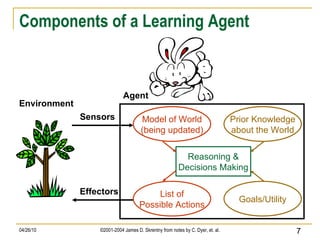
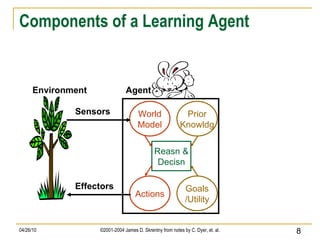
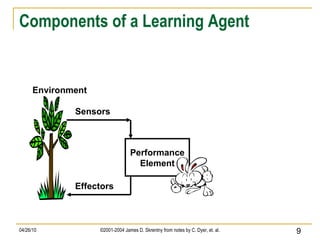
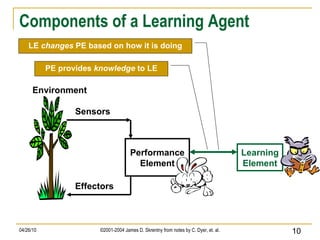
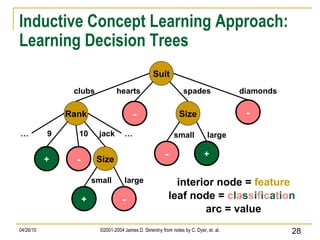
The document discusses concepts related to supervised machine learning and decision tree algorithms. It defines key terms like supervised vs unsupervised learning, concept learning, inductive bias, and information gain. It also describes the basic process for learning decision trees, including selecting the best attribute at each node using information gain to create a small tree that correctly classifies examples, and evaluating performance on test data. Extensions like handling real-valued, missing and noisy data, generating rules from trees, and pruning trees to avoid overfitting are also covered.
































































![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)




















































