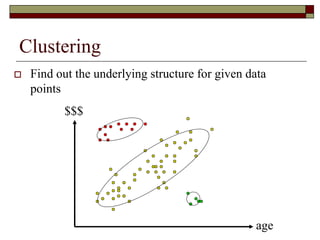
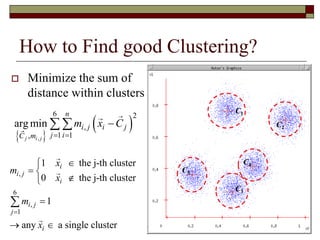
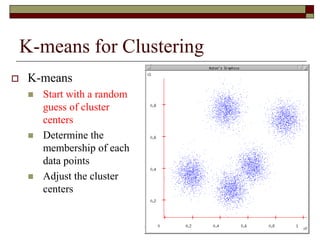
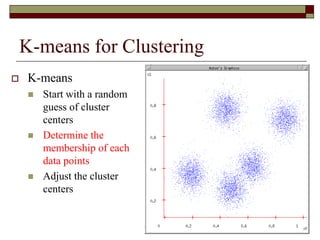
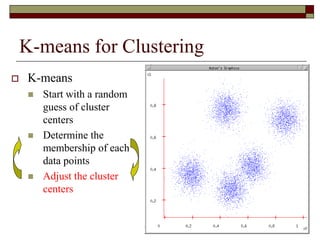
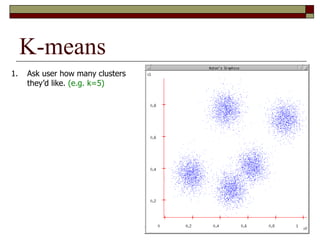
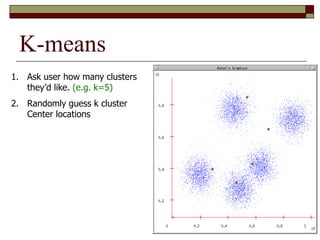
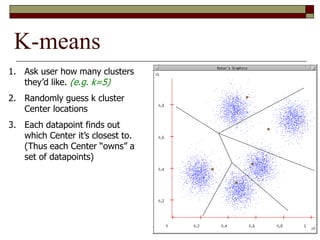
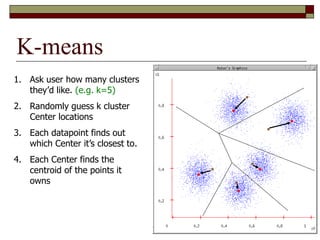
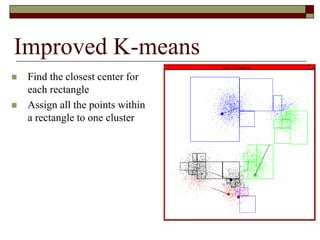
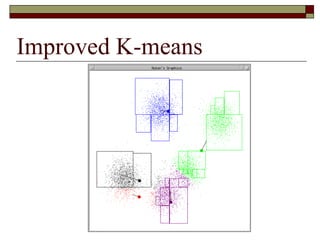
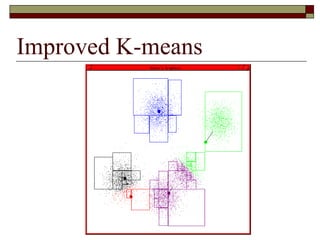
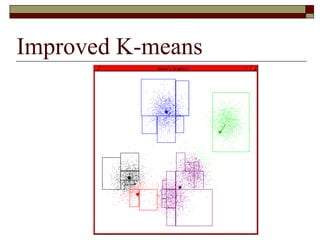
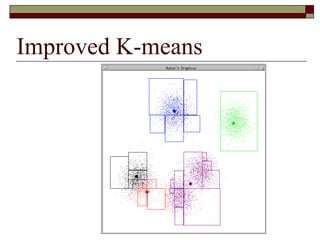
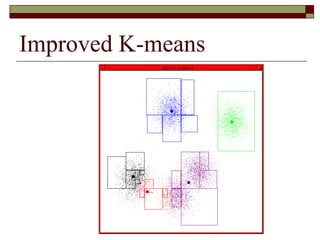
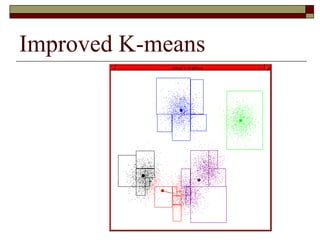
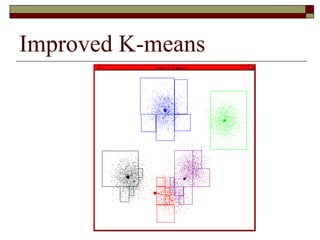
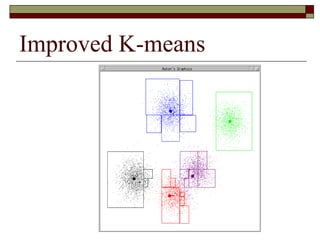
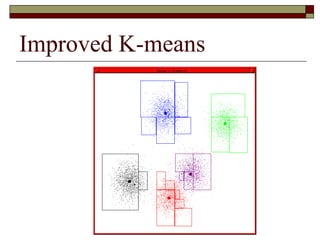
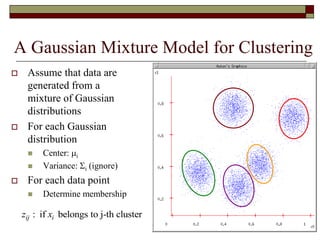
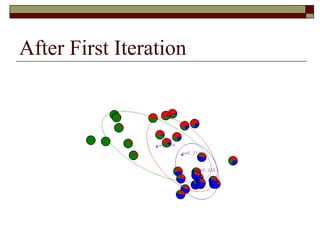
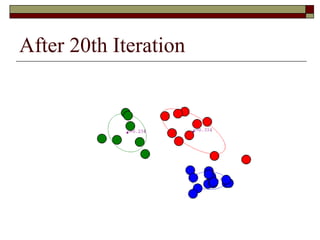
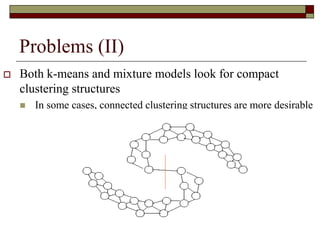
This document provides an overview of clustering techniques including k-means clustering, expectation maximization algorithms, and spectral clustering. It discusses how k-means clustering works by initializing random cluster centers, assigning data points to the closest centers, and adjusting the centers iteratively. Expectation maximization is presented as a way to learn the parameters of a Gaussian mixture model to cluster data. Finally, applications of clustering like document clustering using mixture models are briefly described.






![Learning a Gaussian Mixture
(with known covariance)
2
2
2
2
1
( )
2
1
( )
2
1
( )
( )
i j
i n
x
j
k x
n
n
e p
e p
[ ] ( | )ij j iE z p x x E-Step
1
( | ) ( )
( | ) ( )
i j j
k
i n j
n
p x x p
p x x p
](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-33-320.jpg)
![Learning a Gaussian Mixture
(with known covariance)
1
1
1
[ ]
[ ]
m
j ij im
i
ij
i
E z x
E z
M-Step
1
1
( ) [ ]
m
j ij
i
p E z
m
](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-34-320.jpg)

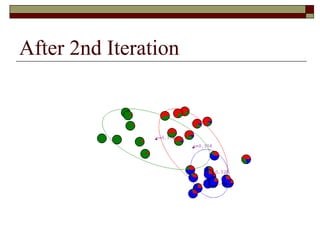
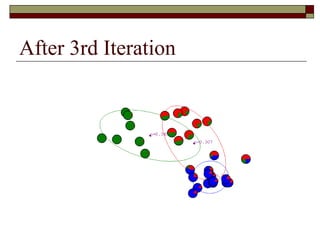
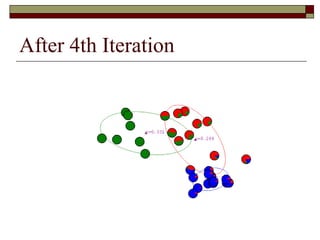
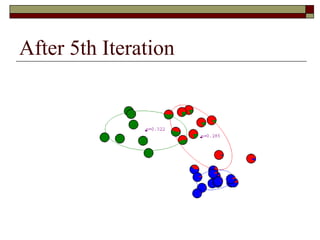





![Learning a Mixture Model
( , )
1
( , )
1 1
( | ) ( )
( | ) ( )
k i
k i
V tf w d
m j j
m
VK
tf w d
m n n
n m
p w p
p w p
1
[ ] ( | )
( | ) ( )
( | ) ( )
ij j i
i j j
K
i n n
n
E z p d d
p d d p
p d d p
E-Step
K: number of language models](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-47-320.jpg)
![Learning a Mixture Model
M-Step
1
1
( ) [ ]
N
j ij
i
p E z
N
1
1
[ ] ( , )
( | )
[ ]
N
ij i k
k
i j N
ij k
k
E z tf w d
p w
E z d
N: number of documents](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-48-320.jpg)



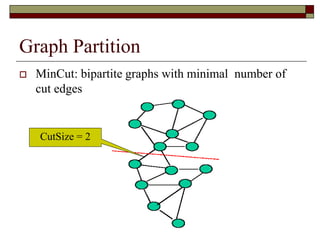
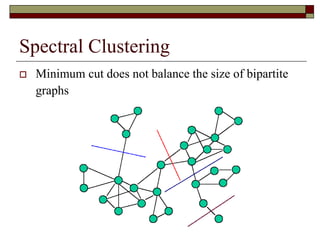
![2-way Spectral Graph Partitioning
Weight matrix W
wi,j: the weight between two
vertices i and j
Membership vector q
1 Cluster
-1 Cluster
i
i A
q
i B
[ 1,1]
2
,
,
arg min
1
4
n
i j i j
i j
CutSize
CutSize J q q w
q
q](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-54-320.jpg)
![Solving the Optimization Problem
Directly solving the above problem requires
combinatorial search exponential complexity
How to reduce the computation complexity?
2
,
[ 1,1] ,
1
argmin
4n
i j i j
i j
q q w
q
q](https://image.slidesharecdn.com/pert05aplikasiclustering-150505044448-conversion-gate01/85/Pert-05-aplikasi-clustering-55-320.jpg)