7/50
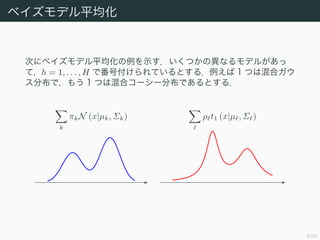
ベイズモデル平均化
モデルに関する事前確率が p (h)で与えられているならば,データに関
する周辺分布は次式で求められる.
p (X) =
H
h=1
p (X|h) p (h) (14.6)
モデル結合との違いは,データを生成しているのはモデル h = 1, . . . , H
のどれか 1 つだということである.
9/50
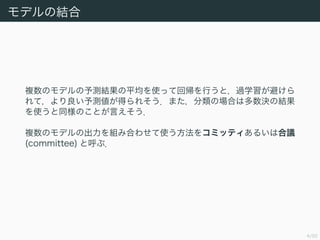
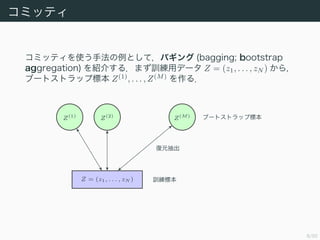
コミッティ
バギングにおけるコミッティの予測値 yCOM (x)は,各ブートストラッ
プ集合 Z(1)
, . . . , Z(M)
で学習したモデルの予測 y1 (x) , . . . , yM (x) を
使って
yCOM (x) =
1
M
M
m=1
ym (x) (14.7)
となる.
これで実際に良い結果が得られるのか,誤差を評価して確認する.
10.
10/50
バギングの誤差評価
予測したい回帰関数を h (x)とし,各モデルの予測値 ym (x) が,h (x)
と加法的な誤差 εm (x) を使って
ym (x) = h (x) + εm (x) (14.8)
と表せると仮定する.このとき,二乗誤差は
E (ym (x) − h (x))
2
= E (εm (x))
2
(14.9)
となるので,平均二乗誤差の期待値 EAV は
EAV := E
1
M
M
m=1
(ym (x) − h (x))
2
=
1
M
M
m=1
E (εm (x))
2
(14.10)
で求められる.
11.
11/50
バギングの誤差評価
一方,コミッティによる出力について,誤差の期待値 ECOM は
ECOM:= E
1
M
M
m=1
ym − h (x)
2
= E
1
M
M
m=1
εm (x)
2
(14.11)
と求められる.ベクトル (1 · · · 1) ∈ RM
と (ε1 (x) · · · εm (x)) ∈ RM
に対して Cauchy-Schwarz の不等式を用いると
M
m=1
εm (x)
2
≤ M
M
m=1
(εm (x))
2
ECOM ≤ EAV
が成り立つ.つまりコミッティを使う場合の誤差の期待値は,構成要素
の誤差の期待値の和を超えない.
12.
12/50
バギングの誤差評価
特に誤差の平均が 0 で無相関である,すなわち
E[εm (x)] = 0 (14.12)
cov (εm (x) , ε (x)) = E [εm (x) ε (x)] = 0, m = (14.13)
が成り立つならば 1
ECOM = E
1
M
M
m=1
εm (x)
2
=
1
M2
E
M
m=1
(εm (x))
2
=
1
M
EAV (14.14)
となり,誤差の期待値が大幅に低減される.
1 同じようなモデルを,同じような訓練データで学習させているのだから,こんなことは
期待できない.
14/50
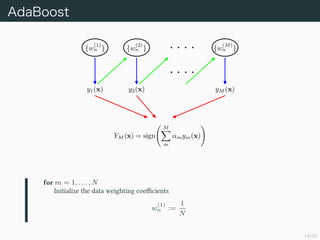
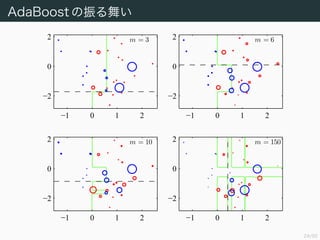
AdaBoost
{w
(1)
n } {w
(2)
n} {w
(M)
n }
y1(x) y2(x) yM (x)
YM (x) = sign
M
m
αmym(x)
for m = 1, . . . , N
Initialize the data weighting coefficients
w
(1)
n :=
1
N
15.
15/50
AdaBoost
for m =1, . . . , M
Fit a classifier ym (x) to the training data by minimizing
Jm :=
N
n=1
w
(m)
n 1{x | ym(x)=tn} (xn) . (14.15)
Evaluate
αm := log
1 − εm
εm
(14.17)
where
εm :=
N
n=1
w
(m)
n 1{x | ym(x)=tn} (xn)
N
n=1
w
(m)
n
. (14.15)
Update the data weighting coefficients
w
(m+1)
n := w
(m)
n exp αm1{x|ym(xn)=tn} (xn) . (14.18)
17/50
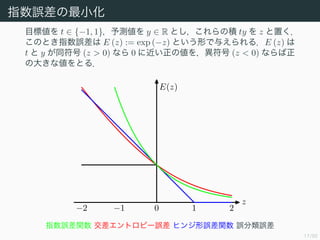
指数誤差の最小化
目標値を t ∈{−1, 1},予測値を y ∈ R とし,これらの積 ty を z と置く.
このとき指数誤差は E (z) := exp (−z) という形で与えられる.E (z) は
t と y が同符号 (z > 0) なら 0 に近い正の値を,異符号 (z < 0) ならば正
の大きな値をとる.
−2 −1 0 1 2
z
E(z)
指数誤差関数 交差エントロピー誤差 ヒンジ形誤差関数 誤分類誤差
18.
18/50
指数誤差の最小化
以下の誤差 E を最小化したい.
E:=
N
n=1
exp −tn
m
=1
1
2
α y (xn)
逐次的に学習していくので α1, . . . , αm−1 と y1 (x) , . . . , ym−1 (x) は所与
として,αm と ym (x) に関して E を最小化する.E を
E =
N
n=1
exp −tn
m−1
=1
1
2
α y (xn) −
1
2
tnαmym (xn)
=
N
n=1
w(m)
n exp −
1
2
tnαmym (xn) (14.22)
と書き換える.ここで以下のように置いた.
w(m)
n := exp −tn
m−1
=1
1
2
α y (xn) (14.22 )
19.
19/50
指数誤差の最小化
ym : x→ {−1, 1} によって正しく分類されたデータ点の添字集合を Tm,
誤って分類されたデータの添字集合を Mm とする.このとき
E = e−αm/2
n∈Tm
w(m)
n + eαm/2
n∈Mm
w(m)
n
= eαm/2
− e−αm/2
N
n=1
w(m)
n 1{x|ym(xn)=tn} (xn)
+ e−αm/2
N
n=1
w(m)
n (14.23)
が成り立つ.これを ym (x) について最小化することは (14.15) を最小化
することと同値である.
20.
20/50
指数誤差の最小化
また αm について微分して0 と置くと
eαm/2
+ e−αm/2
N
n=1
w(m)
n 1{x|ym(xn)=tn} (xn) − e−αm/2
N
n=1
w(m)
n = 0
eαm
+ 1 =
N
n=1
w(m)
n
N
n=1
w(m)
n 1{x|ym(xn)=tn} (xn)
となる.(14.15) と同じ置き換えを行うことにより
αm = log
1 − εm
εm
を得る.これはアルゴリズム中の (14.17) に等しい.
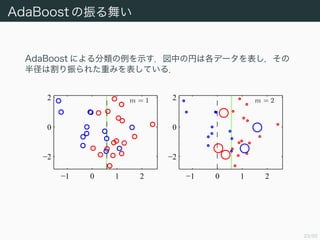
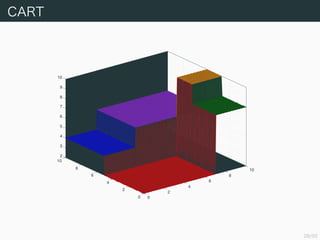
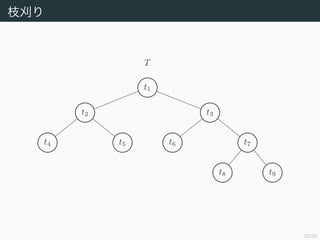
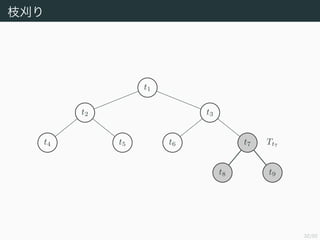
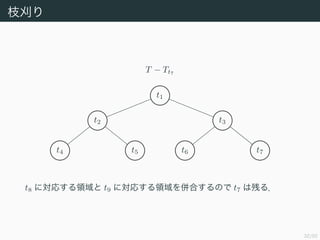
35/50
枝刈り
部分木 Tt と節点t から下を刈ってできる木 ({t} , ∅) の
error-complexity measure はそれぞれ
Rα (Tt) = R (Tt) + α Tt ,
Rα (({t} , ∅)) = R (({t} , ∅)) + α
である.Rα (Tt) > Rα(({t} , ∅)),すなわち
α <
R (Tt) − R (({t} , ∅))
Tt − 1
が成り立つならば刈り取ったほうがよい.この右辺を刈り取る効果の指
標とし
g (t ; T) :=
R (Tt) − R (({t} , ∅))
Tt − 1
と定める.
38.
36/50
枝刈り
次の最弱リンク枝刈り (weakest linkpruning) と呼ばれるアルゴリズ
ムにより T0
· · · TJ
= ({t1} , ∅) と狭義単調増加列 α0 < · · · < αJ
を得る.
1: i ← 0
2: while Ti > 1
3: αi ← min
t∈V (T i)T i
g t ; Ti
4: T i
← arg min
t∈V (T i)T i
g t ; Ti
5: for t ∈ T i
6: Ti
← Ti
− Ti
t
7: i ← i + 1
39.
37/50
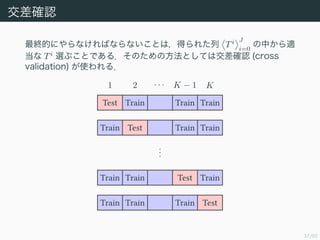
交差確認
最終的にやらなければならないことは,得られた列 Ti J
i=0
の中から適
当なTi
選ぶことである.そのための方法としては交差確認 (cross
validation) が使われる.
Test
Train
Train
Train
Train
Test
Train
Train
...
Train
Train
Test
Train
Train
Train
Train
Test
1 2 · · · K − 1 K
40.
38/50
交差確認
手順は以下のようになる.
1: データ Dを使って,木の列 Ti J
i=0
とパラメータの列 αi
J
i=0 を
作る.
2: データ D を D =
K
k=1 Dk と分割する.極力,各 |Dk| が同じ大きさ
になるようにする.
3: 各 D(k)
:= DDk を使い,木の列 T(k)i ik
i=0
とパラメータの列
α
(k)
i
ik
i=0
を作る.
41.
39/50
交差確認
4: 各 αi:=
√
αiαi+1 に対して Rαi
(T) を最小化するような
T(1)
(αi) , . . . , T(K)
(αi) とそれらに対応する予測 y
(1)
i , . . . , y
(K)
i を求
める.ここで α ∈ α
(k)
i , α
(k)
i+1 ならば T(k)
(α) = T(k)i
となること
に注意する.
5: 今までの結果から以下を求めることができる.
RCV
Ti
=
1
N
K
k=1 n∈{n ; (xn,tn)∈Dk}
tn − y
(k)
i (xn)
2
6: 誤差が一番小さい木を T∗∗
:= arg minT i R Ti
とする.
42.
40/50
交差確認
7: 標準誤差 (standarderror) SE を求める.
SE RCV
Ti
:= s Ti
/
√
N,
s Ti
:=
1
N
N
n=1
tn − y
(κ(n))
i (xn)
2
− RCV (Ti)
2
,
κ (n) =
K
k=1
k1Dk
((xn, tn))
8: 以下を満たす T の中で最小の木 T∗
を最終的な結果とする.
RCV
(T) ≤ RCV
(T∗∗
) + 1 × SE (T∗∗
)
このヒューリスティックな決め方は 1 SE rule と呼ばれる.
42/50
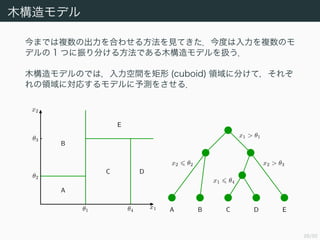
CART による分類
次に分類を扱う.手順は回帰とほぼ同様なので,分割の基準だけ扱う.
C1, .. . , CK の K クラスに分類する問題を解きたいとする.節点 t を
通って流れていくデータの数を N (t) とする.またそれらのうちで Ck
に属するものの数を Nk (t) と表す.このとき
p (t|Ck) =
Nk (t)
Nk
,
p (Ck, t) = p (Ck) p (t|Ck) =
Nk
N
Nk (t)
Nk
=
Nk (t)
N
,
p (t) =
K
k=1
p (Ck, t) =
N (t)
N
である.よって事後確率 p (Ck|t) は次のように求められる.
p (Ck|t) =
p (Ck, t)
p (t)
=
Nk (t)
N (t)
50/50
参考文献
Bishop, C. M.(2006). Pattern Recognition and Machine
Learning. Springer.
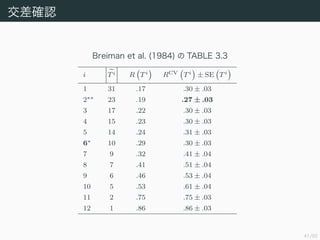
Breiman, L., Friedman, J., Stone, C. J., and Olshen, R. A.
(1984). Classification and regression trees. CRC press.
Freund, Y. and Schapire, R. E. (1996). Experiments with a new
boosting algorithm.
Friedman, J., Hastie, T., Tibshirani, R., et al. (2000). Additive
logistic regression: a statistical view of boosting (with
discussion and a rejoinder by the authors). The annals of
statistics.
Hastie, T., Tibshirani, R., and Friedman, J. (2009). The
Elements of Statistical Learning: data mining, inference and
prediction. Springer, second edition.
Murphy, K. P. (2012). Machine Learning: A Probabilistic
Perspective.
平井有三 (2012). はじめてのパターン認識. 森北出版.








![12/50
バギングの誤差評価
特に誤差の平均が 0 で無相関である,すなわち
E [εm (x)] = 0 (14.12)
cov (εm (x) , ε (x)) = E [εm (x) ε (x)] = 0, m = (14.13)
が成り立つならば 1
ECOM = E
1
M
M
m=1
εm (x)
2
=
1
M2
E
M
m=1
(εm (x))
2
=
1
M
EAV (14.14)
となり,誤差の期待値が大幅に低減される.
1 同じようなモデルを,同じような訓練データで学習させているのだから,こんなことは
期待できない.](https://image.slidesharecdn.com/prml14-150925085543-lva1-app6892/85/PRML-14-12-320.jpg)






![22/50
ブースティングのための誤差関数
以下の指数誤差を考える.
E [exp (−ty (x))] =
t∈{−1,1}
exp (−ty (x)) p (t|x) p (x) dx (14.27)
変分法を使って y について上式を最小化する.
ϕt (y) := exp (−ty (x)) p (t|x) p (x) とする.停留点は以下のように求め
られる.
t∈{−1,1}
Dyϕt (y) = 0
exp (y (x)) p (t = −1|x) − exp (−y (x)) p (t = 1|x) = 0
y (x) =
1
2
log
p (t = 1|x)
p (t = −1|x)
(14.28)
つまり AdaBoost は逐次的に p (t = 1|x) と (t = −1|x) の比の対数の近
似を求めている.これが最終的に (14.19) で符号関数を使って分類器を
作った理由となっている.](https://image.slidesharecdn.com/prml14-150925085543-lva1-app6892/85/PRML-14-22-320.jpg)


























![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





























