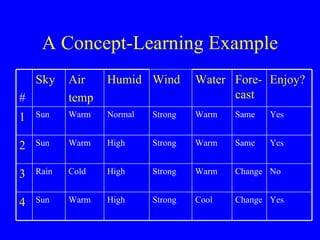
This document discusses machine learning concepts of concept learning and decision-tree learning. It describes concept learning as inferring a boolean function from training examples and using algorithms like Candidate Elimination to search the hypothesis space. Decision tree learning is explained as representing classification functions as trees with nodes testing attributes, allowing disjunctive concepts. The ID3 algorithm is presented as a greedy top-down search that selects the best attribute at each node using information gain, potentially overfitting data without pruning or a validation set.















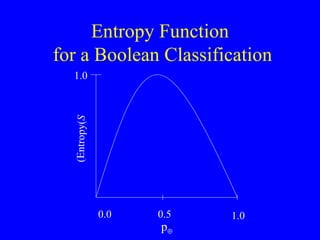
![Entropy Entropy : An information-theory measure that characterizes the (im)purity of an example set S using the proportion of positive ( ) and negative instances ( ) Informally: Number of bits needed to encode the classification of an arbitrary member of S; Entropy( S ) = –p log 2 p – p log 2 p Entropy( S ) is in [0..1] Entropy( S ) is 0 if all members are positive or negative Entropy is maximal (1) when p = p = 0.5 (uniform distribution of positive and negative cases) If there are c different values to the target concept, Entropy( S ) = i=1.. c – p i log 2 p i (p i is proportion of class i )](https://image.slidesharecdn.com/machine-learning3370/85/Machine-Learning-16-320.jpg)
![Entropy and Surprise Entropy can also be considered as the mean surprise on seeing the outcome (actual class) -log 2 p is also called the surprisal [Tribus, 1961] It is the only nonnegative function consistent with the principle that the amount we are surprised by the occurrence of two independent events with probabilities p 1 and p 2 is the same as we are surprised by the occurrence of a single event with probability p 1 x p 2](https://image.slidesharecdn.com/machine-learning3370/85/Machine-Learning-18-320.jpg)
![Information Gain of an Attribute Sometimes termed the Mutual Information (MI) gained regarding a class (e.g., a disease) given an attribute (e.g., a test), since it is symmetric The expected reduction in entropy E(S) caused by partitioning the examples in S using the attribute A and all its corresponding values Gain( S , A ) E ( S ) – v Values( A ) (| S v |/| S |) E (S v ) The attribute with maximal information gain is chosen by ID3 for splitting the node Follows from intuitive axioms [Benish, in press], e.g. not caring how the test result is revealed](https://image.slidesharecdn.com/machine-learning3370/85/Machine-Learning-19-320.jpg)


















































































