Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takao Yamanaka
PDF, PPTX
71,994 views
混合モデルとEMアルゴリズム(PRML第9章)
研究室で説明した「パターン認識と機械学習(下)」の第9章混合モデルとEMアルゴリズムについてです.
Read more
87
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
11
/ 46
12
/ 46
Most read
13
/ 46
14
/ 46
Most read
15
/ 46
Most read
16
/ 46
17
/ 46
18
/ 46
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
More Related Content
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
PRML8章
by
弘毅 露崎
PDF
PRML Chapter 14
by
Masahito Ohue
PDF
機械学習の理論と実践
by
Preferred Networks
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PRML第6章「カーネル法」
by
Keisuke Sugawara
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
変分ベイズ法の説明
by
Haruka Ozaki
PRML8章
by
弘毅 露崎
PRML Chapter 14
by
Masahito Ohue
機械学習の理論と実践
by
Preferred Networks
What's hot
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
最適輸送入門
by
joisino
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
PRML輪読#2
by
matsuolab
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
PRML輪読#8
by
matsuolab
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
レプリカ交換モンテカルロ法で乱数の生成
by
Nagi Teramo
PPTX
勾配降下法の 最適化アルゴリズム
by
nishio
PPTX
ベイズ深層学習5章 ニューラルネットワークのベイズ推論 Bayesian deep learning
by
ssuserca2822
PDF
PRML輪読#10
by
matsuolab
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
最適輸送入門
by
joisino
深層生成モデルと世界モデル
by
Masahiro Suzuki
PRML輪読#2
by
matsuolab
ベイズ統計学の概論的紹介
by
Naoki Hayashi
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
深層学習の数理
by
Taiji Suzuki
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PRML輪読#8
by
matsuolab
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
レプリカ交換モンテカルロ法で乱数の生成
by
Nagi Teramo
勾配降下法の 最適化アルゴリズム
by
nishio
ベイズ深層学習5章 ニューラルネットワークのベイズ推論 Bayesian deep learning
by
ssuserca2822
PRML輪読#10
by
matsuolab
Viewers also liked
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
機械学習を用いた異常検知入門
by
michiaki ito
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
PRML輪読#13
by
matsuolab
PDF
研究室内PRML勉強会 8章1節
by
Koji Matsuda
PDF
数式を使わずイメージで理解するEMアルゴリズム
by
裕樹 奥田
PDF
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
PDF
Chapter9 2
by
Takuya Minagawa
PDF
Objectnessとその周辺技術
by
Takao Yamanaka
PDF
Deformable Part Modelとその発展
by
Takao Yamanaka
PPTX
確率ロボティクス第12回
by
Ryuichi Ueda
PPTX
確率ロボティクス第11回
by
Ryuichi Ueda
ODP
音声認識の基礎
by
Akinori Ito
PDF
高速な物体候補領域提案手法 (Fast Object Proposal Methods)
by
Takao Yamanaka
PDF
共起要素のクラスタリングを用いた分布類似度計算
by
長岡技術科学大学 自然言語処理研究室
PPT
SVM&R with Yaruo!!
by
guest8ee130
PDF
Deep Learning for Speech Recognition - Vikrant Singh Tomar
by
WithTheBest
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
機械学習を用いた異常検知入門
by
michiaki ito
パターン認識 04 混合正規分布
by
sleipnir002
PRML輪読#13
by
matsuolab
研究室内PRML勉強会 8章1節
by
Koji Matsuda
数式を使わずイメージで理解するEMアルゴリズム
by
裕樹 奥田
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
Chapter9 2
by
Takuya Minagawa
Objectnessとその周辺技術
by
Takao Yamanaka
Deformable Part Modelとその発展
by
Takao Yamanaka
確率ロボティクス第12回
by
Ryuichi Ueda
確率ロボティクス第11回
by
Ryuichi Ueda
音声認識の基礎
by
Akinori Ito
高速な物体候補領域提案手法 (Fast Object Proposal Methods)
by
Takao Yamanaka
共起要素のクラスタリングを用いた分布類似度計算
by
長岡技術科学大学 自然言語処理研究室
SVM&R with Yaruo!!
by
guest8ee130
Deep Learning for Speech Recognition - Vikrant Singh Tomar
by
WithTheBest
Similar to 混合モデルとEMアルゴリズム(PRML第9章)
PDF
PRML2.1 2.2
by
Takuto Kimura
PDF
PRML輪読#9
by
matsuolab
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PPTX
Prml 最尤推定からベイズ曲線フィッティング
by
takutori
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PDF
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PDF
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
PPTX
続・わかりやすいパターン認識 9章
by
hakusai
PDF
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PDF
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PPTX
Gmm勉強会
by
Hayato Ohya
PDF
prml_titech_9.0-9.2
by
Taikai Takeda
PDF
PRML復々習レーン#14
by
Takuya Fukagai
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
Oshasta em
by
Naotaka Yamada
PDF
PRML 9章
by
ぱんいち すみもと
PRML2.1 2.2
by
Takuto Kimura
PRML輪読#9
by
matsuolab
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
Prml 最尤推定からベイズ曲線フィッティング
by
takutori
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
続・わかりやすいパターン認識 9章
by
hakusai
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
Gmm勉強会
by
Hayato Ohya
prml_titech_9.0-9.2
by
Taikai Takeda
PRML復々習レーン#14
by
Takuya Fukagai
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
Oshasta em
by
Naotaka Yamada
PRML 9章
by
ぱんいち すみもと
混合モデルとEMアルゴリズム(PRML第9章)
1.
2013/11/13 上智大学 山中高夫 混合モデルとEMアルゴリズム 「第9章
混合モデルとEM」, C.M.ビショップ, パターン認識と学習(下), シュプリンガー・ジャパン,2007. 9.1 K-meansクラスタリング 9.2 混合ガウス分布(Mixtures of Gaussians) 9.3 EMアルゴリズムのもう一つの解釈 9.4 一般のEMアルゴリズム
2.
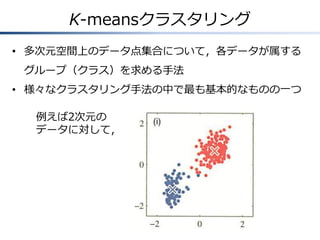
K-meansクラスタリング • 多次元空間上のデータ点集合について,各データが属する グループ(クラス)を求める手法 • 様々なクラスタリング手法の中で最も基本的なものの一つ 例えば2次元の データに対して,
3.
K-meansクラスタリングの直感的説明 • はじめに,クラスタリングを行う方法を図で説明してから, そのアルゴリズムを数式を使って説明する
4.
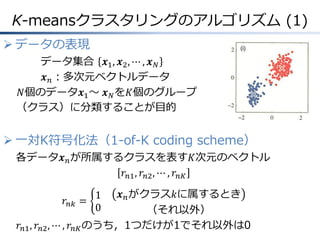
K-meansクラスタリングのアルゴリズム (1) データの表現 データ集合
𝒙1 , 𝒙2 , ⋯ , 𝒙 𝑁 𝒙 𝑛 :多次元ベクトルデータ 𝑁個のデータ𝒙1 ~ 𝒙 𝑁 を𝐾個のグループ (クラス)に分類することが目的 一対K符号化法(1-of-K coding scheme) 各データ𝒙 𝑛 が所属するクラスを表す𝐾次元のベクトル 𝑟 𝑛1 , 𝑟 𝑛2 , ⋯ , 𝑟 𝑛𝐾 𝒙 𝑛 がクラス𝑘に属するとき (それ以外) 𝑟 𝑛1 , 𝑟 𝑛2 , ⋯ , 𝑟 𝑛𝐾 のうち,1つだけが1でそれ以外は0 𝑟 𝑛𝑘 = 1 0
5.
K-meansクラスタリングのアルゴリズム (2) クラスタリングに用いる指標値 𝑁 𝐾 𝐽= 𝑟
𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 𝝁𝑘 (9.1) 𝑛=1 𝑘=1 𝝁 𝑘 :𝑘番目のクラスの代表ベクトル(プロト タイプ)→ 通常はクラス内の平均ベクトル 各データ点𝒙 𝑛 と割り当てられたクラスのプロトタイプ𝝁 𝑘 間の2 定距離の総和を表し,この指標値が最小になるようにクラス 𝑟 𝑛𝑘 を決定する
6.
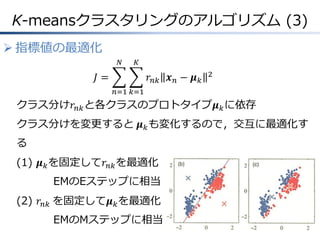
K-meansクラスタリングのアルゴリズム (3) 指標値の最適化 𝑁 𝐾 𝐽= 𝑟
𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 𝑛=1 𝑘=1 クラス分け𝑟 𝑛𝑘 と各クラスのプロトタイプ𝝁 𝑘 に依存 クラス分けを変更すると 𝝁 𝑘 も変化するので,交互に最適化す る (1) 𝝁 𝑘 を固定して𝑟 𝑛𝑘 を最適化 EMのEステップに相当 (2) 𝑟 𝑛𝑘 を固定して𝝁 𝑘 を最適化 EMのMステップに相当
7.
K-meansクラスタリングのアルゴリズム (4) (1) 𝝁
𝑘 を固定して𝑟 𝑛𝑘 を最適化 𝑁 𝐾 𝐽= 𝑟 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 𝑛=1 𝑘=1 𝐾 = 𝐾 𝑟1𝑘 𝒙1 − 𝝁 𝑘 2 + ⋯+ 𝑘=1 𝑟 𝑁𝑘 𝒙 𝑁 − 𝝁 𝑘 2 𝑘=1 • 各項において,𝑟 𝑛𝑘 はK個のうち1つだけが1で,残りは全て0 なので,n番目のデータ𝒙 𝑛 を𝝁 𝑘 が最も近いクラスに割り当て れば各項( 𝒙 𝑛 と𝝁 𝑘 の距離)が最小になる 𝑟 𝑛𝑘 1 = 0 𝑘 = arg min 𝒙 𝑛 − 𝝁 𝑗 𝑗 それ以外 2 (9.2)
8.
K-meansクラスタリングのアルゴリズム (5) (2) 𝑟
𝑛𝑘 を固定して𝝁 𝑘 を最適化 𝑁 𝐾 𝐽= 𝑟 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 𝑛=1 𝑘=1 この指標値𝐽は𝝁 𝑘 に関する2次関数なので, 𝝁 𝑘 に関して偏微分 して0とおくと最小化できる 𝑁 𝐽= 𝑁 𝑟 𝑛1 𝒙 𝑛 − 𝝁1 𝑛=1 𝜕𝐽 𝜕 = 𝜕𝝁 𝑘 𝜕𝝁 𝑘 2 + ⋯+ 𝑟 𝑛𝐾 𝒙 𝑛 − 𝝁 𝐾 𝑛=1 𝑁 𝑟 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 𝑛=1 𝑁 =2 𝑟 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 𝑛=1 𝑁 2 2 𝑟 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 = 0 𝑛=1 (9.3) ⇒ 𝝁𝑘 = 𝑁 𝑛=1 𝑟 𝑛𝑘 𝒙 𝑛 𝑁 𝑛=1 𝑟 𝑛𝑘 (9.4) K番目のクラ スに属する データの和 K番目のクラ スのデータ数
9.
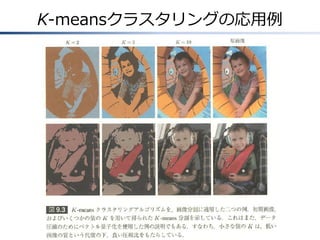
K-meansクラスタリングの応用例
10.
K-medoidsアルゴリズム 一般的な非類似度を指標値したアルゴリズム K-menasアルゴリズムの指標値 𝑁 𝐾 𝐽= 𝑟 𝑛𝑘
𝒙 𝑛 − 𝝁 𝑘 2 𝑛=1 𝑘=1 一般的な非類似度に拡張(K-medoidsアルゴリズム) 𝑁 𝐾 𝐽= 𝑟 𝑛𝑘 𝜈 𝒙 𝑛 , 𝝁 𝑘 𝑛=1 𝑘=1 (9.6) 各クラスのプロトタイプとして,割り当てられたデータベクト ルの中の1つを利用すると,任意のデータに対する非類似度が 定義されている必要がなく,データ間の非類似度が与えられて いれば良い
11.
混合モデルとEMアルゴリズム 「第9章 混合モデルとEM」, C.M.ビショップ, パターン認識と学習(下), シュプリンガー・ジャパン,2007. 9.1 K-meansクラスタリング 9.2
混合ガウス分布(Mixtures of Gaussians) 9.3 EMアルゴリズムのもう一つの解釈 9.4 一般のEMアルゴリズム
12.
混合ガウス分布
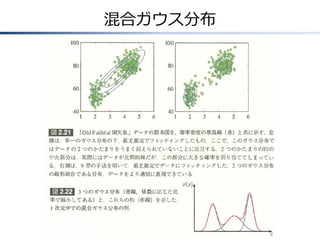
13.
潜在変数を用いた定式化(1) 混合ガウス分布 𝐾 𝑝 𝒙
= ただし,𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 = 𝑘=1 1 1 2𝜋 𝐷 2 (9.7) 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝚺 1 𝒌 2 exp − 1 2 𝒙− 𝝁𝑘 𝑇 𝚺 −1 𝑘 𝒙− 𝝁𝑘 (2.43) 潜在変数による表現 𝐾次元の2値確率変数𝒛: 1-of-K表現, 例)𝒛 = 0, 0, 1, 0, ⋯ , 0 (どれか1つの𝑧 𝑘 だけが1で,他は0) 𝐾 𝑝 𝑧𝑘 = 1 = 𝜋𝑘 0 ≤ 𝜋 𝑘 ≤ 1, 𝜋𝑘 = 1 (9.8), (9.9) 𝑘=1 1-of-K表現の場合,𝑧 𝑘 はどれか1つだけ1となるので, 𝐾 𝑧 𝜋𝑘𝑘 𝑝 𝒛 = 𝑝 𝑧1 , ⋯ , 𝑧 𝐾 = 𝑘=1 (9.10)
14.
潜在変数を用いた定式化(2) 𝒙の条件付き分布 𝒛が与えられた下での𝒙の条件付き分布をガウス分布で与える 𝑝 𝒙|𝑧
𝑘 = 1 = 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 1-of-K表現の場合,𝑧 𝑘 はどれか1つだけ1となるので, 𝐾 𝑝 𝒙|𝒛 = 𝑝 𝒙|𝑧1 , ⋯ , 𝑧 𝐾 = 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑘=1 同時分布 𝑝 𝒙, 𝒛 = 𝑝 𝒛 𝑝 𝒙|𝒛 𝐾 𝐾 𝑧 𝜋𝑘𝑘 = 𝑘=1 𝐾 = 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑘=1 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑘=1 𝑧𝑘 𝑧𝑘 𝑧𝑘 (9.11)
15.
潜在変数を用いた定式化(3) 𝒙の周辺分布 𝑝 𝒙
= 𝑝 𝒙, 𝒛 𝒛 𝐾 = 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝒛 𝑧𝑘 𝑘=1 𝒛の全ての場合( 𝒛 = 1, 0, ⋯ , 0 , 0, 1, 0, ⋯ , 0 , ⋯ , 0, ⋯ , 0, 1 )に ついて和を取ると, 𝑝 𝒙 = 𝜋1 𝑁 𝒙|𝝁1 , 𝚺1 + ⋯ + 𝜋 𝐾 𝑁 𝒙|𝝁 𝐾 , 𝚺 𝐾 𝐾 = 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑘=1 (9.12) 混合ガウス分布
16.
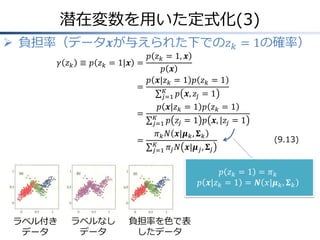
潜在変数を用いた定式化(3) 負担率(データ𝒙が与えられた下での𝑧 𝑘
= 1の確率) 𝛾 𝑧 𝑘 ≡ 𝑝 𝑧 𝑘 = 1|𝒙 = = = = 𝑝 𝑧 𝑘 = 1, 𝒙 𝑝 𝒙 𝑝 𝒙|𝑧 𝑘 = 1 𝑝 𝑧 𝑘 = 1 𝐾 𝑗=1 𝑝 𝒙, 𝑧 𝑗 = 1 𝑝 𝒙|𝑧 𝑘 = 1 𝑝 𝑧 𝑘 = 1 𝐾 𝑗=1 𝑝 𝑧 𝑗 = 1 𝑝 𝒙, |𝑧 𝑗 = 1 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙|𝝁 𝑗 , 𝚺 𝑗 (9.13) 𝑝 𝑧𝑘 = 1 = 𝜋𝑘 𝑝 𝒙|𝑧 𝑘 = 1 = 𝑵 𝑥|𝝁 𝑘 , 𝚺 𝑘 ラベル付き データ ラベルなし データ 負担率を色で表 したデータ
17.
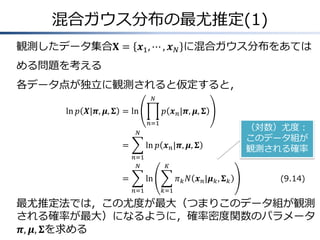
混合ガウス分布の最尤推定(1) 観測したデータ集合𝐗 = 𝒙1
, ⋯ , 𝒙 𝑁 に混合ガウス分布をあては める問題を考える 各データ点が独立に観測されると仮定すると, 𝑁 ln 𝑝 𝑿|𝝅, 𝝁, 𝚺 = ln 𝑝 𝒙 𝑛 |𝝅, 𝝁, 𝚺 𝑛=1 𝑁 = ln 𝑝 𝒙 𝑛 |𝝅, 𝝁, 𝚺 𝑛=1 𝑁 = 𝐾 ln 𝑛=1 (対数)尤度: このデータ組が 観測される確率 𝜋 𝑘 𝑁 𝒙 𝑛 |𝝁 𝑘 , 𝚺 𝑘 (9.14) 𝑘=1 最尤推定法では,この尤度が最大(つまりこのデータ組が観測 される確率が最大)になるように,確率密度関数のパラメータ 𝝅, 𝝁, 𝚺を求める
18.
混合ガウス分布の最尤推定(2) • 混合ガウス分布の対数尤度は,対数がガウス分布に直接作用 するのではなく,ガウス分布の和の対数になるので,対数尤 度の最大化を陽に解くことは難しい • そこで,EMアルゴリズム(Expectation-Maximization
アルゴ リズム)と呼ばれる効率的な繰り返し計算手法を利用する 対数尤度の𝝁 𝑘 による偏微分は, 𝜕 𝜕 ln 𝑝 𝑿|𝝅, 𝝁, 𝚺 = 𝜕𝝁 𝑘 𝜕𝝁 𝑘 𝑁 = 𝑛=1 𝑁 𝑁 𝐾 ln 𝑛=1 𝜋 𝑘 𝑁 𝒙 𝑛 |𝝁 𝑘 , 𝚺 𝑘 𝑘=1 𝜋 𝑘 𝑁 𝒙 𝑛 |𝝁 𝑘 , 𝚺 𝑘 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙 𝑛 |𝝁 𝑗 , 𝚺 𝑗 𝛾 𝑧 𝑛𝑘 𝚺 −1 𝒙 𝑛 − 𝝁 𝑘 𝑘 = 𝑛=1 𝚺 −1 𝒙 𝑛 − 𝝁 𝑘 𝑘 (9.16)
19.
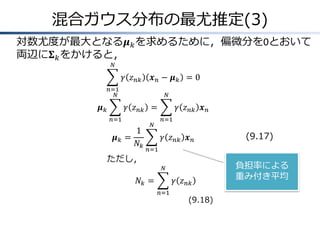
混合ガウス分布の最尤推定(3) 対数尤度が最大となる𝝁 𝑘 を求めるために,偏微分を0とおいて 両辺に𝚺
𝑘 をかけると, 𝑁 𝛾 𝑧 𝑛𝑘 𝒙𝑛− 𝝁𝑘 =0 𝑛=1 𝑁 𝝁𝑘 𝑁 𝛾 𝑧 𝑛𝑘 = 𝑛=1 𝝁𝑘 = 1 𝑁𝑘 ただし, 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 𝑛=1 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 (9.17) 𝑛=1 𝑁 𝑁𝑘 = 𝛾 𝑧 𝑛𝑘 𝑛=1 (9.18) 負担率による 重み付き平均
20.
混合ガウス分布の最尤推定(4) 同様に,共分散行列𝚺 𝑘 に関する偏微分を0とおいて 𝚺𝑘
= 1 𝑁𝑘 𝑁 𝛾 𝑧 𝑛𝑘 𝒙𝑛− 𝝁𝑘 𝒙𝑛− 𝝁𝑘 𝑛=1 𝑻 (9.19) 負担率による 重み付き共分散行列 最後に,混合係数𝜋 𝑘 に関して最大化する 𝐾 ただし, 𝑘=1 𝜋 𝑘 = 1という制約条件を満たさなければいけな いので,ラグランジュ未定乗数法を利用して,以下の指標値を 最大にする𝜋 𝑘 を求める 𝐾 ln 𝑝 𝑿|𝝅, 𝝁, 𝚺 + 𝜆 (9.20) 𝜋𝑘 −1 𝑘=1 対数尤度 ラグランジュ の未定定数 制約条件
21.
混合ガウス分布の最尤推定(5) 𝜋 𝑘 で偏微分して0とおくと, 𝑁 𝑁
𝒙 𝑛 |𝝁 𝑘 , 𝚺 𝑘 𝑛=1 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝑛=1 𝑁 𝒙 𝑛 |𝝁 𝑗 , 𝚺 𝑗 + 𝜆=0 𝛾 𝑧 𝑛𝑘 + 𝜆=0 𝜋𝑘 𝐾 𝑁 𝜆=− 𝛾 𝑧 𝑛𝑘 = −𝑁 (9.21) 𝛾 𝑧 𝑛𝑘 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 = 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙|𝝁 𝑗 , 𝚺 𝑗 𝑘=1 𝑛=1 したがって, 𝑁 𝑛=1 𝜋𝑘 = 𝛾 𝑧 𝑛𝑘 − 𝑁=0 𝜋𝑘 1 𝑁 𝑁 𝛾 𝑧 𝑛𝑘 = 𝑛=1 𝑁𝑘 𝑁 (9.22)
22.
混合ガウス分布の最尤推定(6) まとめると,対数尤度を最大にする混合ガウス分布のパラメータは, 𝑁 1 𝝁𝑘 = 𝑁𝑘 1 𝚺𝑘 = 𝑁𝑘 𝛾
𝑧 𝑛𝑘 𝒙 𝑛 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝑛=1 1 𝜋𝑘 = 𝑁 𝒙𝑛− 𝝁𝑘 𝑁 𝛾 𝑧 𝑛𝑘 𝑛=1 ただし, 𝒙𝑛− 𝝁𝑘 𝑻 𝑁𝑘 = 𝑁 𝛾 𝑧 𝑛𝑘 = 𝑁𝑘 = 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 ,𝚺 𝑘 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙|𝝁 𝑗 ,𝚺 𝑗 𝑁 𝑛=1 𝛾 𝑧 𝑛𝑘 • これらの式から負担率 𝛾 𝑧 𝑛𝑘 が分かればパラメータを求めることができるが, 負担率もパラメータに依存しているため一度に求めることができない • そこで,負担率とパラメータを交互に繰り返し計算する(EMアルゴリズ ム)
23.
混合ガウス分布の最尤推定(7) 混合ガウス分布のためのEMアルゴリズム 1. 平均𝝁 𝑘
,分散𝚺 𝑘 ,混合係数𝜋 𝑘 を初期化する 2. Eステップ:現在のパラメータを使って負担率を計算する 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 (9.23) 𝛾 𝑧 𝑛𝑘 = 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙|𝝁 𝑗 , 𝚺 𝑗 3. Mステップ:現在の負担率を使ってパラメータを更新する 𝑁 1 𝝁𝑘 = 𝑁𝑘 1 𝚺𝑘 = 𝑁𝑘 𝛾 𝑧 𝑛𝑘 𝑛=1 (9.24) 𝑛=1 𝑁 1 𝜋𝑘 = 𝑁 4. 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 𝒙𝑛− 𝝁𝑘 𝑁 𝛾 𝑧 𝑛𝑘 𝑛=1 ただし, 𝒙𝑛− 𝝁𝑘 𝑁𝑘 = 𝑁 𝑻 (9.25) (9.26) 𝑁 𝑁𝑘 = 𝛾 𝑧 𝑛𝑘 𝑛=1 (9.27) 収束性を確認し,収束基準を満たしていない場合,2に戻って繰り返 し計算する
24.
混合モデルとEMアルゴリズム 「第9章 混合モデルとEM」, C.M.ビショップ, パターン認識と学習(下), シュプリンガー・ジャパン,2007. 9.1 K-meansクラスタリング 9.2
混合ガウス分布(Mixtures of Gaussians) 9.3 EMアルゴリズムのもう一つの解釈 9.4 一般のEMアルゴリズム
25.
抽象的なEMアルゴリズム表現(1) EMアルゴリズムの目的 潜在変数をもつモデルについて最尤解(尤度が最大となる確率 密度関数のパラメータ)を求めること 𝑿:観測データの集合 𝒁:潜在変数データの集合 𝜽:全ての確率密度関数のパラメータ組 𝑝 𝑿,
𝒁|𝜽 :パラメータ𝜽が与えられた下でのデータ組 𝑿, 𝒁 の尤度 対数尤度関数 ln 𝑝 𝑿|𝜽 = ln 𝑝 𝑿, 𝒁|𝜽 𝒁 (9.29) 尤度の和の対数と なっているので,ガ ウス分布のような指 数型分布族の場合で も計算が簡単になら ない
26.
抽象的なEMアルゴリズム表現(2) 不完全データに対する対数尤度関数の最大化(1) 実際には観測できない潜在変数𝒁の値が与えられている場合, 𝑿, 𝒁
:完全データ集合 𝑝 𝑿, 𝒁|𝜽 :パラメータ𝜽が与えられた下でのデータ組 𝑿, 𝒁 の尤度 完全データの対数尤度ln 𝑝 𝑿, 𝒁|𝜽 の最大化は簡単にできると仮 定する(最大にする𝜽が簡単に求まる) しかし,実際には不完全データ𝑿だけが与えられ,潜在変数𝒁 については事後確率𝑝 𝒁|𝑿, 𝜽 だけがわかるので,同時分布の対 数尤度ln 𝑝 𝑿, 𝒁|𝜽 の代わりに,𝑝 𝒁|𝑿, 𝜽 に関するln 𝑝 𝑿, 𝒁|𝜽 の 期待値を考える
27.
抽象的なEMアルゴリズム表現(3) 不完全データに対する対数尤度関数の最大化(2) Eステップ: (1) 現在のパラメータ推定値𝜽
𝑜𝑙𝑑 を使って,潜在変数の事後確率 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 を求める (2) 完全データ集合に対する対数尤度ln 𝑝 𝑿, 𝒁|𝜽 の期待値を求める 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 ln 𝑝 𝑿, 𝒁|𝜽 𝑄 𝜽 = (9.30) 𝒁 Mステップ: (3) 𝑄 𝜽 を最大にするパタメータ𝜽を求める → 𝜽 𝑛𝑒𝑤 𝜽 𝑛𝑒𝑤 = arg max 𝑄 𝜽 𝜽 (9.31) ln 𝑝 𝑿, 𝒁|𝜽 の最大化は簡単に計算できると仮定したので,その線形和で 与えられる𝑄 𝜽 の最大化も簡単に計算できる
28.
混合ガウス分布再訪(1) 目的 混合ガウス分布のEMアルゴリズムを,不完全データに対する 対数尤度最大化で説明する 混合ガウス分布における完全データ集合の尤度 混合ガウス分布 𝐾 𝑝
𝒙 = 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑘=1 観測変数と潜在変数の同時分布 𝐾 𝑝 𝒙, 𝒛 = 完全データ集合に対する尤度 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝑧𝑘 𝑘=1 𝑵 𝐾 𝑝 𝑿, 𝒁|𝝁, 𝚺, 𝝅 = 𝜋 𝑘 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝒏=𝟏 𝑘=1 𝑧 𝑛𝑘 (9.35)
29.
混合ガウス分布再訪(2) 潜在変数の事後確率 完全データ集合に対する対数尤度 𝑵 𝑲 ln 𝑝
𝑿, 𝒁|𝝁, 𝚺, 𝝅 = (9.36) 𝑧 𝑛𝑘 ln 𝜋 𝑘 + ln 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝒏=𝟏 𝒌=𝟏 潜在変数𝒁の事後確率 𝑝 𝒁|𝑿, 𝝁, 𝚺, 𝝅 = 𝑝 𝑿, 𝒁|𝝁, 𝚺, 𝝅 /𝑝 𝑿 𝑵 𝐾 ∝ 𝑝 𝑿, 𝒁|𝝁, 𝚺, 𝝅 = 𝜋 𝑘 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝑧 𝑛𝑘 (9.38) 𝒏=𝟏 𝑘=1 この式はnについて積の形をしているので,各𝒛 𝑛 の事後確率は正規化定数も 含めて, 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 = 𝐾 𝑘=1 𝜋 𝑘 𝑁 𝐾 𝒛𝑛 𝑗=1 𝜋 𝑗 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝑁 𝒙 𝒏 |𝝁 𝑗 , 𝚺 𝑗 𝑧 𝑛𝑘 𝑧 𝑛𝑗
30.
混合ガウス分布再訪(3) 潜在変数𝑧 𝑛𝑘
の期待値 → 負担率に一致 事後分布𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 に関する𝑧 𝑛𝑘 の期待値は 𝐸 𝑧 𝑛𝑘 = 𝑧 𝑛𝑘 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 𝒛𝑛 𝐾 𝑘 ′ =1 𝐾 𝒛 𝑛′ 𝑗=1 𝑧 𝑛𝑘 = 𝒛𝑛 = 𝒛𝑛 𝑧 𝑛𝑘 𝒛𝑛 𝐾 𝑘 ′ =1 𝐾 𝑗=1 𝜋 𝑘 ′ 𝑁 𝒙 𝒏 |𝝁 𝑘 ′ , 𝚺 𝑘 ′ 𝜋 𝑗 𝑁 𝒙 𝑛′ |𝝁 𝑗 , 𝚺 𝑗 𝑧 𝑛′ 𝑗 𝑧 𝑛𝑘′ 𝜋 𝑘 ′ 𝑁 𝒙 𝒏 |𝝁 𝑘 ′ , 𝚺 𝑘 ′ 𝜋 𝑗 𝑁 𝒙 𝒏 |𝝁 𝑗 , 𝚺 𝑗 𝑧 𝑛𝑘′ 𝑧 𝑛𝑗 𝒛 𝑛 の全ての場合(𝒛 𝑛 = 1, 0, ⋯ , 0 , 0, 1, 0, ⋯ , 0 , ⋯ , 0, ⋯ , 0, 1 )について和 を取る.分子は𝑧 𝑛𝑘 = 1の項だけのこるので, 𝜋 𝑘 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝐸 𝑧 𝑛𝑘 = 𝐾 = 𝛾 𝑧 𝑛𝑘 𝑗=1 𝜋 𝑗 𝑁 𝒙 𝒏 |𝝁 𝑗 , 𝚺 𝑗 (9.39) 負担率
31.
混合ガウス分布再訪(4) 完全データ集合の対数尤度関数の期待値 𝐸 𝒛
ln 𝑝 𝑿, 𝒁|𝝁, 𝚺, 𝝅 = 𝑝 𝒁|𝑿, 𝝁, 𝚺, 𝝅 ln 𝑝 𝑿, 𝒁|𝝁, 𝚺, 𝝅 𝒛 Nに関して独立 なので = 𝑁 𝑝 𝒁|𝑿, 𝝁, 𝚺, 𝝅 𝒛 𝑁 ln 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝝁, 𝚺, 𝝅 𝑛=1 = 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 ln 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝝁, 𝚺, 𝝅 𝑛=1 𝒛 𝒏 𝑵 𝑲 = = 𝑧 𝑛𝑘 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 ln 𝜋 𝑘 + ln 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝒏=𝟏 𝒌=𝟏 𝒛 𝒏 𝑵 𝑲 = ln 𝜋 𝑘 + ln 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝒏=𝟏 𝒌=𝟏 𝑵 𝑧 𝑛𝑘 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 𝒛𝑛 𝑲 = 𝛾 𝑧 𝑛𝑘 ln 𝜋 𝑘 + ln 𝑁 𝒙 𝒏 |𝝁 𝑘 , 𝚺 𝑘 𝒏=𝟏 𝒌=𝟏 (9.40)
32.
混合ガウス分布再訪(5) 混合ガウス分布のためのEMアルゴリズム 1. 平均𝝁 𝑘
,分散𝚺 𝑘 ,混合係数𝜋 𝑘 を初期化する 2. Eステップ:現在のパラメータを使って負担率を計算する(潜在変数𝑧 𝑛𝑘 の 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝚺, 𝝅 に関する期待値) 𝜋 𝑘 𝑁 𝒙|𝝁 𝑘 , 𝚺 𝑘 𝛾 𝑧 𝑛𝑘 = 𝐾 𝑗=1 𝜋 𝑗 𝑁 𝒙|𝝁 𝑗 , 𝚺 𝑗 3. Mステップ:現在の負担率を使ってパラメータを更新する(これらの更新式は, 完全データ集合対数尤度関数期待値をパラメータで偏微分して0とおくと導出で きる) 𝝁𝑘 = 𝚺𝑘 = 1 𝑁𝑘 1 𝑁𝑘 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝑛=1 𝜋𝑘 = 4. 𝑁 1 𝑁 𝒙𝑛− 𝝁𝑘 𝑻 ただし, 𝑁 𝑁 𝛾 𝑧 𝑛𝑘 = 𝑛=1 𝒙𝑛− 𝝁𝑘 𝑁𝑘 𝑁 𝑁𝑘 = 収束基準を満たしていない場合,2に戻って繰り返し計算する 𝛾 𝑧 𝑛𝑘 𝑛=1
33.
K-meansとの関連 混合ガウス分布のモデルにおいて,各ガウス要素の共分散行列が𝜖𝑰で与え られる場合を考える 1 1 𝑝 𝒙|𝝁 𝑘
, 𝚺 𝑘 = exp − 𝒙− 𝝁𝑘 2 (9.41) 𝐷 2𝜖 2𝜋𝜖 2 このとき,負担率は, 𝒙𝑛− 𝝁𝑘 2 𝜋 𝑘 exp − 2𝜖 𝛾 𝑧 𝑛𝑘 = 2 (9.42) 𝒙 𝑛 − 𝝁𝑗 𝜋 𝑗 exp − 𝑗 2𝜖 𝜖 → 0の極限を考えると,分母は 𝒙 𝑛 − 𝝁 𝑗 が最小になるjに対して最も遅く0 に近づくため,𝛾 𝑧 𝑛𝑘 は 𝒙 𝑛 − 𝝁 𝑘 が最小になるkに対して1に収束し,それ 以外に対しては0に収束する → クラスへのハード割り当て(単一のガウス分布に各データを割り当て) となり,K-meansクラスタリングと一致する(平均ベクトルの更新式も一致 する)
34.
混合ベルヌーイ分布(1) 混合ベルヌーイ分布(潜在クラス分析) 混合ガウス分布:ガウス分布の線形和(連続値の分布) 混合ベルヌーイ分布:ベルヌーイ分布の線形和(2値変数の分布) ベルヌーイ分布 D個の2値変数からなるベクトル:𝒙
= 𝑥1 , ⋯ , 𝑥 𝐷 𝑇 各変数は0/1のみとる ベルヌーイ分布のパラメータベクトル: 𝝁 = 𝜇1 , ⋯ , 𝜇 𝐷 𝑇 𝐷 𝑝 𝒙|𝝁 = 𝜇𝑖 𝑥𝑖 1 − 𝜇𝑖 1−𝑥 𝑖 (9.44) 𝑖=1 𝝁が与えられているとき,各変数𝑥 𝑖 は独立である(𝑝 𝒙|𝝁 が各変数の積で与 えられるため) 期待値:𝐸 𝒙 = 𝝁 共分散:cov 𝒙 = 𝑑𝑖𝑎𝑔 𝜇 𝑖 (1 − 𝜇 𝑖 ) 各変数の分散がμ(1-μ)で, 独立なので非対角成分は0 (9.45), (9.46)
35.
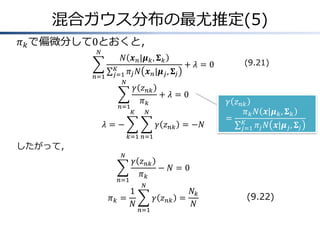
混合ベルヌーイ分布(2) 混合ベルヌーイ分布(潜在クラス分析) ベルヌーイ分布の有限混合分布 𝐾 𝑝 𝒙|𝝁,
𝝅 = 𝐾 𝐷 𝜋 𝑘 𝑝 𝒙|𝝁 𝑘 = 𝑘=1 𝑥 𝜇 𝑘𝑖𝑖 1 − 𝜇 𝑘𝑖 𝜋𝑘 𝑘=1 1−𝑥 𝑖 (9.47) 𝑖=1 混合分布の期待値と分散は, 𝐾 𝑘=1 期待値:𝐸 𝒙 = 共分散:cov 𝒙 = (9.49) 𝝅𝑘 𝝁𝑘 𝐾 𝑘=1 𝑇 𝝅 𝑘 𝚺 𝑘 + 𝝁 𝑘 𝝁 𝑘 − 𝐸 𝒙 𝐸 𝒙 𝑇] (9.50) 対数尤度関数 𝑁 ln 𝑝 𝑿|𝝁, 𝝅 = 𝐾 ln 𝑛=1 𝜋 𝑘 𝑝 𝒙|𝝁 𝑘 𝑘=1 対数の中に和の形が現れ,最尤解を陽の形で求められない →EMアルゴリズムで解く (9.51)
36.
混合ベルヌーイ分布(3) 潜在変数による表現 𝐾次元の2値確率変数𝒛 =
𝑧1 , ⋯ , 𝑧 𝑛 : 1-of-K表現, 例)𝒛 = 0, 0, 1, 0, ⋯ , 0 𝒛が与えられてた下での𝒙の条件付き分布は 𝐾 𝑝 𝒙|𝒛, 𝝁 = 𝐾 𝑝 𝒙|𝝁 𝑘 𝑧𝑘 𝑘=1 𝑧𝑘 𝐷 𝑥 𝜇 𝑘𝑖𝑖 1 − 𝜇 𝑘𝑖 = 𝑘=1 1−𝑥 𝑖 (9.52) 𝑖=1 ただし,潜在変数についての事前分布𝑝 𝒛|𝝅 は 𝐾 (9.53) 𝑧 𝜋𝑘𝑘 𝑝 𝒛|𝝅 = 𝑘=1 観測変数と潜在変数の同時分布 𝐾 𝑝 𝒙, 𝒛|𝝁, 𝝅 = 𝑝 𝒙|𝒛, 𝝁 𝑝 𝒛|𝝅 = 𝑘=1 𝐾 = 𝑘=1 𝑧𝑘 𝐷 𝜋𝑘 𝜇𝑖 𝑖=1 𝑥𝑖 𝑧𝑘 𝜋 𝑘 𝑝 𝒙|𝝁 𝑘 1 − 𝜇𝑖 1−𝑥 𝑖
37.
混合ベルヌーイ分布(4) 完全データ集合に対する対数尤度関数 したがって,完全データ集合に対する対数尤度関数は, 𝑁 ln 𝑝
𝑿, 𝒁|𝝁, 𝝅 = ln 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝝁, 𝝅 𝑛=1 𝑁 𝐾 = 𝐷 𝑥 𝜇 𝑘𝑖𝑛𝑖 1 − 𝜇 𝑘𝑖 𝑧 𝑛𝑘 ln 𝜋 𝑘 𝑛=1 𝑘=1 𝑁 𝑖=1 𝐾 = (9.54) 𝐷 𝑧 𝑛𝑘 ln 𝜋 𝑘 + 𝑛=1 𝑘=1 1−𝑥 𝑛𝑖 𝑥 𝑛𝑖 ln 𝑢 𝑘𝑖 + 1 − 𝑥 𝑛𝑖 ln 1 − 𝜇 𝑘𝑖 𝑖=1 潜在変数の事後確率と負担率はガウス混合分布と同様に導出して, 𝐾 𝑧 𝑛𝑘 𝑘=1 𝜋 𝑘 𝑝 𝒙 𝒏 |𝝁 𝑘 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝝁, 𝝅 = 𝑧 𝑛𝑗 𝐾 𝜋 𝑗 𝑝 𝒙 𝒏 |𝝁 𝑗 𝒛𝑛 𝑗=1 𝜋 𝑘 𝑝 𝒙 𝒏 |𝝁 𝑘 𝐸 𝑧 𝑛𝑘 = 𝐾 = 𝛾 𝑧 𝑛𝑘 (9.56) 𝑗=1 𝜋 𝑗 𝑝 𝒙 𝒏 |𝝁 𝑗
38.
混合ベルヌーイ分布(5) 潜在変数の事後確率に関する完全データ集合対数尤度関数の 期待値 𝐸 𝒁
ln 𝑝 𝑿, 𝒁|𝝁, 𝝅 𝑁 𝐾 = 𝐷 𝛾 𝑧 𝑛𝑘 ln 𝜋 𝑘 + 𝑛=1 𝑘=1 𝑥 𝑛𝑖 ln 𝜇 𝑘𝑖 + 1 − 𝑥 𝑛𝑖 ln 1 − 𝜇 𝑘𝑖 𝑖=1 対数尤度の最大化 (9.55) 上式を𝝁 𝑘 に関して偏微分して0とおいて整理すると 1 𝝁𝑘 = 𝑁𝑘 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 𝑛=1 (9.59) 𝑁 ただし,𝑁 𝑘 = 𝑛=1 𝛾 𝑧 𝑛𝑘 同様に,𝜋 𝑘 に関しても 𝑘 𝜋 𝑘 = 1を制約としたラグランジュ未定乗数法を用 いて, 𝜋 𝑘 に関する偏微分を0とおいて整理すると 𝑁𝑘 (9.60) 𝜋𝑘 = 𝑁
39.
混合ベルヌーイ分布の例
40.
混合モデルとEMアルゴリズム 「第9章 混合モデルとEM」, C.M.ビショップ, パターン認識と学習(下), シュプリンガー・ジャパン,2007. 9.1 K-meansクラスタリング 9.2
混合ガウス分布(Mixtures of Gaussians) 9.3 EMアルゴリズムのもう一つの解釈 9.4 一般のEMアルゴリズム
41.
一般のEMアルゴリズム(1) EMアルゴリズムの目的 観測されない潜在変数があるときの尤度関数最大化 𝑝 𝑿|𝜽
= (9.69) 𝑝 𝑿, 𝒁|𝜽 𝒁 これを直接最適化することは難しいが,完全データ対数尤度関数 ln 𝑝 𝑿, 𝒁|𝜽 の最適化は容易であると仮定する 尤度関数の分解 ただし, ln 𝑝 𝑿|𝜽 の下界 ln 𝑝 𝑿|𝜽 = 𝐿 𝑞, 𝜽 + 𝐾𝐿 𝑞||𝑝 (9.70) 𝑝 𝑿, 𝒁|𝜽 𝑞 𝒁 (9.71) 𝐿 𝑞, 𝜽 = 𝑞 𝒁 ln 𝒁 𝐾𝐿 𝑞||𝑝 = − 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁 ln 𝑞 𝒁 (9.72) 𝑝 𝑍|𝑋, 𝜃 と𝑞 𝑍 のKullback-Leiblerダイバージェンス
42.
一般のEMアルゴリズム(2) 尤度関数分解の導出 𝐿 𝑞,
𝜽 + 𝐾𝐿 𝑞||𝑝 = 𝒁 = 𝒁 = 𝑝 𝑿, 𝒁|𝜽 𝑞 𝒁 ln 𝑞 𝒁 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑝 𝑿|𝜽 𝑞 𝒁 ln 𝑞 𝒁 𝑞 𝒁 ln 𝒁 = − 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁 𝑞 𝒁 ln 𝑝 𝑿|𝜽 𝒁 = ln 𝑝 𝑿|𝜽 = ln 𝑝 𝑿|𝜽 𝑞 𝒁 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁 ln 𝑞 𝒁 − 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁 ln 𝑞 𝒁 + ln 𝑝 𝑿|𝜽 − ln 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁
43.
一般のEMアルゴリズム(3) 尤度関数の分解 ln 𝑝
𝑿|𝜽 = 𝐿 𝑞, 𝜽 + 𝐾𝐿 𝑞||𝑝 ただし, 𝑝 𝑿, 𝒁|𝜽 𝐿 𝑞, 𝜽 = 𝑞 𝒁 ln 𝑞 𝒁 𝒁 𝐾𝐿 𝑞||𝑝 = − 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑞 𝒁 ln 𝑞 𝒁 EMアルゴリズム Eステップ 現在のパラメータ𝜽 𝑜𝑙𝑑 を固定して𝑞 𝒁 について𝐿 𝑞, 𝜽 を最大化する. ln 𝑝 𝑿|𝜽 𝑜𝑙𝑑 は𝑞 𝒁 に依存せず,KLダイバージェンスが必ず0以上なので, 𝐿 𝑞, 𝜽 は𝐾𝐿 𝑞||𝑝 = 0のとき最大となる.すなわち𝑞 𝒁 = 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 . Mステップ 𝑞 𝒁 を固定して𝐿 𝑞, 𝜽 を𝜽について最大化する. 𝑝 𝒁|𝑿, 𝜽 𝑛𝑒𝑤 は𝑞 𝒁 と一致するとは限らず0以上の値をとる.つまり, 𝐿 𝑞, 𝜽 を𝜽について最大化することにより,ln 𝑝 𝑿|𝜽 は必ず増加する.
44.
一般のEMアルゴリズム(4) Mステップにおける𝐿 𝑞,
𝜽 𝐿 𝑞, 𝜽 = 𝒁 𝑝 𝑿, 𝒁|𝜽 𝑞 𝒁 ln 𝑞 𝒁 にEステップで推定された𝑞 𝒁 = 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 を代入して, 𝑝 𝑿, 𝒁|𝜽 𝑜𝑙𝑑 ln 𝐿 𝑞, 𝜽 = 𝑝 𝒁|𝑿, 𝜽 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 ln 𝑝 𝑿, 𝒁|𝜽 − = 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 ln 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 𝒁 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 ln 𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 = 𝐸 𝒛 ln 𝑝 𝑿, 𝒁|𝜽 − 𝒁 (9.74) 第2項目は𝜽に依存しないので,Mステップの最適化には関係ない. つまり,第1項目の完全データ対数尤度の事後確率𝑝 𝒁|𝑿, 𝜽 𝑜𝑙𝑑 に関する期 待値を最大化することになり,前で説明したEMアルゴリズムと一致する
45.
一般のEMアルゴリズム(5) Eステップにおける計算される事後確率 データ集合が独立同分布(i.i.d.)から得られている場合は, 𝑝 𝑿,
𝒁|𝜽 𝑝 𝒁|𝑿, 𝜽 = 𝒁 𝑝 𝑿, 𝒁|𝜽 𝑁 𝑛=1 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝜽 = 𝑁 𝑛=1 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝜽 𝒁 𝑁 𝑛=1 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝜽 = 𝑁 𝑛=1 𝒛 𝒏 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝜽 𝑁 = 𝑛=1 𝑁 = 𝑍はnに関して 独立なので 𝑝 𝒙 𝑛 , 𝒛 𝑛 |𝜽 𝒑 𝒙 𝑛 |𝜽 𝑝 𝒛 𝑛 |𝒙 𝑛 , 𝜽 (9.75) 𝑛=1 この計算は,前で説明した潜在変数の事後確率の計算に対応している
46.
まとめ 「第9章 混合モデルとEM」, C.M.ビショップ, パターン認識と学習(下), シュプリンガー・ジャパン,2007. • 混合ガウス分布に代表される潜在変数のモデルを説明した •
潜在変数を用いたモデルの最尤推定を行うための効率的な手 法がEMアルゴリズムである • EMアルゴリズムは,混合ガウス分布だけではなく,様々な モデルに適用出来る汎用的な手法である
Download


























![混合ベルヌーイ分布(2)
混合ベルヌーイ分布(潜在クラス分析)
ベルヌーイ分布の有限混合分布
𝐾
𝑝 𝒙|𝝁, 𝝅 =
𝐾
𝐷
𝜋 𝑘 𝑝 𝒙|𝝁 𝑘 =
𝑘=1
𝑥
𝜇 𝑘𝑖𝑖 1 − 𝜇 𝑘𝑖
𝜋𝑘
𝑘=1
1−𝑥 𝑖
(9.47)
𝑖=1
混合分布の期待値と分散は,
𝐾
𝑘=1
期待値:𝐸 𝒙 =
共分散:cov 𝒙 =
(9.49)
𝝅𝑘 𝝁𝑘
𝐾
𝑘=1
𝑇
𝝅 𝑘 𝚺 𝑘 + 𝝁 𝑘 𝝁 𝑘 − 𝐸 𝒙 𝐸 𝒙 𝑇]
(9.50)
対数尤度関数
𝑁
ln 𝑝 𝑿|𝝁, 𝝅 =
𝐾
ln
𝑛=1
𝜋 𝑘 𝑝 𝒙|𝝁 𝑘
𝑘=1
対数の中に和の形が現れ,最尤解を陽の形で求められない
→EMアルゴリズムで解く
(9.51)](https://image.slidesharecdn.com/20131113em-131115041121-phpapp02/85/EM-PRML-35-320.jpg)





























![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)











