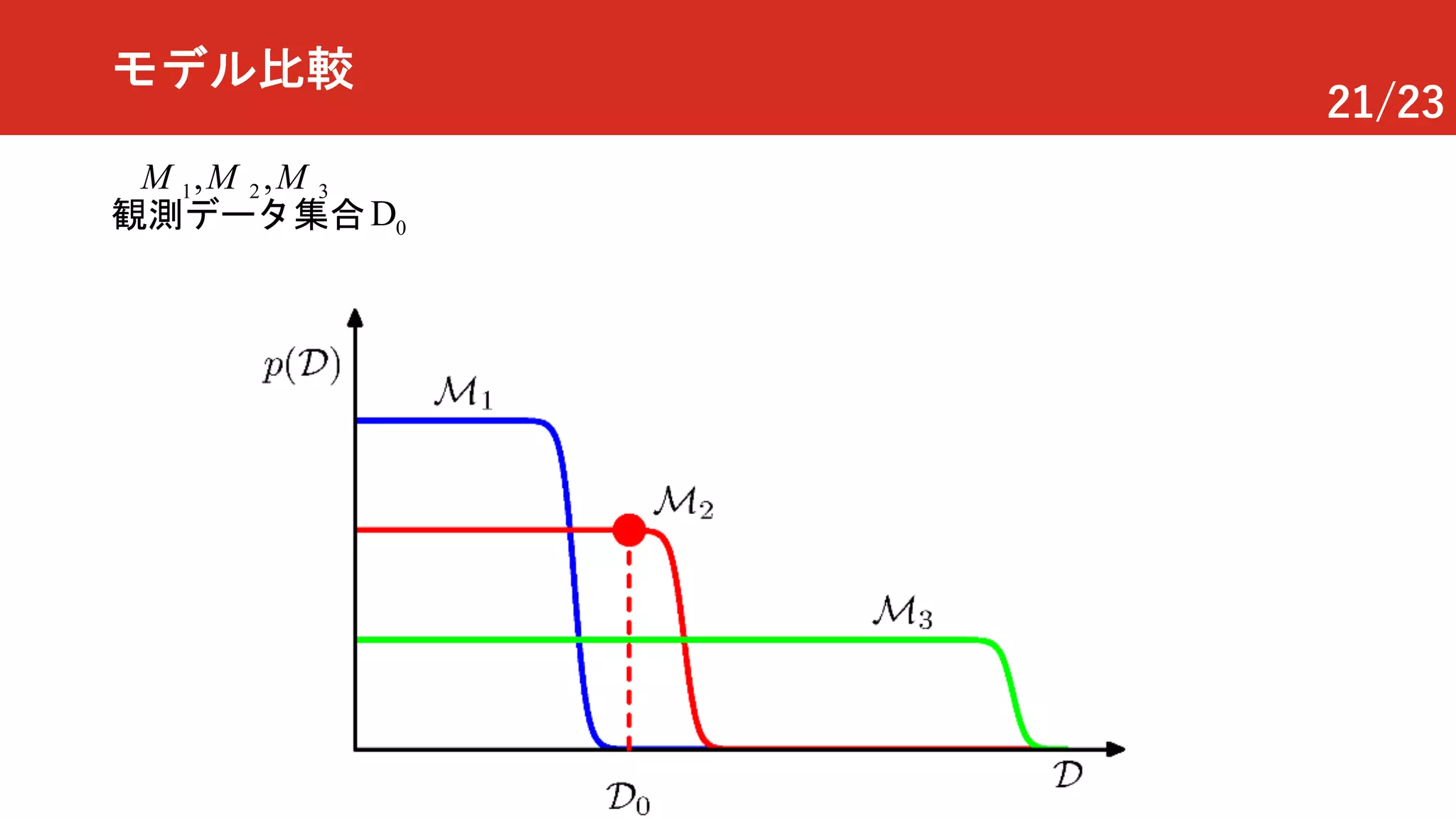
モデル比較
L個のモデルを比較
{ }( 1,),i i L= …M
モデルはD上の確率分布
( | ) ( ) ( | )i i ip p pµD DM M M
モデルエビデンス / 周辺尤度モデルの事前分布
モデルの事後分布
データ集合 はどれかから生成された
どのモデルからかはわからない
D
17.
17/23
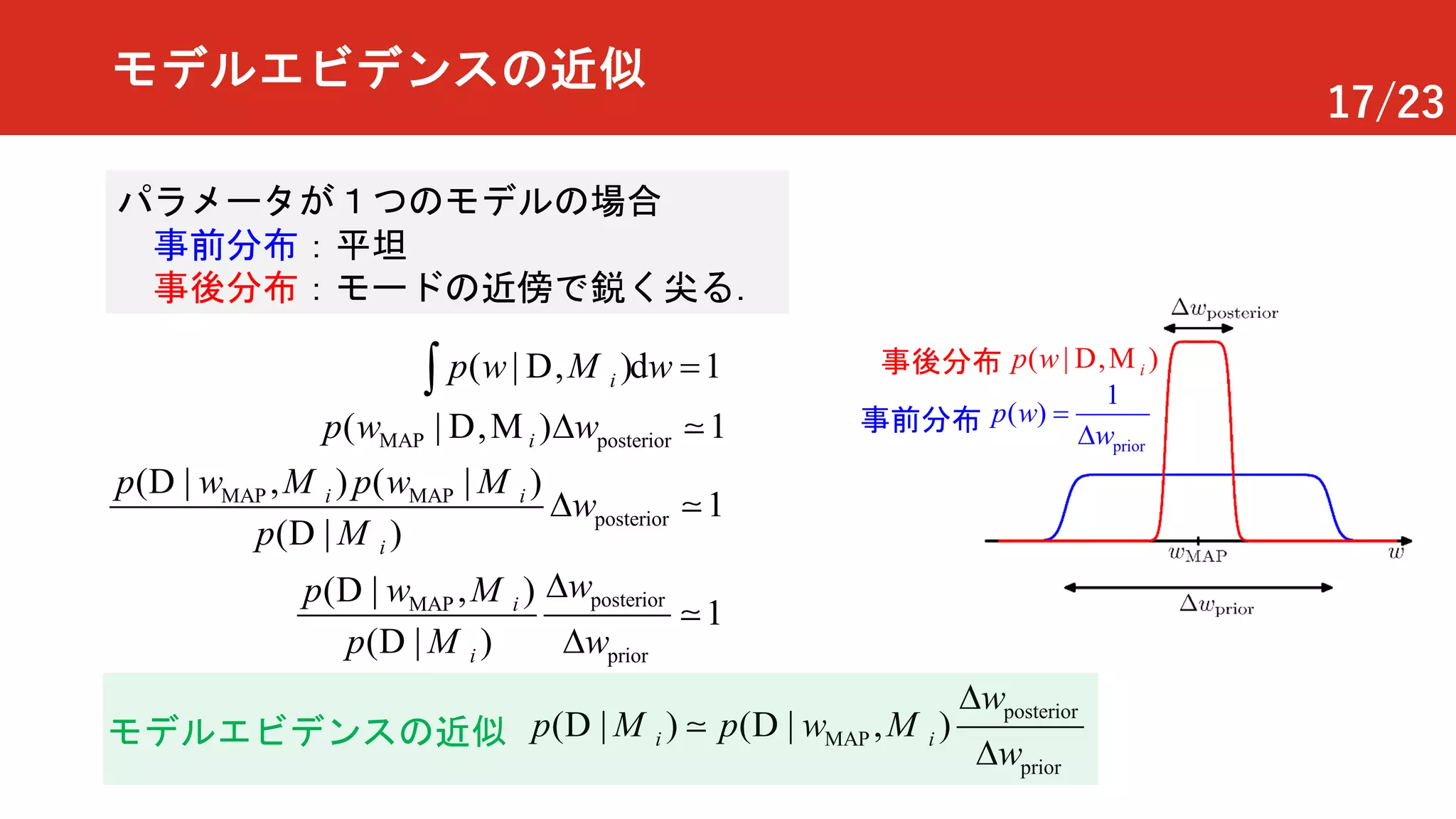
モデルエビデンスの近似
( | ,)d 1ip w w =ò D M
MAP posterior( , )| 1ip w wDD M !
MAP MAP
posterior
( | , ) ( | )
1
( | )
i i
i
p pw w
w
p
D
D
D
!
M M
M
posteriorMAP
prior
( | , )
1
( | )
i
i
p ww
p w
D
D
D
D
!
M
M
posterior
MAP
prior
( | ) ( | , )i i
w
w
p wp
D
D
D D!M Mモデルエビデンスの近似
( | , )ip w D M
prior
1
( )p w
w
=
D事前分布
事後分布
パラメータが1つのモデルの場合
事前分布:平坦
事後分布:モードの近傍で鋭く尖る.
18.
18/23
モデルエビデンスの解釈
posterior
pri
M
or
AP nln (| ) ln l( | , )ii p
w
w
wp
æ öD
ç ÷ç ÷D
+
è ø
D D! MM
第1項
Ø データへのフィッティング度
Ø データDが生成される確率(尤度)
第2項
Ø モデルの複雑さへのペナルティ
Ø 負 posterior priorw wD<D
モデルがデータに強くフィット
ペナルティ大
パラメータが1つのモデルの場合
19.
19/23
モデルエビデンスの解釈
posterior
pri
A
or
M P lnln( | ) ln ( | , )iip
w
M
w
p
æ öD
ç ÷ç ÷D ø
+
è
wD D!M M
パラメータがM個のモデルの場合
エビデンス最大にするモデルは,
相反する項をバランスよく小さくする.
パラメータ数Mが多い
Ø フィッティング度 +大
Ø ペナルティ -大
パラメータ数Mが少ない
Ø フィッティング度 +小
Ø ペナルティ -小
今回のモデルエビデンスの近似は大雑把 => 4.4.1節 ガウス近似法
22/23
期待ベイズ因子
1
1
2
( | )
(| )l
|
dn
( )
p
p
pò
D
DD
D
M
M
M
2つのモデルの比較
1M真のモデル
1 2,M M
有限のデータ集合では,正しくないモデルが選ばれる可能性 => 期待値
( | )
( | )
i
j
p
p
D
D
M
M
ベイズ因子
1 2
2 1
( | ) ( | )
( | ) ( | )
p p
p p
>
D D
D D
M M
M M
ベイズ因子が大きいほうが真のモデル
データ集合 D
カルバック-ライブラーダイバージェンス
( )
( || ) ( )l dn
( )
q
KL p q p
p
= -ò
x
x
x
x

![2/23
本日の内容
- 3.3.3 等価カーネル [pp.156-159]
- 3.4 ベイズモデル比較 [pp.160-164]](https://image.slidesharecdn.com/prml-3-190714163820/75/PRML-3-3-3-3-4-Baysian-Linear-Regression-and-Model-Comparison-2-2048.jpg)




![9/23
異なる 𝒙の値における予測値同士の共分散
[ ] T T
T 1
( ), ( ) ( ) , ( )
( ) (
cov c v
),)
o
(N k
y y f f
f f b -
é¢ ¢
=
ù= ë
= ¢ ¢
ûw w
S x
x x
x x x
x x
(3.63)
等価カーネルノイズの仮定
近傍点での予測平均は強い相関
離れた点での予測平均の相関は小さい](https://image.slidesharecdn.com/prml-3-190714163820/75/PRML-3-3-3-3-4-Baysian-Linear-Regression-and-Model-Comparison-9-2048.jpg)

![12/23
等価カーネル
等価カーネルは重みを定める役割
重み付きのデータ集合の目標値の和 = 予測値
ある仮定の下ですべての x の値に対して1になる
1
( 1, )
N
n
n
k
=
=å x x
凸結合:和が1となるような非負係数を持つ点の線形結合 [Wikipedia]
1
( , )( , )N n
N
n
n
y tk
=
= å x xx m
目標変数の凸結合になるとは限らない
パラメータ事前分布の分散無限
基底関数は線形独立](https://image.slidesharecdn.com/prml-3-190714163820/75/PRML-3-3-3-3-4-Baysian-Linear-Regression-and-Model-Comparison-12-2048.jpg)

































![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)



















