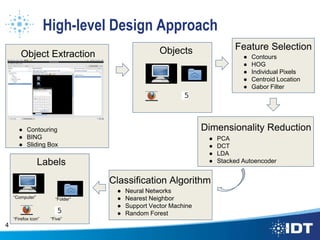
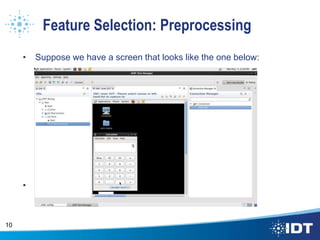
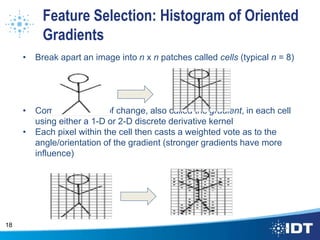
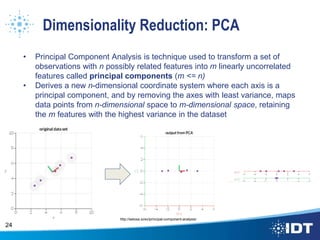
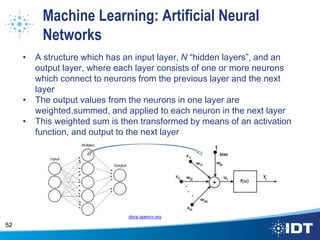
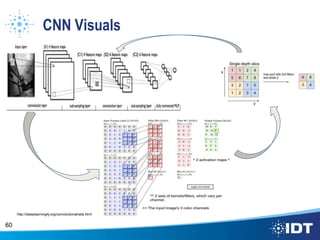
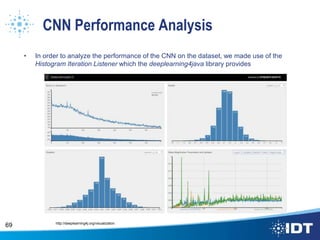
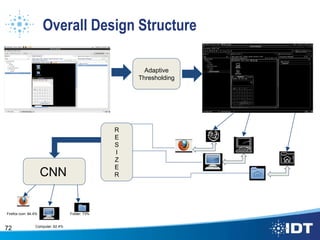
The document proposes improving object detection and recognition capabilities. It discusses challenges with current methods like different object sizes and color variations. The objectives are to build a module that can learn and detect objects without a sliding box or datastore. A high-level design approach is outlined using techniques like contouring, BING, sliding box, and feature selection methods. The design considers optimal feature selection, dimensionality reduction, and classification algorithms to function in real-time.







































































![Typical Neural Net Parameter Values
• Learning rate
– Domain: [0, 1]
– Typical value(s): 0.01-0.2
• Momentum
– Domain:[0,1]
– Typical value(s): 0.8-0.9
• Hidden Layers
– Domain: infinity…?
– Typical Values: Between the number of output nodes and
number of input nodes
• Weight decay
– Domain: [0,1]
– Typical Values: 0.01-0.1
79](https://image.slidesharecdn.com/a56f370d-c97f-4a84-b63d-abc2c0d352d0-160819005409/85/Cahall-Final-Intern-Presentation-79-320.jpg)























































