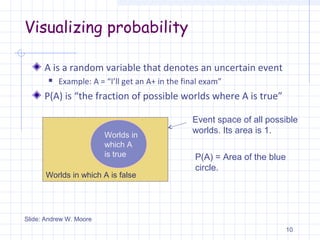
This document provides an overview of text classification and the Naive Bayes machine learning algorithm. It defines text classification as assigning categories or labels to documents, and discusses different approaches like human labeling, rule-based classification, and machine learning. Naive Bayes is introduced as a simple supervised learning method that calculates the probability of documents belonging to different categories based on word frequencies. The document then reviews probability concepts and shows how Naive Bayes makes the "naive" assumption that words are conditionally independent given the topic to classify documents probabilistically using Bayes' theorem.