Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
sakaguchi050403
232 views
PRML セミナー
セミナー資料
Data & Analytics
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 73
2
/ 73
3
/ 73
4
/ 73
5
/ 73
6
/ 73
7
/ 73
8
/ 73
9
/ 73
10
/ 73
11
/ 73
12
/ 73
13
/ 73
14
/ 73
15
/ 73
16
/ 73
17
/ 73
18
/ 73
19
/ 73
20
/ 73
21
/ 73
22
/ 73
23
/ 73
24
/ 73
25
/ 73
26
/ 73
27
/ 73
28
/ 73
29
/ 73
30
/ 73
31
/ 73
32
/ 73
33
/ 73
34
/ 73
35
/ 73
36
/ 73
37
/ 73
38
/ 73
39
/ 73
40
/ 73
41
/ 73
42
/ 73
43
/ 73
44
/ 73
45
/ 73
46
/ 73
47
/ 73
48
/ 73
49
/ 73
50
/ 73
51
/ 73
52
/ 73
53
/ 73
54
/ 73
55
/ 73
56
/ 73
57
/ 73
58
/ 73
59
/ 73
60
/ 73
61
/ 73
62
/ 73
63
/ 73
64
/ 73
65
/ 73
66
/ 73
67
/ 73
68
/ 73
69
/ 73
70
/ 73
71
/ 73
72
/ 73
73
/ 73
More Related Content
PDF
PRML 第4章
by
Akira Miyazawa
PDF
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
PDF
[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)
by
Itaru Otomaru
PDF
Re revenge chap03-1
by
裕樹 奥田
PDF
回帰
by
Shin Asakawa
PDF
Linera lgebra
by
Shin Asakawa
KEY
prml4.1.3-4.1.4
by
Ryo Yamashita
PDF
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
PRML 第4章
by
Akira Miyazawa
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)
by
Itaru Otomaru
Re revenge chap03-1
by
裕樹 奥田
回帰
by
Shin Asakawa
Linera lgebra
by
Shin Asakawa
prml4.1.3-4.1.4
by
Ryo Yamashita
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
What's hot
PDF
PRML 第14章
by
Akira Miyazawa
PPTX
ラビットチャレンジレポート 応用数学
by
ssuserf4860b
PDF
スペクトラル・クラスタリング
by
Akira Miyazawa
PPTX
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
PDF
Prml 4.3.5
by
Satoshi Kawamoto
PDF
PRML chapter7
by
Takahiro (Poly) Horikawa
PDF
Prml 2.3
by
Yuuki Saitoh
PDF
第4回MachineLearningのための数学塾資料(浅川)
by
Shin Asakawa
PDF
卒論プレゼンテーション -DRAFT-
by
Tomoshige Nakamura
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
20140512_水曜セミナードラフトv1
by
Tomoshige Nakamura
PDF
2014年5月14日_水曜セミナー発表内容_FINAL
by
Tomoshige Nakamura
PDF
主成分分析
by
貴之 八木
PPTX
PRML2.3.1-2.3.3
by
とっきー Ishikawa
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
Prml 4.1.1
by
Satoshi Kawamoto
PDF
PRML 2.3節
by
Rei Takami
PDF
2015年度秋学期 応用数学(解析) 第6回 変数分離形の変形 (2015. 11. 5)
by
Akira Asano
PDF
Chapter9 2
by
Takuya Minagawa
PRML 第14章
by
Akira Miyazawa
ラビットチャレンジレポート 応用数学
by
ssuserf4860b
スペクトラル・クラスタリング
by
Akira Miyazawa
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
Prml 4.3.5
by
Satoshi Kawamoto
PRML chapter7
by
Takahiro (Poly) Horikawa
Prml 2.3
by
Yuuki Saitoh
第4回MachineLearningのための数学塾資料(浅川)
by
Shin Asakawa
卒論プレゼンテーション -DRAFT-
by
Tomoshige Nakamura
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
20140512_水曜セミナードラフトv1
by
Tomoshige Nakamura
2014年5月14日_水曜セミナー発表内容_FINAL
by
Tomoshige Nakamura
主成分分析
by
貴之 八木
PRML2.3.1-2.3.3
by
とっきー Ishikawa
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
Prml 4.1.1
by
Satoshi Kawamoto
PRML 2.3節
by
Rei Takami
2015年度秋学期 応用数学(解析) 第6回 変数分離形の変形 (2015. 11. 5)
by
Akira Asano
Chapter9 2
by
Takuya Minagawa
Similar to PRML セミナー
PDF
PRML輪読#3
by
matsuolab
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
PRML輪読#2
by
matsuolab
PPTX
PRMLrevenge_3.3
by
Naoya Nakamura
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
PRML輪読#1
by
matsuolab
PDF
Prml sec6
by
Keisuke OTAKI
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PDF
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
PDF
3.4
by
show you
PDF
PRML8章
by
弘毅 露崎
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PDF
PRML 6.4-6.5
by
正志 坪坂
PDF
Introduction to statistics
by
Kohta Ishikawa
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PRML輪読#3
by
matsuolab
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PRML第3章_3.3-3.4
by
Takashi Tamura
PRML10-draft1002
by
Toshiyuki Shimono
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
ベイズ統計入門
by
Miyoshi Yuya
PRML読み会第一章
by
Takushi Miki
PRML輪読#2
by
matsuolab
PRMLrevenge_3.3
by
Naoya Nakamura
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PRML輪読#1
by
matsuolab
Prml sec6
by
Keisuke OTAKI
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
3.4
by
show you
PRML8章
by
弘毅 露崎
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PRML 6.4-6.5
by
正志 坪坂
Introduction to statistics
by
Kohta Ishikawa
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PRML セミナー
1.
第一回 PRML セミナー 2019/02/25
坂口 諒輔 1 / 73
2.
0. 今回のセミナーについて 今回のセミナーでは、PRML の第三章の線形回帰モデルと第四章の線形 識別モデル
(特にロジスティック回帰) を中心にお話ししたいと思い ます。 また、これらの話題を説明するために必要な予備知識を解説します。 (PRML の第一章と第二章に対応) なので、結果的に PRML のもっとも重要な話題を解説することになり ます。 なお注意点として、本スライドの式番号と PRML の式番号は異なりま すので、ご注意ください。 2 / 73
3.
目次 1. 予備知識 1-1. 簡単な回帰の例 1-2.
確率論と確率分布 1-3. 最尤推定とベイズ推定 2. 回帰問題 2-1. 線形基底関数モデル 2-2. 線形基底関数モデルの最尤推定 2-3. ベイズ線形回帰 3. 分類問題 3-1. ロジスティック回帰 3-2. ロジスティック回帰の最尤推定 3-3. ベイズロジスティック回帰 3 / 73
4.
1. 予備知識 機械学習、特にその中でも教師あり学習では、まず入力データの集合 {x1, x2,
· · · , xN } とそれぞれに対応する目標ベクトルの集合 {t1, t2, · · · , tN } を用意する。(訓練データ、または教師データ) 用意した訓練データを用いて、入力データから目標ベクトルを予測する 関数 y(x) を作る。(学習) 学習終了後、未知のデータ x の目標ベクトルを y(x) で予測する 各入力ベクトルを有限個の離散的なカテゴリに割り当てる場合 (例え ば、手書き数字の認識) をクラス分類といい、出力が連続変数の場合 を回帰という。 まずは回帰の簡単な例について考える 4 / 73
5.
1-1. 簡単な回帰の例 訓練データとして、N 個の入力
x = (x1, x2, · · · , xN )T とそれぞれに対 応する N 個の目標変数 t = (t1, t2, · · · , tN )T を用意する。(回帰なので、 出力 tn は連続的な値をとる) tn は以下のように sin(2πxn) にガウス分布 (後ほど詳しく) に従うラン ダムノイズ ϵ を加えたものとする。 tn = sin(2πxn) + ϵ (1.1) 回帰の目的は訓練データ (x, t) を使って、新たな入力 ˆx が与えられた時 の出力 ˆt を求めることである。 5 / 73
7.
1-1. 簡単な回帰の例 これから訓練データを用いて、未知の入力に対する出力を予測を行う。 しかし有限個 (N
個) であるがゆえ、予測値 ˆt には不確実性があり、そ の不確実性の定量的な表現を与える枠組みは後ほど導入する。 とりあえずこの節では、以下のような多項式を使ってフィッティングを 行い、予測を行うことを考える。 y(x, w) = w0 + w1x + w2x2 + · · · + wM xM = M∑ j=0 wjxj (1.2) 訓練データ (x, t) を使って、多項式のパラメータ w = (w0, w1, · · · , wM )T をいい感じにチューニングする。 そこで、以下の誤差関数 E(w) を最小にするような w(= w⋆ ) を求める ことを考える。 E(w) = 1 2 N∑ n=1 {y(xn, w) − tn}2 (1.3) 7 / 73
9.
1-1. 簡単な回帰の例 複雑なモデル (M
= 9 とか) を限られた訓練データ数 (N = 10 とか) を 用いて、過学習が起きないようにするために正則化を行う。 過学習が起きている時は、パラメータ w⋆ の成分が大きな正負の数にな る傾向があるため、以下のような誤差関数を考える。 E(w) = 1 2 N∑ n=1 {y(xn, w) − tn}2 + λ 2 ∥w∥2 (1.4) ここで、ノルム ∥w∥2 = wT w = w2 0 + w2 1 + · · · w2 M 、λ は正のパラメー タ。(正則化項と二乗誤差の和の項の相対的な重要度を調節) この誤差関数を使用すると、パラメータ w のノルムが大きくならない ようにフィッティングされる。 9 / 73
11.
1-1. 簡単な回帰の例 ここまでは非常に直感的にフィッティングの議論を行ってきた。 ここからは確率論を導入することで、より論理的にパターン認識の問題 を解いていく。 11 /
73
12.
1-2. 確率論と確率分布 パターン認識において、重要な不確実性を定量的に評価するために確率 論を導入する。 確率変数 X,
Y を考え、これらは X = xi (i = 1, 2, · · · , M)、 Y = yj (j = 1, 2, · · · , L) をとるとし、X = xi, Y = yj となる確率 (同時 確率) を p(X = xi, Y = yj) とかく。 X = xi となる確率 p(X = xi) は、p(X = xi, Y = yj) を用いて以下の ようにかける。(加法定理) p(X = xi) = L∑ j=1 p(X = xi, Y = yj) (1.5) また、X = xi が与えられた上で、Y = yj となる確率 (条件付き確率) を p(Y = yj|X = xi) とすると、以下のような関係式が成立する。(乗法 定理) p(X = xi, Y = yj) = p(Y = yj|X = xi)p(X = xi) (1.6) 12 / 73
13.
1-2. 確率論と確率分布 乗法定理と同時確率の対称性 p(X,
Y ) = p(Y, X) を用いると、ベイズの 定理が導ける。 p(Y |X) = p(X|Y )p(Y ) p(X) (1.7) ここで、p(Y ) を事前確率 (X が与えられる前の確率) といい、p(Y |X) を事後確率 (X が与えられた後の確率) という。 ベイズの定理は事前確率 p(Y ) に尤度 p(X|Y ) をかけると、事後確率 p(X|Y ) になるということを表す (p(X) は p(Y |X) が Y に対して規格 化されていることを保証する規格化定数)。 さらに、同時分布 p(X, Y ) が以下のように周辺分布の積で表せる時、X と Y は独立であるという。 p(X, Y ) = p(X) p(Y ) (1.8) 13 / 73
14.
1-2. 確率論と確率分布 これまでは離散的な確率変数について考えてきた。次に連続的な確率 変数の分布について考える。 確率変数 x
が (x, x + δx) の範囲に入る確率が δx → 0 の時に p(x) δx と 与えられる時、p(x) を確率密度という。 この時、変数 x が区間 (a, b) にある確率は以下の式で与えられる。 p(x ∈ (a, b)) = ∫ b a p(x) dx (1.9) また、確率の非負性と規格化より、p(x) は以下の性質を持つ。 p(x) ≥ 0 (1.10) ∫ ∞ −∞ p(x) dx = 1 (1.11) 14 / 73
15.
1-2. 確率論と確率分布 確率論での重要な計算として、重み付き平均がある。 連続的な確率変数 x
に対して、関数 f(x) の確率分布 p(x) の下での平均 値は以下のようになる。 E[f] = ∫ p(x)f(x) dx (1.12) ここで記法として、どの変数について和 (もしくは積分) をとっている のかを添字で表すことにする。例えば、以下の量は x ついて和 (もしく は積分) をとったものである。 Ex[f(x, y)] (1.13) 15 / 73
16.
1-2. 確率論と確率分布 以下が関数 f(x)
の確率分布 p(x) の下での分散である。(関数 f(x) がそ の平均値 E[f(x)] の周りでどれだけバラついているのかを表す) var[f] = E [ (f(x) − E[f(x)])2 ] (1.14) 特に f(x) = x の時は以下が成立する。 var[x] = E[x2 ] − E[x]2 (1.15) また、2 つの確率変数 x と y の間の共分散 (2 つの確率変数の依存性を 表す) は以下のように定義される。 cov[x, y] = Ex,y [ {x − E[x]}{y − E[y]} ] = Ex,y[xy] − E[x]E[y] (1.16) 2 つの確率変数 x と y が独立の時、cov[x, y] = 0 となる。 16 / 73
18.
1-2. 確率論と確率分布 ガウス分布の重要な性質として、x の平均値を分散がそれぞれ
µ と σ2 で与えられることである。 E[x] = ∫ ∞ −∞ N(x|µ, σ2 )x dx = µ (1.18) var[x] = E[x2 ] − E[x]2 = σ2 (1.19) 18 / 73
19.
1-2. 確率論と確率分布 次に、以下の D
次元のベクトル x に対する多変量ガウス分布を導入 する。 N(x|µ, Σ) = 1 (2π)D/2 1 |Σ|1/2 exp { − 1 2 (x − µ)T Σ−1 (x − µ) } (1.20) ここで、µ を D 次元の平均ベクトルとし、Σ を D × D の共分散行列と する。 この場合でも平均と共分散は以下の性質を満たす。 E[x] = ∫ N(x|µ, Σ)x dx = µ (1.21) cov[x] = E[(x − E[x])(x − E[x])T ] = Σ (1.22) 19 / 73
20.
1-2. 確率論と確率分布 以降の議論でよく使うガウス分布の公式を紹介する。 以下の周辺確率 p(x)
と条件付き確率 p(y|x) が与えられているとする。 p(x) = N(x|µ, Λ−1 ) (1.23) p(y|x) = N(y|Ax + b, L−1 ) (1.24) この時、周辺確率 p(y) と条件付き確率 p(x|y) は以下のようになる。 p(y) = N(y|Aµ + b, L−1 + AΛ−1 AT ) (1.25) p(x|y) = N(x|Ax + b, L−1 ) (1.26) ここで、µ, A, b は平均に関するパラメータで、Λ, L は精度行列であ る。(詳しい導出は PRML の 2.3.3 を参考) 20 / 73
21.
1-2. 確率論と確率分布 また、同時分布 p(xa,
xb) が以下で与えられていたとする。 p(xa, xb) = N(x|µ, Σ) (1.27) ここで、x = (xa, xb)T である。 このとき、周辺分布 p(xa) は以下のようなガウス分布になることが知ら れている。(詳しい導出は PRML の 2.3.2 を参考) p(xa) = ∫ p(xa, xb) dxb = N(xa|µa, Σaa) (1.28) ここで、µa と Σaa は以下のように定義される。 µ = ( µa µb ) , Σ = ( Σaa Σab Σba Σbb ) (1.29) 21 / 73
22.
1-3. 最尤推定とベイズ推定 ベイズ推定を多項式曲線フィッティングを例に説明する。 ベイズ的な確率解釈では、まずデータを観測する前に、我々のパラメー タ w
への仮説を事前確率 p(w) の形で取り込んでおく。 実際に入力データ x = (x1, x2, · · · , xN )T と目標変数 t = (t1, t2, · · · , tN )T を用いて、尤度関数 p(t|x, w) を求める。 ベイズの定理より、事後確率 p(w|t, x) を求める。 p(w|t, x) = p(t|x, w)p(w) p(t) (1.30) 22 / 73
23.
1-3. 最尤推定とベイズ推定 ベイズ推定では、訓練データ x,
t と未知の入力データ x が与えられた 時の予測 t の確率 p(t|x, t, x) が以下のように求まる。 p(t|x, t, x) = ∫ p(t|x, w)p(w|t, x) dw (1.31) (この予測分布の導出方法は以下の Qiita 記事でまとめてます。ご覧く ださい。そしていいねください。) https://qiita.com/gucchi0403/items/bfffd2586272a4c05a73 23 / 73
24.
1-3. 最尤推定とベイズ推定 頻度主義的な確率解釈とベイズ的な確率解釈で、尤度関数 p(D|w)
の役 割が変わる。 頻度主義的な確率解釈では、w はある固定されたパラメータとして捉 え、尤度関数 p(D|w) を最大にするような w を推定量として定める。 (w は 1 つに定まる) ベイズ的な確率解釈では、尤度関数は事前分布を観測データ D によっ て、事後分布に更新するために使う (事後分布 p(w|D) は w の確率分布 であり、w は不確実性をもつ) 24 / 73
25.
2. 回帰問題 以上の予備知識を用いて、回帰問題について深く考察する。 25 /
73
26.
2-1. 線形基底関数モデル はじめに説明した簡単な回帰モデルは、出力 y(x,
w) を以下のように入 力変数 x の多項式とするものであった。 y(x, w) = w0 + w1x + w2x2 + · · · + wM xM = M∑ j=0 wjxj (2.1) ここで、w = (w0, w1, · · · , wM )T はパラメータベクトルである。 この章では、一般化として入力をベクトル x とし、さらに非線形な基底 関数 ϕj(x) (j = 1, · · · , M − 1) で関数 y(x, w) を以下のように展開する ことを考える。 y(x, w) = w0 + M−1∑ j=1 wjϕj(x) (2.2) 26 / 73
27.
2-1. 線形基底関数モデル また式を短縮するため、ϕ0(x) =
1 とし、 φ(x) = (ϕ0(x), ϕ1(x), · · · , ϕM−1(x))T と定義すると、(2.2) は y(x, w) = M−1∑ j=0 wjϕj(x) = wT φ(x) (2.3) と書ける。 例えば、基底関数 ϕj(x) として以下のガウス基底関数がある。 ϕj(x) = exp { − (x − µj)2 2s2 } (2.4) この基底関数は x = µj を中心にして、分散 s2 によって支配される広が りを持つガウス基底関数である。 以降は一般の基底関数 ϕj(x) を用いて議論する。 27 / 73
28.
2-2. 線形基底関数モデルの最尤推定 初めの章で説明した回帰問題では、二乗和誤差を最小にするようにデー タ点を多項式関数にフィッティングさせた。 今回は、目標変数 t
が以下のように決定論的な関数 y(x, w) と期待値が 0 で精度が β のガウス分布 N(ϵ|0, β−1 ) に従う ϵ の和で書けるとする。 t = y(x, w) + ϵ (2.5) ϵ = t − y(x, w) より、以下のように目標変数 t もガウス分布に従う。 p(t|x, w, β) = N(t − y(x, w)|0, β−1 ) = N(t|y(x, w), β−1 ) (2.6) 28 / 73
29.
2-2. 線形基底関数モデルの最尤推定 ここで、入力データの集合 X
= {x1, x2, · · · , xN } とそれぞれに対応す る目標変数の集合 {t1, t2, · · · , tN } を用意し、目標変数を縦に並べたベ クトル t = (t1, t2, · · · , tN )T を定義する。 観測点 {t1, t2, · · · , tN } が分布 (2.6) から独立に生成されたとすると、尤 度関数は以下のように個々のデータ点の分布の積で書ける。 p(t|X, w, β) = N∏ n=1 N(tn|y(xn, w), β−1 ) (2.7) ここで、ガウス分布 N(x|µ, σ2 ) は N(x|µ, σ2 ) = 1 (2πσ2)1/2 exp { − 1 2σ2 (x − µ)2 } (2.8) である。 29 / 73
30.
2-2. 線形基底関数モデルの最尤推定 尤度関数の (2.7)
を最大化するようなパラメータを求める代わりに尤度 関数の対数を最大化するようなパラメータを求める。 まず、 ln { N(tn|y(xn, w), β−1 ) } = ln [ β1/2 (2π)1/2 exp { − β 2 (tn − y(xn, w))2 }] = 1 2 ln β − 1 2 ln (2π) − β 2 (tn − y(xn, w))2 (2.9) より、ln p(t|X, w, β) は以下のようになる。 ln p(t|X, w, β) = N∑ n=1 ln N(tn|y(xn, w), β−1 ) = N∑ n=1 [ 1 2 ln β − 1 2 ln (2π) − β 2 (tn − y(xn, w))2 ] = N 2 ln β − N 2 ln (2π) − β 2 N∑ n=1 (tn − y(xn, w))2 (2.10) 30 / 73
31.
2-2. 線形基底関数モデルの最尤推定 ここで、二乗和誤差 ED(w)
を ED(w) = 1 2 N∑ n=1 (tn − y(xn, w))2 (2.11) と定義すると、ln p(t|X, w, β) は ln p(t|X, w, β) = N 2 ln β − N 2 ln (2π) − βED(w) (2.12) となる。 最尤推定解 wML, βML を求めるために対数尤度 ln p(t|X, w, β) の勾配 を求める。 対数尤度の w に対する勾配は β に依存しないので、先に wML を求め て、そのあとに ln p(t|X, wML, β) を用いて βML を求めることがで きる。 31 / 73
32.
2-2. 線形基底関数モデルの最尤推定 対数尤度の w
に対する勾配は y(x, w) = wT φ(x) より、 ∂ ∂w ln p(t|X, w, β) = − β ∂ ∂w ED(w) = − β 2 N∑ n=1 ∂ ∂w (tn − wT φ(xn))2 =β N∑ n=1 (tn − wT φ(xn))φ(xn) =β { N∑ n=1 tnφ(xn) − N∑ n=1 φ(xn)φ(xn)T w } (2.13) となり、最尤推定解 wML は以下の式を満たす。 N∑ n=1 tnφ(xn) − N∑ n=1 φ(xn)φ(xn)T wML = 0 (2.14) 32 / 73
33.
2-2. 線形基底関数モデルの最尤推定 ここで、以下の計画行列 Φ
を定義する。 Φ = ϕ0(x1) ϕ1(x1) · · · ϕM−1(x1) ϕ0(x2) ϕ1(x2) · · · ϕM−1(x2) ... ... ... ... ϕ0(xN ) ϕ1(xN ) · · · ϕM−1(xN ) = φ(x1)T φ(x2)T ... φ(xN )T (2.15) 以下の式が成り立つ事がわかる。 ΦT Φ = N∑ n=1 φ(xn)φ(xn)T (2.16) ΦT t = N∑ n=1 tnφ(xn) (2.17) これより、(2.14) は以下のようになる。 ΦT t − ΦT ΦwML = 0 (2.18) 33 / 73
34.
2-2. 線形基底関数モデルの最尤推定 よって、最尤推定解 wML
は wML = (ΦT Φ)−1 ΦT t (2.19) となる。 次に、最尤推定解 wML を代入した ln p(t|X, wML, β) の β の微分を考 えると ∂ ∂β ln p(t|X, wML, β) = N 2 1 β − ED(wML) (2.20) となる。 これより、最尤推定解 βML の逆数は以下のようになる。 1 βML = 2 N ED(wML) = 1 N N∑ n=1 (tn − wT MLφ(xn))2 (2.21) 34 / 73
35.
2-2. 線形基底関数モデルの最尤推定 これより、新たな入力ベクトル x
が与えられた時の目標変数 t の予測分 布 p(t|x, wML, βML) は以下のようになる。 p(t|x, wML, βML) = N(t|y(x, wML), β−1 ML) (2.22) ここで、wML, βML は (2.19) と (2.21) で与えられる。 35 / 73
36.
2-3. ベイズ線形回帰 次は線形回帰モデルをベイズ的に扱うことを考える。 そこで、平均が m0
で共分散が S0 の以下の事前分布を仮定する。 p(w) = N(w|m0, S0) (2.23) また、尤度関数は p(t|X, w, β) = N∏ n=1 N(tn|y(xn, w), β−1 ) (2.24) であるので、事後分布 p(w|t) はベイズの定理により、以下のように なる。 p(w|t) ∝ p(t|X, w, β)p(w) ∝ exp ( − β 2 N∑ n=1 (tn − wT φ(xn))2 ) × exp ( − 1 2 (w − m0)T S−1 0 (w − m0) ) (2.25) 36 / 73
37.
2-3. ベイズ線形回帰 (2.25) より、指数の肩が
w の 2 次であるので p(w|t) はガウス分布で ある。 具体的には、p(w|t) は以下のようになる。(PRML の演習 3.7 参照) p(w|t) = N(w|mN , SN ) (2.26) ここで、mN と SN は以下である。 mN =SN (S−1 0 m0 + βΦT t) (2.27) S−1 N =S−1 0 + βΦT Φ (2.28) 37 / 73
38.
2-3. ベイズ線形回帰 ここで、最尤推定解 wML(2.19)
と事後分布 p(w|t) のモード wMAP (モードとは、p(w|t) を最大にする w) と事後分布の平均値 mN の関係 を考察する。 まず、ガウス分布のモードは平均値に等しいという性質 (PRML の演習 1.9 参照) があるので、wMAP = mN であることがわかる。 さらに、無限に広い事前分布 S0 = α−1 I(α → 0) を考えると S−1 N = S−1 0 + βΦT Φ → βΦT Φ (2.29) となり、 mN = SN (S−1 0 m0 + βΦT t) → (ΦT Φ)−1 ΦT t (2.30) となるので、このとき wMAP = mN = wML であることがわかる。 38 / 73
39.
2-3. ベイズ線形回帰 前の章で、ベイズ的な扱いでは、尤度関数は事後分布を更新するもので あると説明したが、その更新の様子を例を使って見ていく。 まず、設定として尤度関数の平均値は y(x,
w) = w0 + w1x とする。 また、教師データについては、入力データ xn は −1 から 1 の一様分布 から選び、対応する目標値 tn は、標準偏差 0.2 で平均 0 のガウスノイ ズ ϵ を用いて tn = f(xn, a0 = −0.3, a1 = 0.5) + ϵ (2.31) ここで、 f(x, a0, a1) = a0 + a1x (2.32) である。 つまり、ここでの目標は教師データを用いてパラメータ w0, w1 が a0 = −0.3, a1 = 0.5 を復元することである。 39 / 73
40.
2-3. ベイズ線形回帰 また、尤度関数の精度は既知で β
= (1/0.2)2 = 25 とし、事前分布は以 下のような等方的ガウス分布を用いて、パラメータ α の値は α = 2.0 と する。 p(w) = N(w|0, α−1 I) (2.33) この設定で教師データが増えていくときの事後分布の更新について見 ていく。 40 / 73
45.
2-3. ベイズ線形回帰 次に事後分布 p(w|t,
α, β) と尤度関数 p(t|x, w, β) を用いて、未知の入 力ベクトル x に対する予測 t の確率分布を求める。(事後分布にハイ パーパラメータ α, β を引数に復活させた。) (1.31) より、予測分布 p(t|t, α, β) は以下のようになる。 p(t|t, α, β) = ∫ p(t|x, w, β)p(w|t, α, β) dw (2.34) (2.6) と (2.26) と (1.25) を用いると、p(t|t, α, β) は以下のようになる。 (PRML の演習 3.10 参照) p(t|t, α, β) = N(t|mT N φ(x), σ2 N (x)) (2.35) ここで、予測分布の分散 σ2 N (x) は以下で与えられる。 σ2 N (x) = 1 β + φ(x)T SN φ(x) (2.36) 45 / 73
46.
2-3. ベイズ線形回帰 σ2 N (x)
の一項目の 1/β は尤度関数の分散であり、入力データに対する 出力のバラつき (ノイズ) である。 一方、二項目の φ(x)T SN φ(x) は w の不確実性 (事後分布の分散) から くる項である。 この二項目は新たな教師データが追加される (N → N + 1) と小さくな る、つまり σ2 N+1(x) ≤ σ2 N (x) となる。(PRML の演習 3.11 参照) これは教師データが増えると、出力の予測の確実さが増えるということ を表す。 最後に例を用いて、教師データが増えると予測の不確かさが減る様子を 見る。 46 / 73
47.
2-3. ベイズ線形回帰 例は簡単な回帰のときに使用した三角関数の例である。 訓練データとして、N 個の入力
x = (x1, x2, · · · , xN )T とそれぞれに対 応する N 個の目標変数 t = (t1, t2, · · · , tN )T を用意する。 tn は以下のように sin(2πxn) にガウス分布に従うランダムノイズ ϵ を 加えたものとする。 tn = sin(2πxn) + ϵ (2.37) 尤度関数の平均値である y(x, w) はガウス基底関数 (2.4) で展開する。 この設定で教師データの数が N = 1, 2, 4, 25 のときのグラフは以下のよ うになる。 47 / 73
49.
3. 分類問題 これまでは回帰問題を取り扱ってきたが、ここからは分類問題を取り 扱う。 回帰と同じように、訓練データとして入力データの集合 {x1, x2,
· · · , xN } とそれぞれに対応する目標変数の集合 {t1, t2, · · · , tN } を用意するが、分類の場合 (正しくは二値分類) は目的変数 tn は 0 か 1 の離散的な値をとる。 実用的な例として、入力データ x を画像として、t = 0 なら犬の画像、 t = 1 なら猫の画像とか。 今回は分類のモデルとして、ロジスティック回帰モデルを紹介する。 (「回帰」と付いているが、分類のモデルである。) 49 / 73
50.
3-1. ロジスティック回帰 まず、記号として t
= 0 のクラスを C1 とし、t = 1 のクラスを C2 と する。 また、回帰の時と同じように以下のような、入力 x とパラメータ w の 関数 y(x, w) を考える。 y(x, w) = M−1∑ j=0 wjϕj(x) = wT φ(x) (3.1) φ(x) は特徴ベクトルである。 回帰では、尤度関数 p(t|x, w, β) として、(2.6) のように平均が y(x, w) で分散が β のガウス分布を考えて、最尤推定を行なった。 実際に分類問題に対してもそのようなモデル設定で議論する場合もあ る。(PRML の 4.1.3 参照) 50 / 73
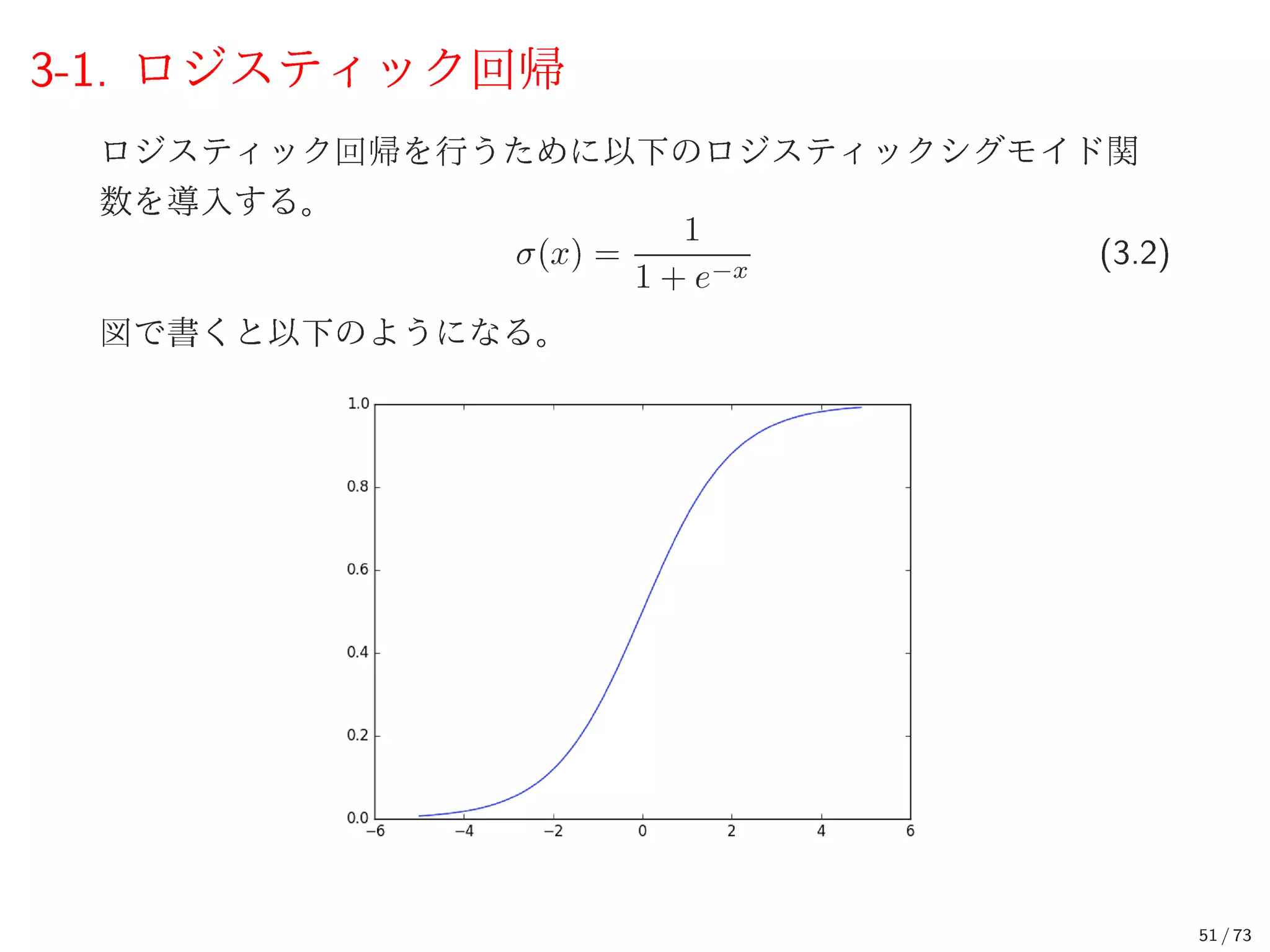
52.
3-1. ロジスティック回帰 このロジスティックシグモイド関数を利用して、確率 p(C1|x,
w) を以 下のように定義する。 p(C1|x, w) = σ(y(x, w)) (3.3) ここで二値分類なので、規格化条件より p(C2|x, w) は p(C1|x, w) を用 いて以下のように求まる。 p(C2|x, w) = 1 − p(C1|x, w) (3.4) t = 0 のクラスを C1 とし、t = 1 のクラスを C2 としているので、尤度関 数 p(t|x, w) は p(t|x, w) = σ(y(x, w))t (1 − σ(y(x, w)))1−t (3.5) となる。 (このような分布をベルヌーイ分布という) 52 / 73
53.
3-2. ロジスティック回帰の最尤推定 このロジスティック回帰で最尤推定を行うことを考える。 いつものように、訓練データとして入力データの集合 X =
{x1, x2, · · · , xN } とそれぞれに対応する目標変数の集合 {t1, t2, · · · , tN } を用意する。 教師データ一つ一つが分布 (3.12) から独立に生成されているとすると、 尤度関数 p(t|X, w) は以下のようになる。 p(t|X, w) = N∏ n=1 ytn n (1 − yn)1−tn (3.6) となる。 ここで yn は以下で定義される。 yn = σ(y(xn, w)) (3.7) 53 / 73
54.
3-2. ロジスティック回帰の最尤推定 尤度関数 (3.6)
を最大にする w を求めることは以下の負の対数尤度を 最小にする w を求めることと等価である。 E(w) = − ln p(t|X, w) = − N∑ n=1 ln { ytn n (1 − yn)1−tn } = − N∑ n=1 { tn ln yn + (1 − tn) ln (1 − yn) } (3.8) これは交差エントロピー誤差と呼ばれる誤差関数で、分類問題でよく使 われる誤差関数である。 54 / 73
55.
3-2. ロジスティック回帰の最尤推定 次に負の対数尤度 (3.8)
を最小にする w を求めるために (3.8) の w に 対する勾配を求めると以下のようになる。(PRML の演習 4.13 参照) ∇E(w) = N∑ n=1 (yn − tn)φ(xn) (3.9) この勾配の形は正解ラベル tn と予測値 yn の差 (つまり誤差) と基底関 数ベクトル φ(xn) の和の形をしている。 この形は前章の回帰での対数尤度の勾配 (2.13) と同じ形をしている。 (PRML の 4.3.6 参照) 55 / 73
56.
3-2. ロジスティック回帰の最尤推定 この勾配 ∇E(w)
をゼロにする w を解析的に求めることはできない。 その理由は予測値 y = σ(wT φ(x)) がロジスティック関数を活性化関数 に持つからである。 回帰のときは予測値 y = wT φ(x) は恒等関数を活性化関数に持つから (2.13) は解析的に解けたわけである。 このように勾配 ∇E(w) をゼロにする w を解析的に求めることができ ない時は勾配降下法を用いることがある。(ニューラルネットでもこの 方法がよく用いられる。) 勾配降下法では、まずランダムに決めたパラメータの初期値を w(0) と し、誤差関数の勾配を用いてパラメータを以下のように更新する。 w(1) = w(0) − η∇E(w(0) ) (3.10) ここで η > 0 は学習パラメータと呼ぶ。 これを繰り返すことでパラメータが勾配 ∇E(w) が小さくなる方向に更 新され、E(w) を最小にするパラメータに収束する。 56 / 73
57.
3-3. ベイズロジスティック回帰 次はロジスティック回帰をベイズ的に扱うことを考える。 回帰でも議論したとおり、ベイズ推定では未知の入力 x
に対する出力 t の予測分布 p(t|x, t, X) を求めることが目的となる。 (1.31) より、その予測分布 p(t|x, t, X) は重み w の積分で以下のように かける。 p(t|x, t, X) = ∫ p(t|x, w)p(w|t, X) dw (3.11) ここで、p(t|x, w) は尤度関数であり、p(w|t, X) はパラメータの事後分 布である。 特に今回は二値分類を考えているので、確率 p(C1|x, t, X) = ∫ p(C1|x, w)p(w|t, X) dw (3.12) だけを積分して求めて、p(C2|x, t, X) は p(C2|x, t, X) = 1 − p(C1|x, t, X) (3.13) のように規格化条件から求めることを考える。 57 / 73
58.
3-3. ベイズロジスティック回帰 ただし回帰の時とは違い、積分 (3.12)
を解析的に解くのは不可能で ある。 なので、積分を近似的に求めることを考える。 今回は (PRML では) ラプラス近似を用いて積分を近似的に求めている。 具体的には (3.12) のパラメータの事後分布 p(w|t, X) にラプラス近似 を適用して、ガウス分布に近似する。 ここでラプラス近似の説明を少し行う。 58 / 73
59.
3-3. ベイズロジスティック回帰 まずは確率変数が一次元の変数 z
の場合を考え、以下のような確率分布 p(z) を考える。 p(z) = 1 Z f(z) (3.14) ここで、Z は以下で定義される規格化定数である。 Z = ∫ f(z) dz (3.15) ラプラス近似の目的は分布 p(z) をモード (dp(z)/dz = 0 となる z) を中 心とするガウス分布に近似することである。 まずはモード z = z0 を見つける。モードとは (3.14) より df(z) dz z=z0 = 0 (3.16) なる z0 を求めることである。 59 / 73
60.
3-3. ベイズロジスティック回帰 モードが求まったら、関数 ln
f(z) を z = z0 周りで以下のようにテイ ラー展開の 2 次までで近似する。 ln f(z) ∼ ln f(z0) − 1 2 A(z − z0)2 (3.17) ここで、 A = − d2 dz2 ln f(z) z=z0 (3.18) である。 ここで、(3.16) により (3.17) の右辺で一次の項が存在しない。 (3.17) の両辺の指数をとると f(z) ∼ f(z0) exp { − 1 2 A(z − z0)2 } (3.19) となる。 60 / 73
61.
3-3. ベイズロジスティック回帰 規格化をすると、分布 p(z)
は p(z) ∼ ( A 2π )1/2 exp { − 1 2 A(z − z0)2 } (3.20) と近似できる。これがラプラス近似である。 ただし注意点として、A > 0 でないとガウス分布が定義できないことが ある。 61 / 73
62.
3-3. ベイズロジスティック回帰 次は一次元の確率変数から、ベクトルに拡張しよう。 つまり、以下の確率分布 p(z)
を定義する。 p(z) = 1 Z f(z) (3.21) ここで、 Z = ∫ f(z) dz (3.22) である。 一次元の確率変数と同じように勾配 ∇f(z) がゼロになる点 z0 を求 める。 62 / 73
63.
3-3. ベイズロジスティック回帰 モードが求まったら、ln f(z)
を z0 周りでテイラー展開で近似する。 ln f(z) ∼ ln f(z0) − 1 2 (z − z0)T A(z − z0) (3.23) ここで、A は以下で定義される M × M のヘッセ行列である。 A = −∇∇ ln f(z) z=z0 (3.24) 次に (3.23) の両辺の指数をとると以下のようになる。 f(z) ∼ f(z0) exp { − 1 2 (z − z0)T A(z − z0) } (3.25) これより規格化をすると、分布 p(z) は p(z) ∼ |A|1/2 (2π)M/2 exp { − 1 2 (z − z0)T A(z − z0) } = N(z|z0, A−1 ) (3.26) とガウス分布に近似できる。 63 / 73
64.
3-3. ベイズロジスティック回帰 以上で説明したラプラス近似を用いて以下の積分を近似したい。 p(C1|x, t,
X) = ∫ p(C1|x, w)p(w|t, X) dw (3.27) まず、事後分布 p(w|t, X) を求めるために事前分布を導入する。 p(w) = N(w|m0, S0) (3.28) (3.14) より、尤度関数は p(t|X, w) は p(t|X, w) = N∏ n=1 ytn n (1 − yn)1−tn (3.29) であった。 64 / 73
65.
3-3. ベイズロジスティック回帰 これより、事後分布 p(w|t,
X) はベイズの定理より、以下である。 p(w|t, X) ∝ p(w)p(t|X, w) (3.30) となるので、ln p(w|t, X) は以下となる。 ln p(w|t, X) = − 1 2 (w − m0)T S−1 0 (w − m0) + N∑ n=1 { tn ln yn + (1 − tn) ln (1 − yn) } + const. (3.31) この事後分布の対数 ln p(w|t, X) を最大にするパラメータ wMAP を (た とえば勾配降下法などで) 求めて、その点 wMAP でのヘッセ行列を求め ると、以下のようになる。 S−1 N = − ∇∇ ln p(w|t, X) w=wMAP =S−1 0 + N∑ n=1 yn(1 − yn)φnφT n w=wMAP (3.32) 65 / 73
66.
3-3. ベイズロジスティック回帰 よって、ラプラス近似を用いると事後分布 p(w|t,
X) は以下のように近 似できる。 p(w|t, X) ∼ N(w|wMAP, SN ) (3.33) これより、(3.27) の積分は以下のように近似できる。 p(C1|x, t, X) ∼ ∫ σ(wT φ) N(w|wMAP, SN ) dw (3.34) ここで、p(C1|x, w) = σ(wT φ) を利用した。 次に、ロジスティックシグモイド関数を以下のように書き直す。 σ(wT φ) = ∫ δ(a − wT φ)σ(a) da (3.35) ここで、δ(·) はデュラックのデルタ関数である。 66 / 73
67.
3-3. ベイズロジスティック回帰 これより、(3.34) は以下のように書き直せる。 ∫ σ(wT φ)
N(w|wMAP, SN ) dw = ∫ ∫ δ(a − wT φ)σ(a) N(w|wMAP, SN ) da dw = ∫ ∫ δ(a − wT φ) N(w|wMAP, SN ) dw σ(a) da = ∫ p(a) σ(a) da (3.36) ここで、 p(a) = ∫ δ(a − wT φ) N(w|wMAP, SN ) dw (3.37) である。 67 / 73
68.
3-3. ベイズロジスティック回帰 積分 (3.37)
において、φ に平行なすべての方向の積分はそれらのパラ メータに線形制約を与え、また φ に直行するすべての方向の積分はガ ウス分布 N(w|wMAP, SN ) の周辺化を与える。 たとえば、w = (w1, w2)T とし、φ = (ϕ, 0)T であるときを考えると、 積分 (3.37) は以下のようにかける。 p(a) = ∫ ∫ δ(a − w1ϕ) N(w|wMAP, SN ) dw1dw2 = ∫ δ(a − w1ϕ) [ ∫ N(w|wMAP, SN ) dw2 ] dw1 (3.38) (1.28) より、ガウス分布を周辺化した周辺分布は再びガウス分布である ことがわかっているので、φ に直行する w2 方向の積分はガウス分布の 周辺化を与え、その周辺化されたガウス分布は N(w1|(wMAP)1, (SN )11) となる。 68 / 73
69.
3-3. ベイズロジスティック回帰 また、w1 の積分をすると、積分
(3.37) は以下のようになる。 p(a) = ∫ δ(a − w1ϕ) N(w1|(wMAP)1, (SN )11) dw1 = 1 |ϕ| N(a/ϕ|(wMAP)1, (SN )11) =N(a|(ϕwMAP)1, (ϕ2 SN )11) (3.39) つまり、φ に平行な w1 の方向の積分は w1 に w1 = a/ϕ なる線形制約 を与えることがわかる。 これより、p(a) は確率変数が a のガウス分布になることがわかる。 69 / 73
70.
3-3. ベイズロジスティック回帰 ガウス分布は平均と分散が決まれば、形が一意に定まり、平均 µa
と分 散 σ2 a は以下のようになる。 µa = ∫ p(a)a da = ∫ ∫ aδ(a − wT φ) N(w|wMAP, SN ) dwda = ∫ wT φ N(w|wMAP, SN ) dw = wT MAPφ (3.40) σ2 a = ∫ p(a)(a2 − µ2 a) da = ∫ ∫ (a2 − µ2 a)δ(a − wT φ) N(w|wMAP, SN ) dwda = ∫ ((wT φ)2 − (wT MAPφ)2 ) N(w|wMAP, SN ) dw =φT [ ∫ (wwT − wMAPwT MAP) N(w|wMAP, SN ) dw ] φ =φT SN φ (3.41) 70 / 73
71.
3-3. ベイズロジスティック回帰 すると、予測分布 p(C1|x,
t, X) は (3.36) より、以下のようになること がわかる。 p(C1|x, t, X) ∼ ∫ σ(a)N(a|µa, σ2 a) da (3.42) ここで、µa と σ2 a は (3.40) と (3.41) で計算した平均と分散のパラメー タである。 この積分 (3.42) もまた解析的に積分できない。 そこで以下のプロビット関数の逆関数 Φ(a) を導入する。 Φ(a) = 1 2 { 1 + erf ( a √ 2 )} (3.43) ここで、誤差関数 erf(a) は以下で定義される。 erf(a) = 2 √ π ∫ a 0 exp (−θ2 ) dθ (3.44) 71 / 73
73.
3-3. ベイズロジスティック回帰 さらにプロビット関数の逆関数には以下の性質がある。(PRML の演習 4.26
参照) ∫ Φ(λa)N(a|µ, σ2 ) da = Φ ( µ (λ−2 + σ2)1/2 ) (3.45) これらの性質を用いて、積分 (3.42) を以下のように近似して求める。 p(C1|x, t, X) ∼ ∫ σ(a)N(a|µa, σ2 a) da ∼ ∫ Φ (√ π 8 a ) N(a|µa, σ2 a) da =Φ ( µa (8/π + σ2 a)1/2 ) ∼ σ (√ 8 π µa (8/π + σ2 a)1/2 ) =σ ( µa (1 + πσ2 a/8)1/2 ) (3.46) ここで、µa と σ2 a は (3.40) と (3.41) である。 73 / 73
Download














![1-2. 確率論と確率分布
確率論での重要な計算として、重み付き平均がある。
連続的な確率変数 x に対して、関数 f(x) の確率分布 p(x) の下での平均
値は以下のようになる。
E[f] =
∫
p(x)f(x) dx (1.12)
ここで記法として、どの変数について和 (もしくは積分) をとっている
のかを添字で表すことにする。例えば、以下の量は x ついて和 (もしく
は積分) をとったものである。
Ex[f(x, y)] (1.13)
15 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-15-2048.jpg)
![1-2. 確率論と確率分布
以下が関数 f(x) の確率分布 p(x) の下での分散である。(関数 f(x) がそ
の平均値 E[f(x)] の周りでどれだけバラついているのかを表す)
var[f] = E
[
(f(x) − E[f(x)])2
]
(1.14)
特に f(x) = x の時は以下が成立する。
var[x] = E[x2
] − E[x]2
(1.15)
また、2 つの確率変数 x と y の間の共分散 (2 つの確率変数の依存性を
表す) は以下のように定義される。
cov[x, y] = Ex,y
[
{x − E[x]}{y − E[y]}
]
= Ex,y[xy] − E[x]E[y] (1.16)
2 つの確率変数 x と y が独立の時、cov[x, y] = 0 となる。
16 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-16-2048.jpg)

![1-2. 確率論と確率分布
ガウス分布の重要な性質として、x の平均値を分散がそれぞれ µ と σ2
で与えられることである。
E[x] =
∫ ∞
−∞
N(x|µ, σ2
)x dx = µ (1.18)
var[x] = E[x2
] − E[x]2
= σ2
(1.19)
18 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-18-2048.jpg)
![1-2. 確率論と確率分布
次に、以下の D 次元のベクトル x に対する多変量ガウス分布を導入
する。
N(x|µ, Σ) =
1
(2π)D/2
1
|Σ|1/2
exp
{
−
1
2
(x − µ)T
Σ−1
(x − µ)
}
(1.20)
ここで、µ を D 次元の平均ベクトルとし、Σ を D × D の共分散行列と
する。
この場合でも平均と共分散は以下の性質を満たす。
E[x] =
∫
N(x|µ, Σ)x dx = µ (1.21)
cov[x] = E[(x − E[x])(x − E[x])T
] = Σ (1.22)
19 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-19-2048.jpg)










![2-2. 線形基底関数モデルの最尤推定
尤度関数の (2.7) を最大化するようなパラメータを求める代わりに尤度
関数の対数を最大化するようなパラメータを求める。
まず、
ln
{
N(tn|y(xn, w), β−1
)
}
= ln
[
β1/2
(2π)1/2
exp
{
−
β
2
(tn − y(xn, w))2
}]
=
1
2
ln β −
1
2
ln (2π) −
β
2
(tn − y(xn, w))2
(2.9)
より、ln p(t|X, w, β) は以下のようになる。
ln p(t|X, w, β) =
N∑
n=1
ln N(tn|y(xn, w), β−1
)
=
N∑
n=1
[
1
2
ln β −
1
2
ln (2π) −
β
2
(tn − y(xn, w))2
]
=
N
2
ln β −
N
2
ln (2π) −
β
2
N∑
n=1
(tn − y(xn, w))2
(2.10)
30 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-30-2048.jpg)




































![3-3. ベイズロジスティック回帰
積分 (3.37) において、φ に平行なすべての方向の積分はそれらのパラ
メータに線形制約を与え、また φ に直行するすべての方向の積分はガ
ウス分布 N(w|wMAP, SN ) の周辺化を与える。
たとえば、w = (w1, w2)T
とし、φ = (ϕ, 0)T
であるときを考えると、
積分 (3.37) は以下のようにかける。
p(a) =
∫ ∫
δ(a − w1ϕ) N(w|wMAP, SN ) dw1dw2
=
∫
δ(a − w1ϕ)
[ ∫
N(w|wMAP, SN ) dw2
]
dw1
(3.38)
(1.28) より、ガウス分布を周辺化した周辺分布は再びガウス分布である
ことがわかっているので、φ に直行する w2 方向の積分はガウス分布の
周辺化を与え、その周辺化されたガウス分布は
N(w1|(wMAP)1, (SN )11) となる。
68 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-68-2048.jpg)

![3-3. ベイズロジスティック回帰
ガウス分布は平均と分散が決まれば、形が一意に定まり、平均 µa と分
散 σ2
a は以下のようになる。
µa =
∫
p(a)a da =
∫ ∫
aδ(a − wT
φ) N(w|wMAP, SN ) dwda
=
∫
wT
φ N(w|wMAP, SN ) dw = wT
MAPφ
(3.40)
σ2
a =
∫
p(a)(a2
− µ2
a) da
=
∫ ∫
(a2
− µ2
a)δ(a − wT
φ) N(w|wMAP, SN ) dwda
=
∫
((wT
φ)2
− (wT
MAPφ)2
) N(w|wMAP, SN ) dw
=φT
[ ∫
(wwT
− wMAPwT
MAP) N(w|wMAP, SN ) dw
]
φ
=φT
SN φ
(3.41)
70 / 73](https://image.slidesharecdn.com/prml2-190226113910/75/PRML-70-2048.jpg)





![[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlp-150228215621-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)







![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)






