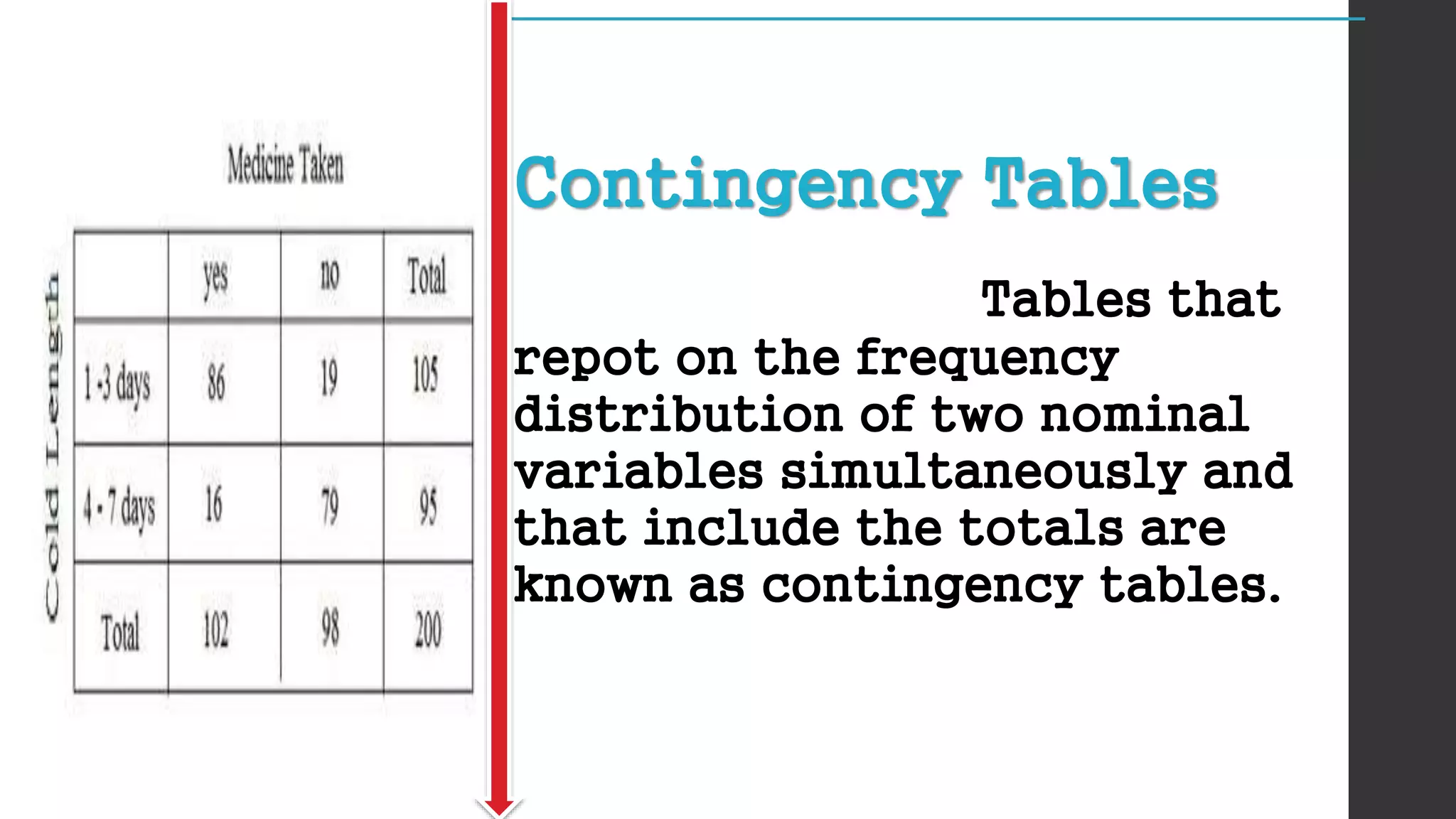
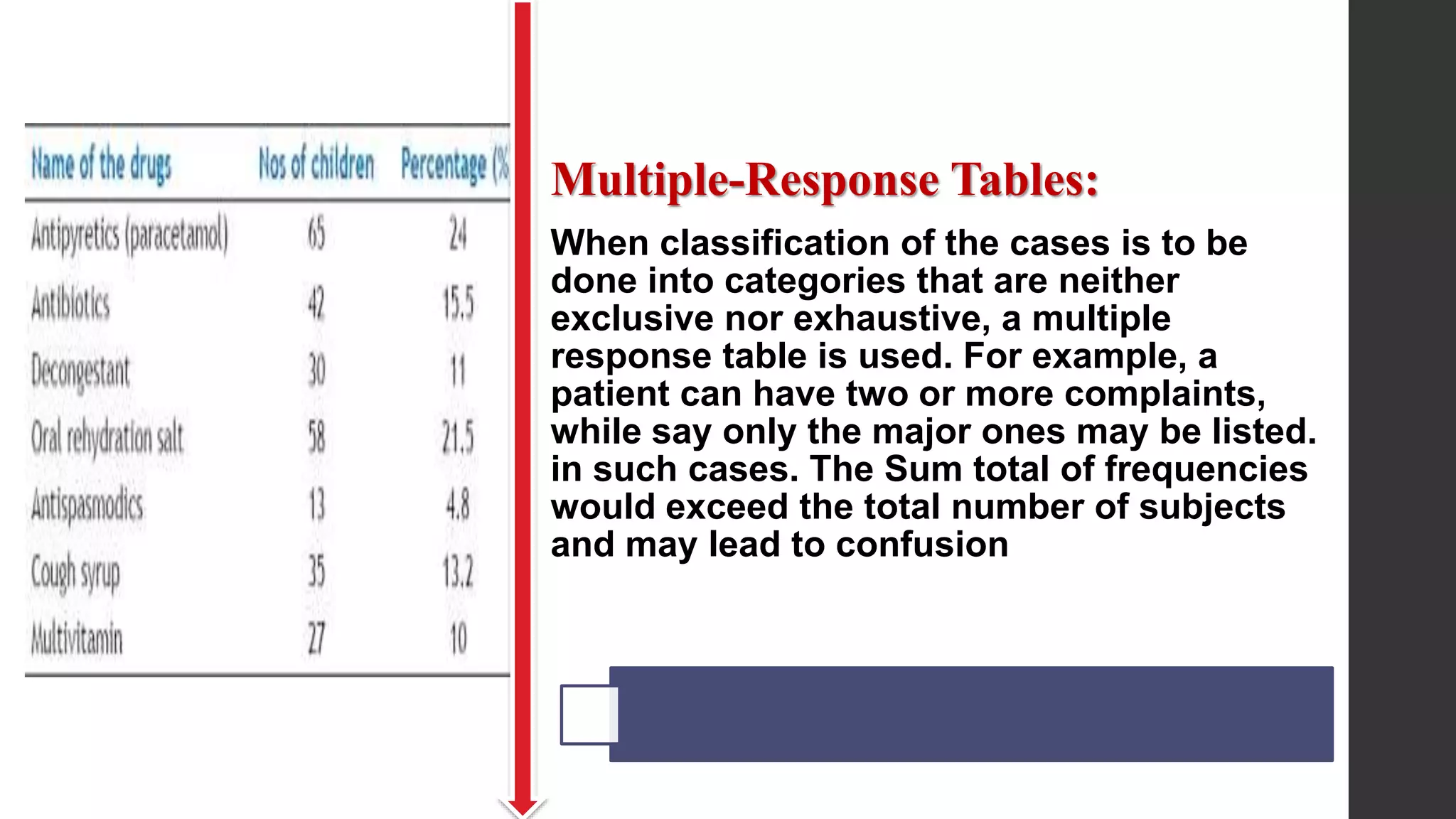
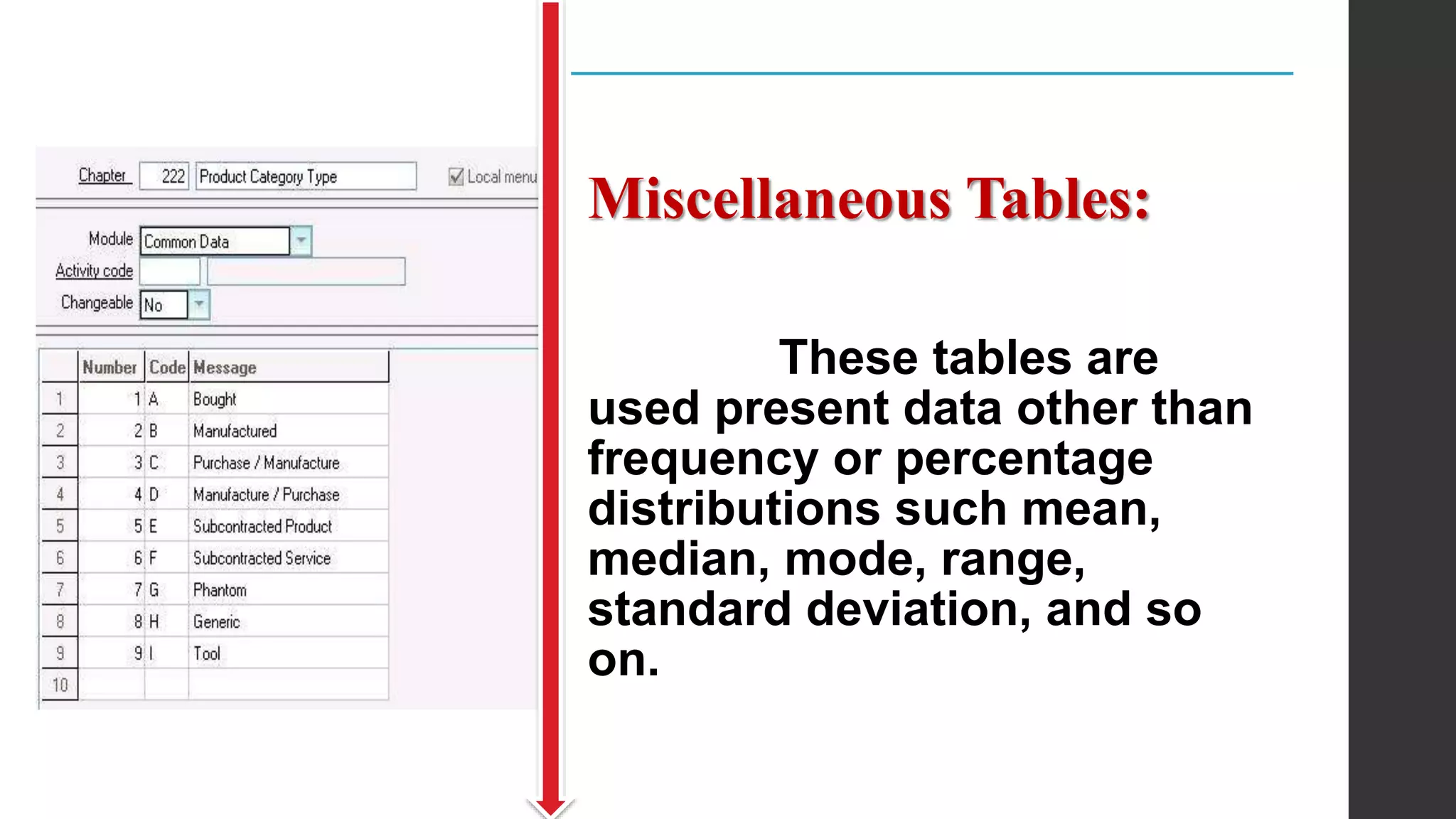
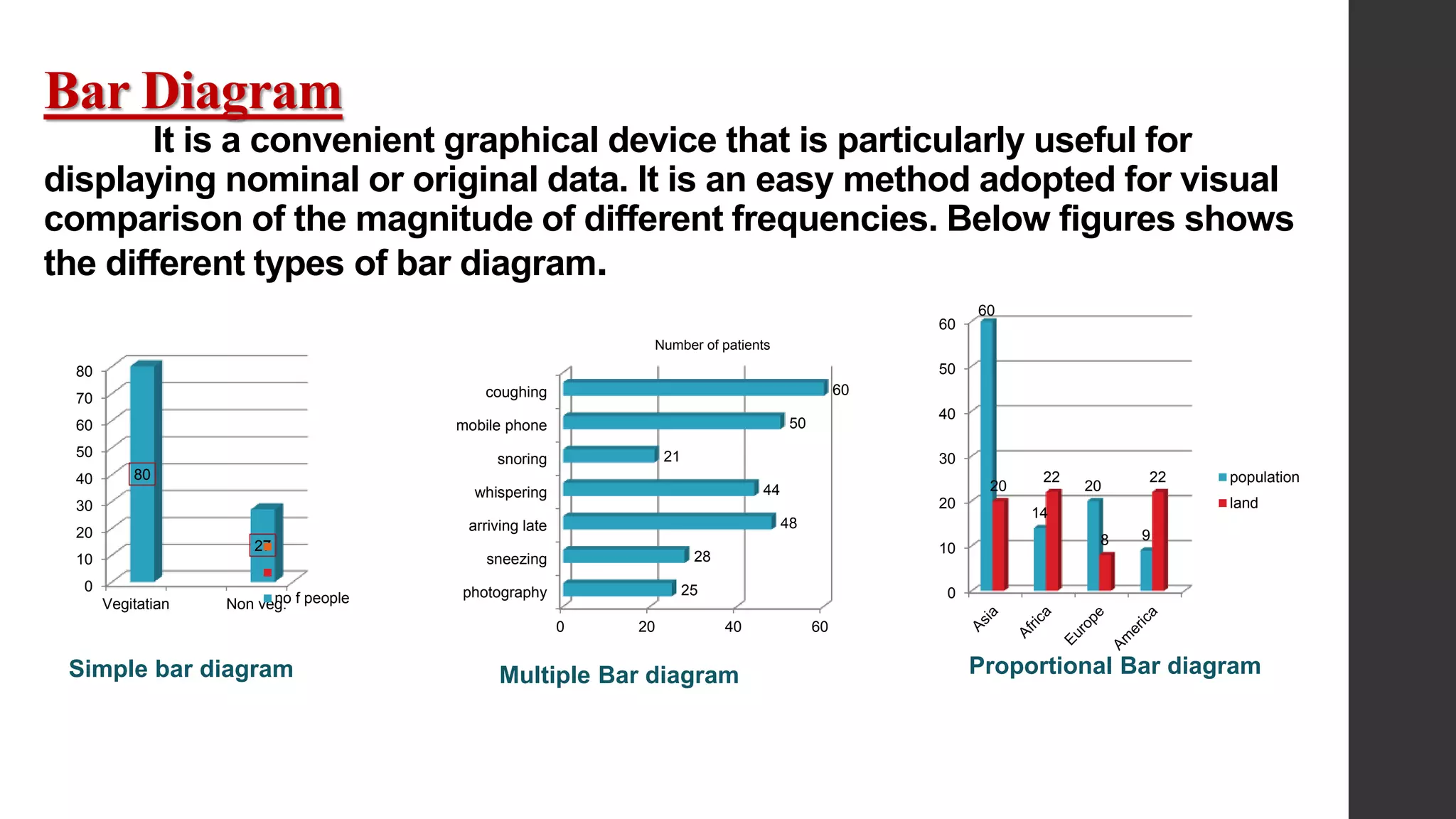
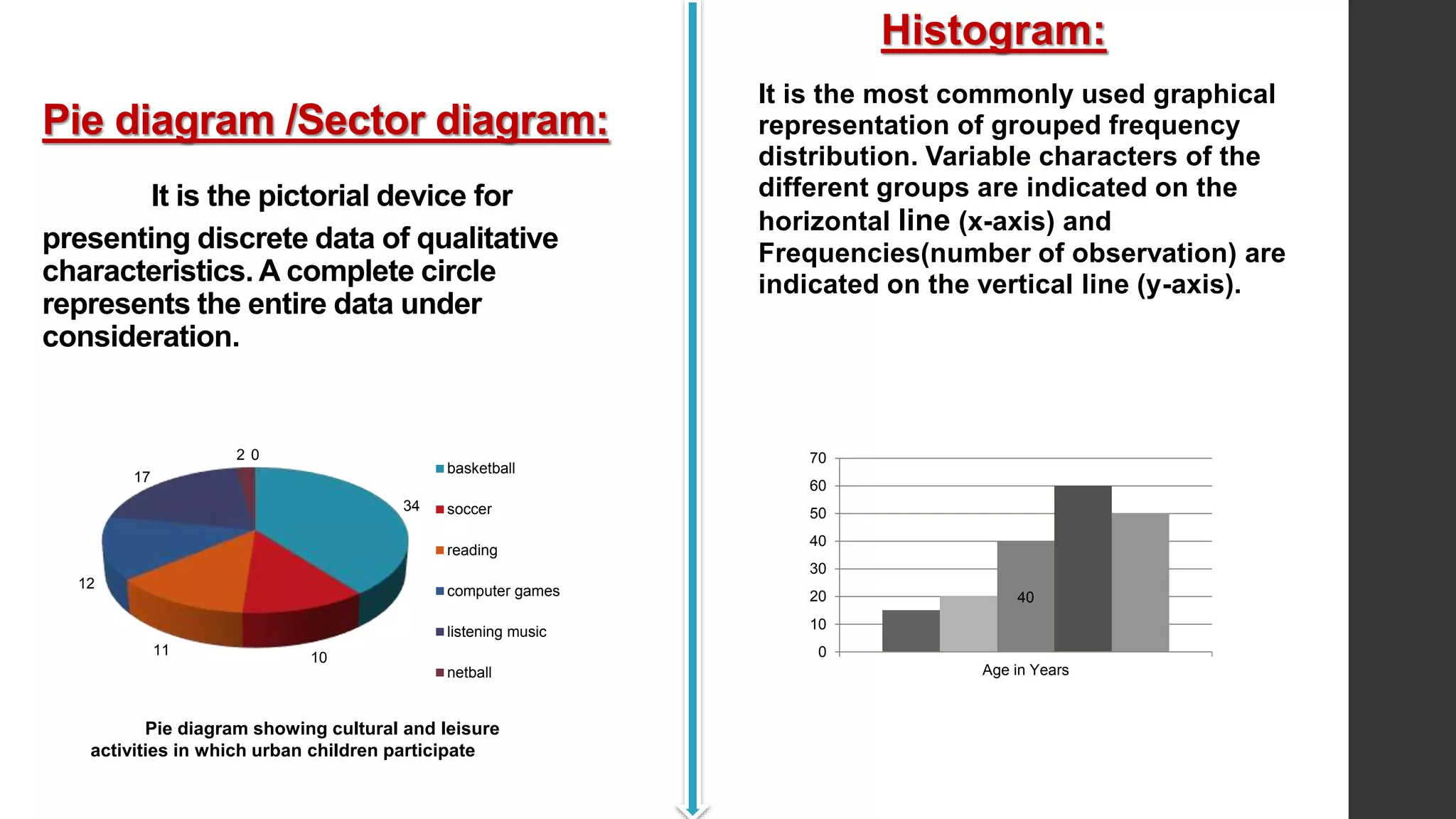
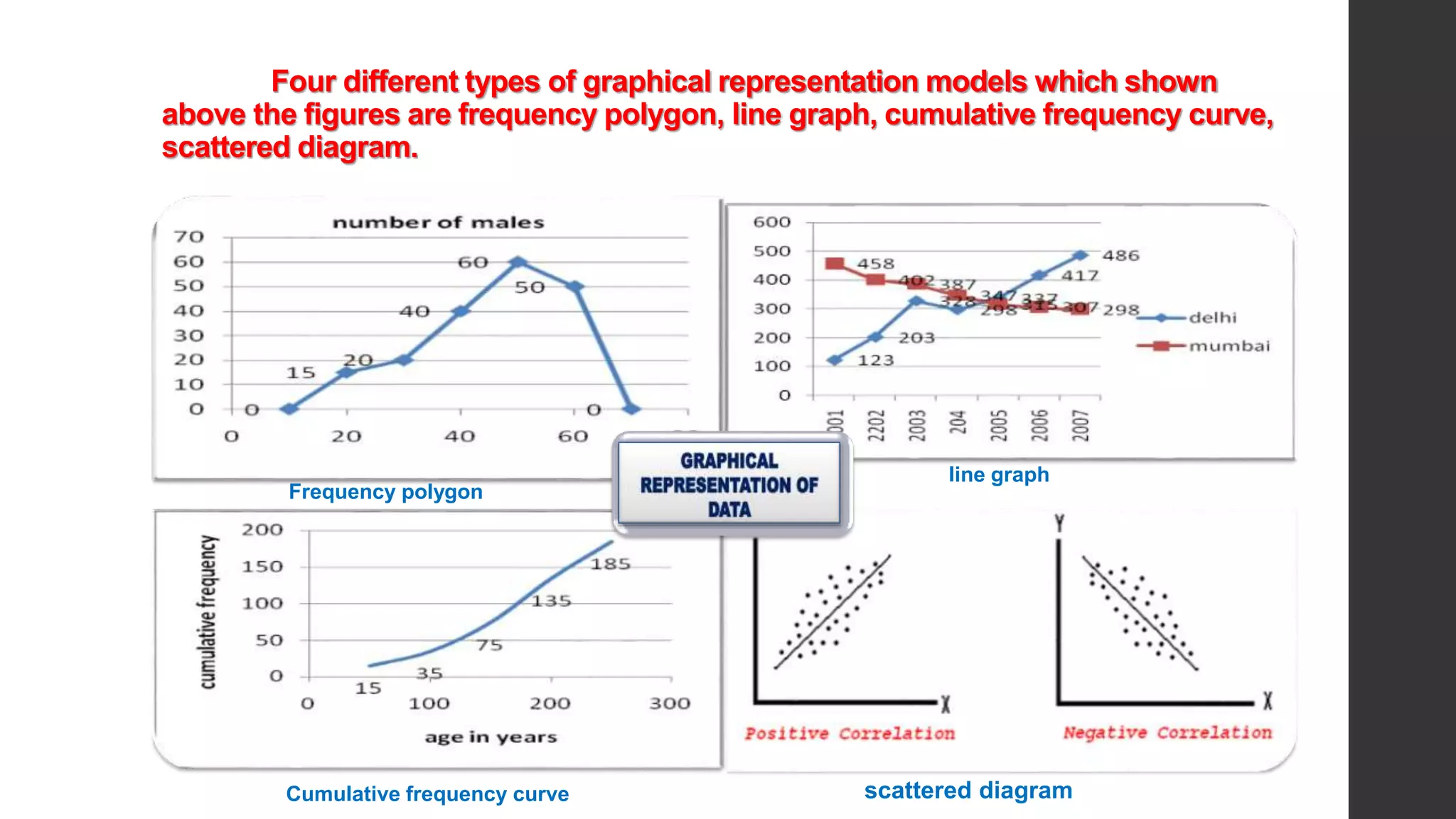
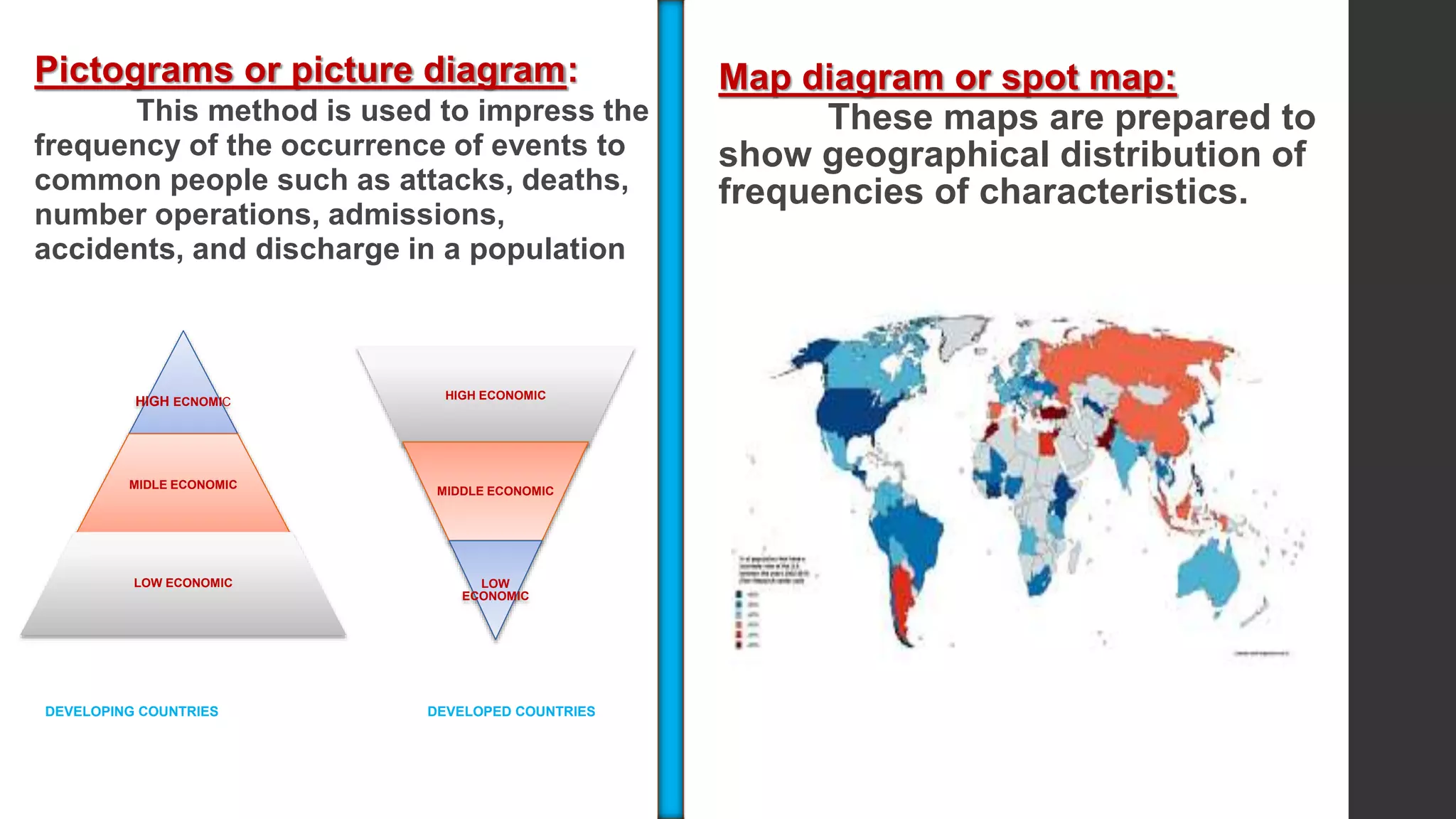
This document provides an overview of quantitative data analysis. It discusses data preparation, descriptive statistics such as measures of central tendency and dispersion, inferential statistics, and interpretation of results. The key steps in quantitative analysis are described as data preparation, describing the data through descriptive statistics, drawing inferences through inferential statistics, and interpreting the findings. Common statistical techniques like mean, median, mode, standard deviation, and correlation are also summarized.