Downloaded 279 times















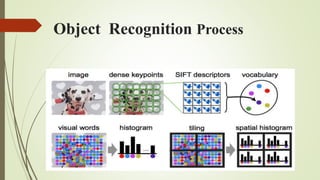











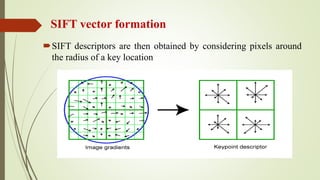
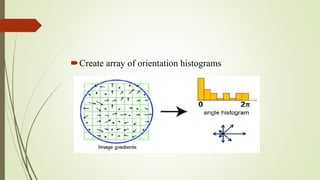


















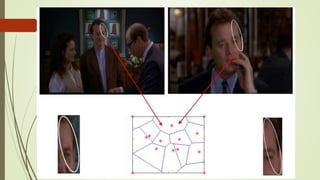

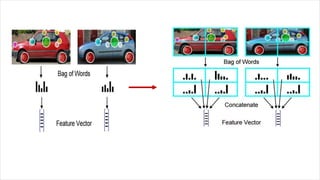

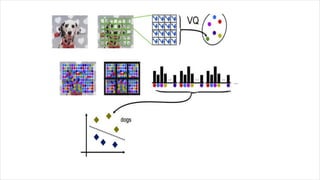


















This document discusses object recognition by computers. It notes that while object recognition is easy for humans, it is difficult for computers because they cannot rely on appearance alone. Key challenges for computers include variations in scale, shape, occlusion, lighting and background clutter. The document then discusses techniques used for object recognition, including feature detection methods like SIFT and SURF that extract keypoints, descriptors that describe regions around keypoints, and feature matching to identify corresponding regions between images. It also covers bag-of-words models, visual vocabularies and inverted indexing to allow large scale image retrieval. Finally, it lists applications of object recognition like digital watermarking, face detection and robot navigation.






























































































