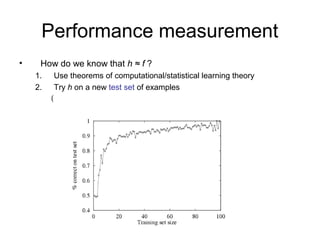
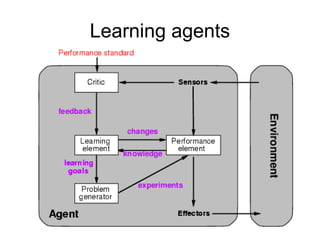
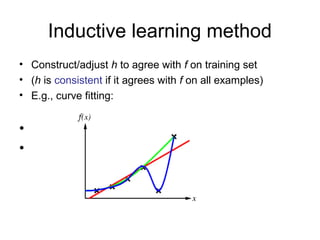
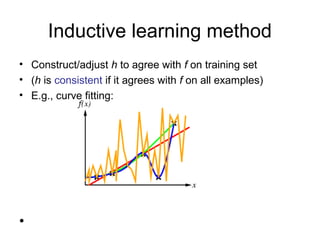
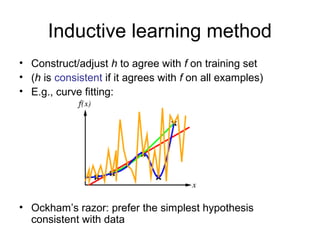
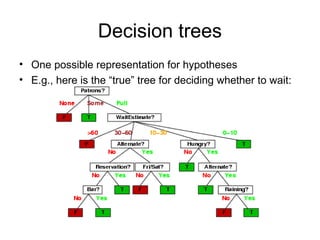
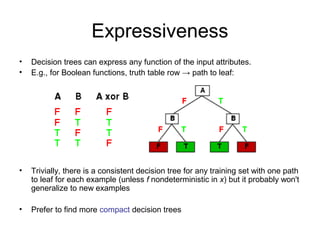
Learning agents modify their decision mechanisms through experience to improve performance. Inductive learning involves constructing a hypothesis function h that approximates the target function f based on training examples. Decision tree learning is an inductive method that uses information gain to recursively select the most informative attributes to split the training examples into subsets at each node, building the tree from the top down. Performance is evaluated by testing the learned hypothesis on new examples.
















![Information gain
For the training set, p = n = 6, I(6/12, 6/12) = 1 bit
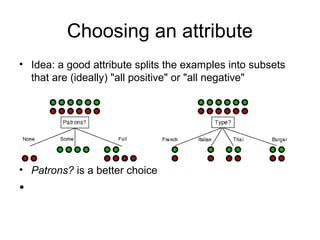
Consider the attributes Patrons and Type (and others too):
2 4 6 2 4
IG ( Patrons ) = 1 − [I (0,1) + I (1,0) + I ( , )] = .0541 bits
12 12 12 6 6
2 1 1 2 1 1 4 2 2 4 2 2
IG (Type) = 1 − [ I ( , ) + I ( , ) + I ( , ) + I ( , )] = 0 bits
12 2 2 12 2 2 12 4 4 12 4 4
Patrons has the highest IG of all attributes and so is chosen by the DTL
algorithm as the root](https://image.slidesharecdn.com/m18-learning-120725062526-phpapp02/85/M18-learning-23-320.jpg)