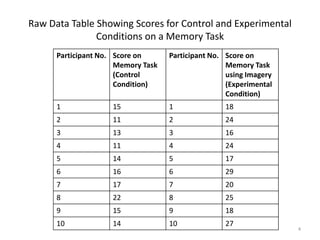
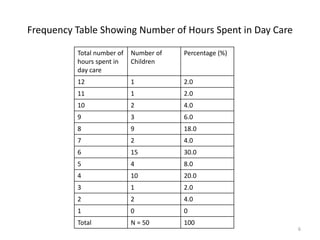
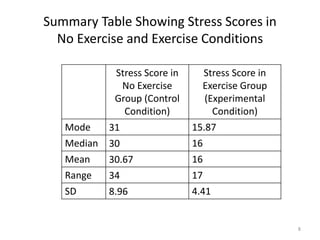
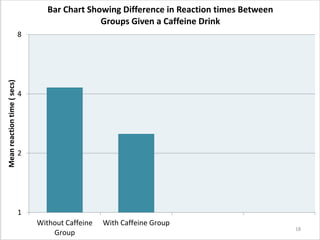
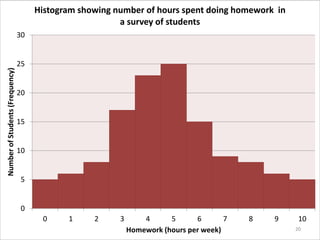
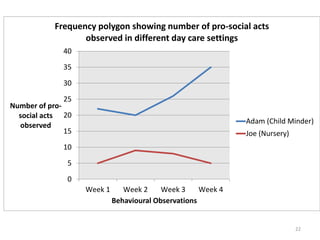
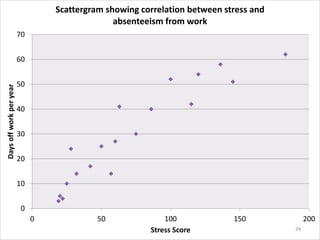
This document provides an overview of descriptive statistics and data representation techniques. It discusses measures of central tendency including the mean, median, and mode. It also covers different ways to present quantitative data visually, including graphs, tables, scatterplots, bar charts, histograms, and frequency polygons. The key purposes of descriptive statistics and data representation are to summarize patterns in data sets and communicate information effectively.