線形基底関数における対数尤度関数の最
大化
前式の尤度関数
p(t∣X, w, β)= N(t ∣w ϕ(x ), β )
wに関して最大化したものを0とおいて解く
∇ ln p(t∣w, β) = β t −w ϕ(x ) ϕ(x ) = 0
ただし、E (w) = t −w ϕ(x ) を誤差関数とし
て定義する
n=1
∏
N
n
⊤
n
−1
n=1
∑
N
{ n
⊤
n } n
⊤
D 2
1
∑n=1
N { n
⊤
n }2
11
12.
計画行列
最小二乗問題の正規方程式
w = (ΦΦ) Φ t
N × M 行列 Φ を計画行列と呼ぶ
Φ =
ML
⊤ −1 ⊤
⎝
⎜
⎜
⎛ϕ (x )0 1
ϕ (x )0 2
⋮
ϕ (x )0 N
ϕ (x )1 1
ϕ (x )1 2
⋮
ϕ (x )1 N
⋯
⋯
⋱
⋯
ϕ (x )M−1 1
ϕ (x )M−1 2
⋮
ϕ (x )M−1 N
⎠
⎟
⎟
⎞
12
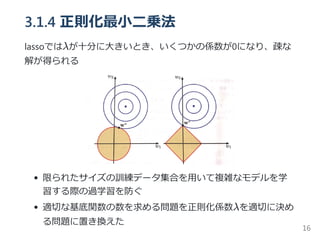
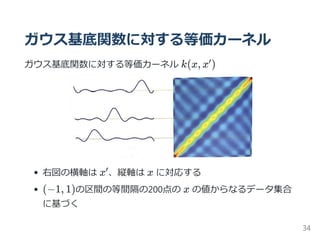
3.3.3 等価カーネル
線形基底関数モデルのパラメータ wを最適化したモデルを導出す
ることを考える
y(x, w) =w ϕ(x)
w =m =S (S m + βΦ t)
上二式から、式導出
y(x,m ) =m ϕ(x) = βϕ(x) S ϕ(x )t = k(x,x )t
ここで、等価カーネル k(x,x ) を次式で定義する
k(x,x ) = βϕ(x) S ϕ(x )
⊤
MAP N N 0
−1
0
⊤
N N
⊤ ⊤
N n n n n
′
′ ⊤
N
′
33










![ムーア・ペンローズの擬似逆行列
行列 Φ を行列 Φ のムーア・ペンローズの逆擬似行列と呼ぶ
Φ = (Φ Φ) Φ
一般の逆行列の概念の非正方行列への拡張
逆行列を持たない行列であっても近似的な解を導出可能
[参考] 大人になってからの再学習 一般逆行列・ムーア・ペンロー
ズ逆行列 http://zellij.hatenablog.com/entry/20120811/p1
†
† ⊤ −1 ⊤
13](https://image.slidesharecdn.com/prmlchapter3-171003081954/85/PRML-3-13-320.jpg)




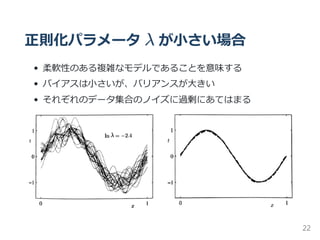
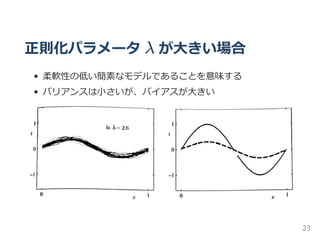
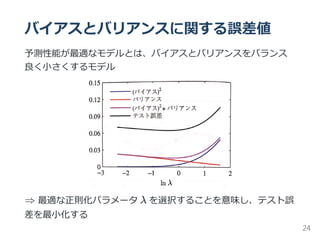
![期待二乗損失の詳細
前式を分解
E(L) = (Bias) + variance + Noise
ただし、
(Bias) = E [y(x; D)] − h(x) p(x)dx
variance = E y(x; D) −E [y(x; D) p(x)dx
noise = h(x) − t p(x, t)dxdt
2
2
∫ { D }2
∫ D[{ D }]
∫ ∫ { }2
20](https://image.slidesharecdn.com/prmlchapter3-171003081954/85/PRML-3-20-320.jpg)





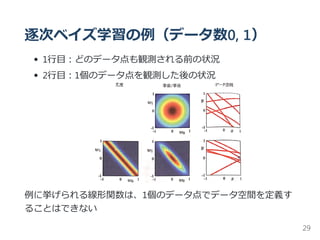
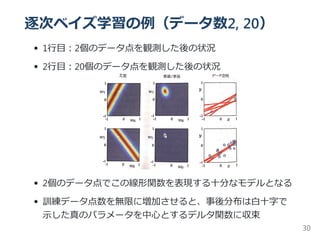



![等価カーネルの役目
y(x) と y(x ) の共分散を導出(確率分布 p は共分散の計算時に
使用)
p(w∣t) = N(w∣m ,S )
k(x,x ) = βϕ(x) S ϕ(x )
上二式から、
cov y(x), y(x ) = cov[ϕ(x) w,w ϕ(x )] = ϕ(x) S ϕ(x )
= β k(x,x )
⇒ 近傍点での予測平均は互いに強い相関を持ち、より離れた点の
組では相関は小さくなる
′
N N
′ ⊤
N
′
[ ′
] ⊤ ⊤ ′ ⊤
N
′
−1 ′
35](https://image.slidesharecdn.com/prmlchapter3-171003081954/85/PRML-3-35-320.jpg)




















































![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)




