Downloaded 17 times












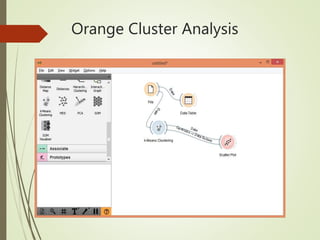
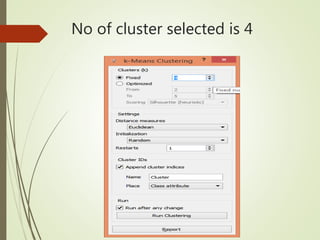
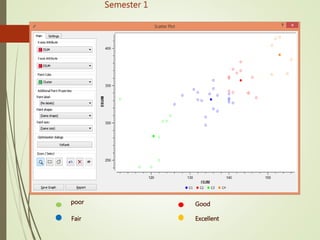
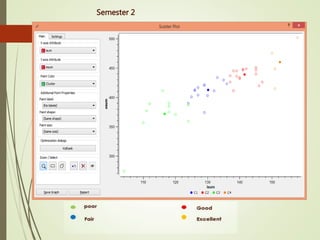
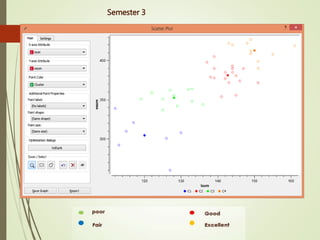
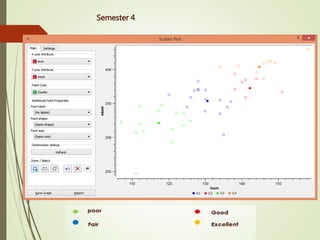
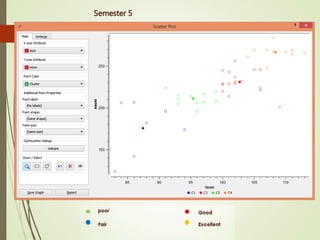

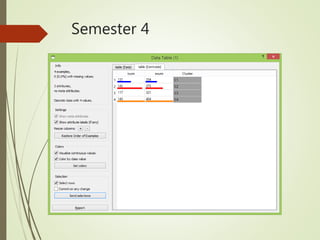
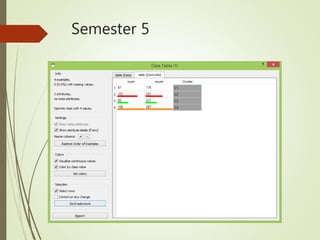
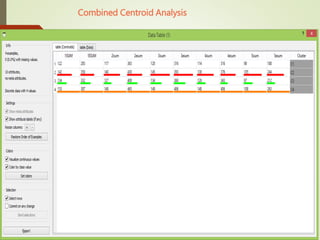





This document summarizes a study analyzing students' academic performance data. The study collected internal and external marks for 45 students over 5 semesters. It cleaned the data, transforming the marks into sums, and used k-means clustering to group students into 4 categories (excellent, good, fair, poor) for each semester based on their internal and external marks. The analysis found the clusters followed the same performance pattern each semester, with students scoring higher internally also scoring higher externally, indicating a direct relationship between internal and external marks. The study concluded a student's university exam performance can generally be predicted from their internal marks.





























































































