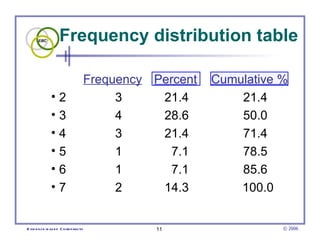
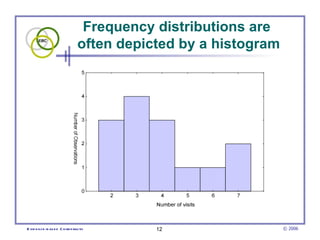
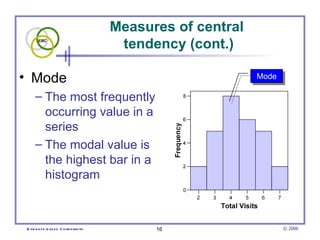
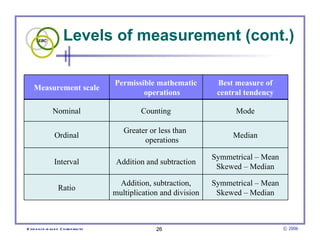
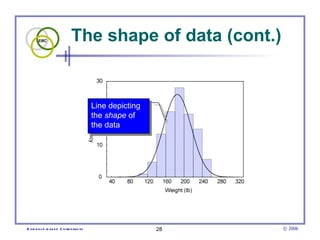
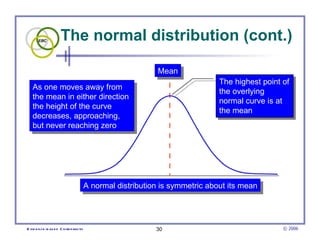
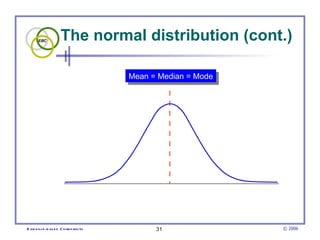
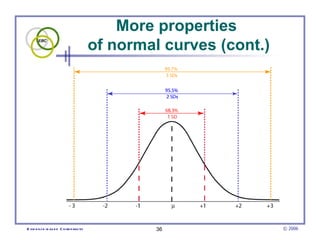
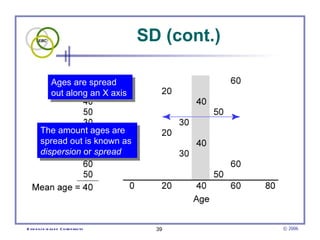
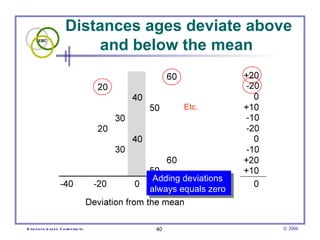
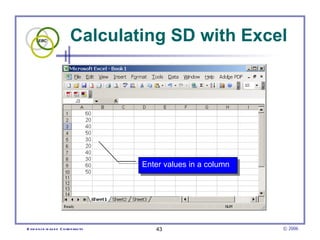
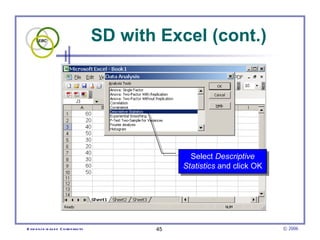
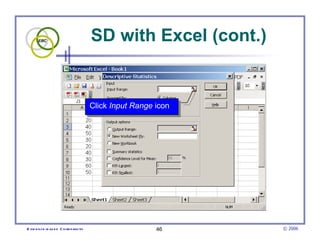
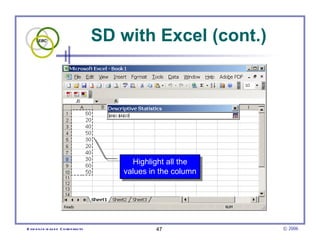
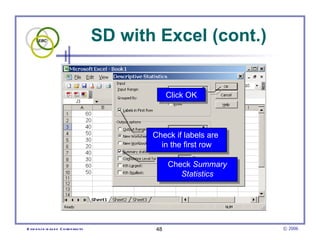
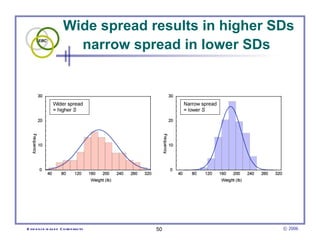
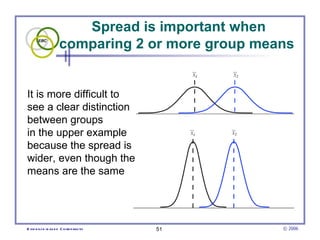
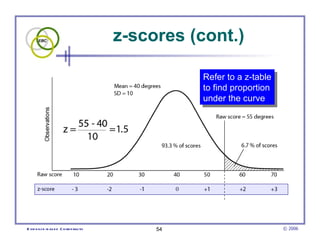
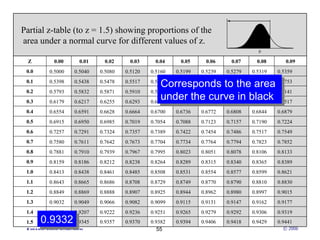
This document provides an introduction to common statistical terms and concepts used in biostatistics. It defines key terms like variables, populations, samples, descriptive statistics, and levels of measurement. It also explains how to calculate measures of central tendency like mean, median, and mode. Additionally, it describes properties of normal and skewed distributions, how to interpret the shape of data, and how to calculate and interpret standard deviation as a measure of variability.