T
σ (w φ) は、φ上への射影を通してのみwに依存する
T
a = w φ と表すと σ (w φ ) は次の通り
T
wTφは常にセット、他との組み合わせでは登場しないので
a
とおける
T T
σ (w φ ) = ∫ δ (a − w φ )σ (a)da
ディラックのデルタ関数(計算に便利)
14.
よって
p(C1 |φ, t) = ∫ p(C1 | φ, w)p(w | t)dw
T
≈ ∫ σ (w φ )q(w)dw
T
= ∫ ( ∫ σ (a − w φ )σ (a)q(w)da )dw
T
= ∫ ( ∫ σ (a − w φ )q(w)dw)σ (a)da
= ∫ p(a)σ (a)da
T
ここで
p(a) = ∫ δ (a − w φ )q(w)dw
15.
平均
µ a= E[a] = ∫ p(a)a da
T
= ∫ ∫ δ (a − w φ )q(w)a dw da
T
= ∫ ( ∫ δ (a − w φ )a da )q(w)dw
T
= ∫ q(w)w φ dw
T
= ( ∫ q(w)w dw) φ
T T
= E[w] φ = w φ
MAP
16.
共分散
2
σ a = var[a] = ∫ p(a){a 2 − Ε[a]2 }da
T
4.146で
a=w φ
T
4.148で
p(a) = ∫ δ (a − w φ )q(w)dw をあてはめて
T 2 T 2
= ∫ q(w){(w φ ) − (m φ ) }dw
N
T
= φ S N φ












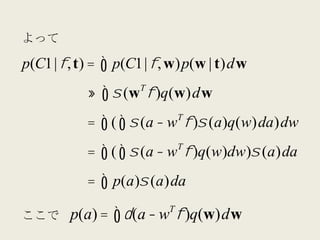
![平均
µ a = E[a] = ∫ p(a)a da
T
= ∫ ∫ δ (a − w φ )q(w)a dw da
T
= ∫ ( ∫ δ (a − w φ )a da )q(w)dw
T
= ∫ q(w)w φ dw
T
= ( ∫ q(w)w dw) φ
T T
= E[w] φ = w φ
MAP](https://image.slidesharecdn.com/prml-130126122627-phpapp01/85/PRML-15-320.jpg)
![共分散
2
σ a = var[a] = ∫ p(a){a 2 − Ε[a]2 }da
T
4.146で
a=w φ
T
4.148で
p(a) = ∫ δ (a − w φ )q(w)dw をあてはめて
T 2 T 2
= ∫ q(w){(w φ ) − (m φ ) }dw
N
T
= φ S N φ](https://image.slidesharecdn.com/prml-130126122627-phpapp01/85/PRML-16-320.jpg)


















![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)




















































