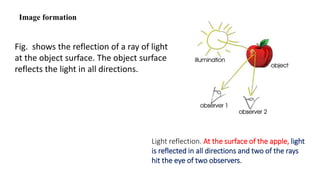
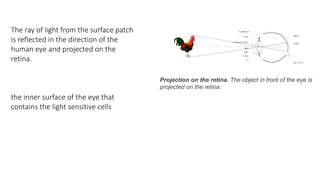
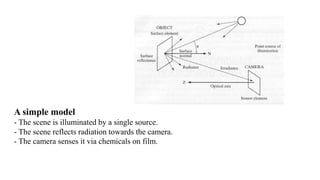
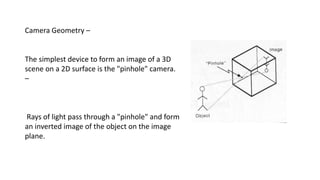
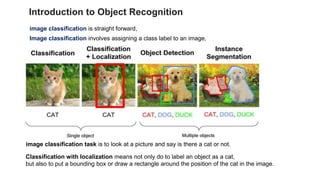
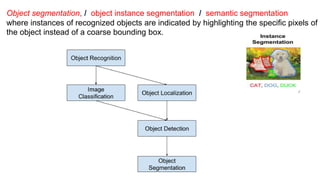
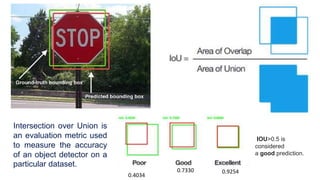
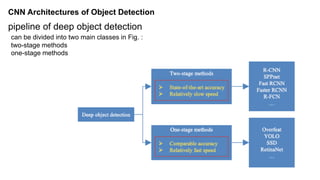
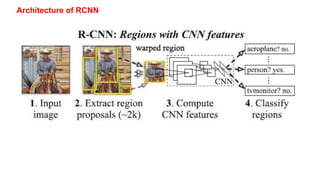
Unit 3 covers image processing and computer vision topics including image formation, tagging, classification, object detection, recognition, and segmentation using deep learning algorithms. Key topics include how images are formed through light reflection and projection on the retina similar to a pinhole camera. Image tagging involves labeling images with keywords to make them searchable. Object detection combines classification and localization to identify and locate multiple objects in an image using bounding boxes and class labels. Deep learning methods like RCNN and Faster RCNN use convolutional neural networks for object detection in two stages by first generating proposals and then classifying proposals.