This document provides an overview of Naive Bayes classification. It begins with background on classification methods, then covers Bayes' theorem and how it relates to Bayesian and maximum likelihood classification. The document introduces Naive Bayes classification, which makes a strong independence assumption to simplify probability calculations. It discusses algorithms for discrete and continuous features, and addresses common issues like dealing with zero probabilities. The document concludes by outlining some applications of Naive Bayes classification and its advantages of simplicity and effectiveness for many problems.








![Naive Bayes
Bayes classification
( ) ( ) ( ) ( , , | ) ( ) 1 P C| P |C P C P X X C P C n X X
Difficulty: learning the joint probability
Naive Bayes classification
-Assumption that all input features are conditionally independent!
P X X X C P X X X C P X X C
( , , , | ) ( | , , , ) ( ,
, | )
n n n
1 2 1 2 2
-MAP classification rule: for
P X C P X X C
( | ) ( , , | )
1 2
P X C P X C P X C
( | ) ( | ) ( | )
1 2
n
n
( , , , ) 1 2 n x x x x
*
[P(x | c ) P(x | c )]P(c ) [P(x | c) P(x | c)]P(c), c c , c c , ,c n 1
n 1
L * * *
1
8](https://image.slidesharecdn.com/naivebayespresentation-141209182741-conversion-gate02/85/Naive-Bayes-Presentation-9-320.jpg)
![Naive Bayes
Algorithm: Discrete-Valued Features
-Learning Phase: Given a training set S,
c (c c , ,c )
For each target value of 1
i i L
ˆ ( ) estimate ( ) with examples in ;
P C c P C
c
i i
x X j n k ,N
For every feature value of each feature ( 1, , ; 1,
)
jk j j
ˆ ( | ) estimate ( | ) with examples in ;
P X x C c P X x C
c
X N L j j ,
Output: conditional probability tables; for elements
-Test Phase: Given an unknown instance
( , , ) 1 n X a a
Look up tables to assign the label c* to X´ if
S
S
j jk i j jk i
[Pˆ(a | c * ) Pˆ(a | c * )]Pˆ(c *
) [Pˆ(a | c) Pˆ(a | c)]Pˆ(c), c c *
, c c ,
,c 1 n 1
n 1
L 9](https://image.slidesharecdn.com/naivebayespresentation-141209182741-conversion-gate02/85/Naive-Bayes-Presentation-10-320.jpg)
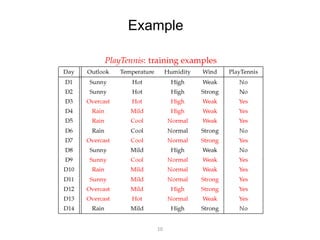
![Example
Test Phase :
-Given a new instance, predict its label
x´=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong)
-Look up tables achieved in the learning phrase
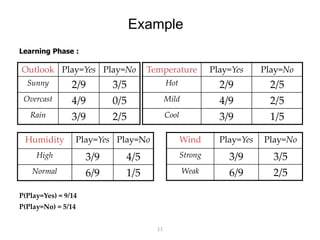
P(Outlook=Sunny|Play=Yes) = 2/9
P(Temperature=Cool|Play=Yes) = 3/9
P(Huminity=High|Play=Yes) = 3/9
P(Wind=Strong|Play=Yes) = 3/9
P(Play=Yes) = 9/14
-Decision making with the MAP rule:
P(Outlook=Sunny|Play=No) = 3/5
P(Temperature=Cool|Play==No) = 1/5
P(Huminity=High|Play=No) = 4/5
P(Wind=Strong|Play=No) = 3/5
P(Play=No) = 5/14
P(Yes|x´): [ P(Sunny|Yes) P(Cool|Yes) P(High|Yes) P(Strong|Yes) ] P(Play=Yes) = 0.0053
P(No|x´): [ P(Sunny|No) P(Cool|No) P(High|No) P(Strong|No) ] P(Play=No) = 0.0206
Given the fact P(Yes|x´) < P(No|x´) , we label x´ to be “No”.
12](https://image.slidesharecdn.com/naivebayespresentation-141209182741-conversion-gate02/85/Naive-Bayes-Presentation-13-320.jpg)






















































































