Download as PDF, PPTX

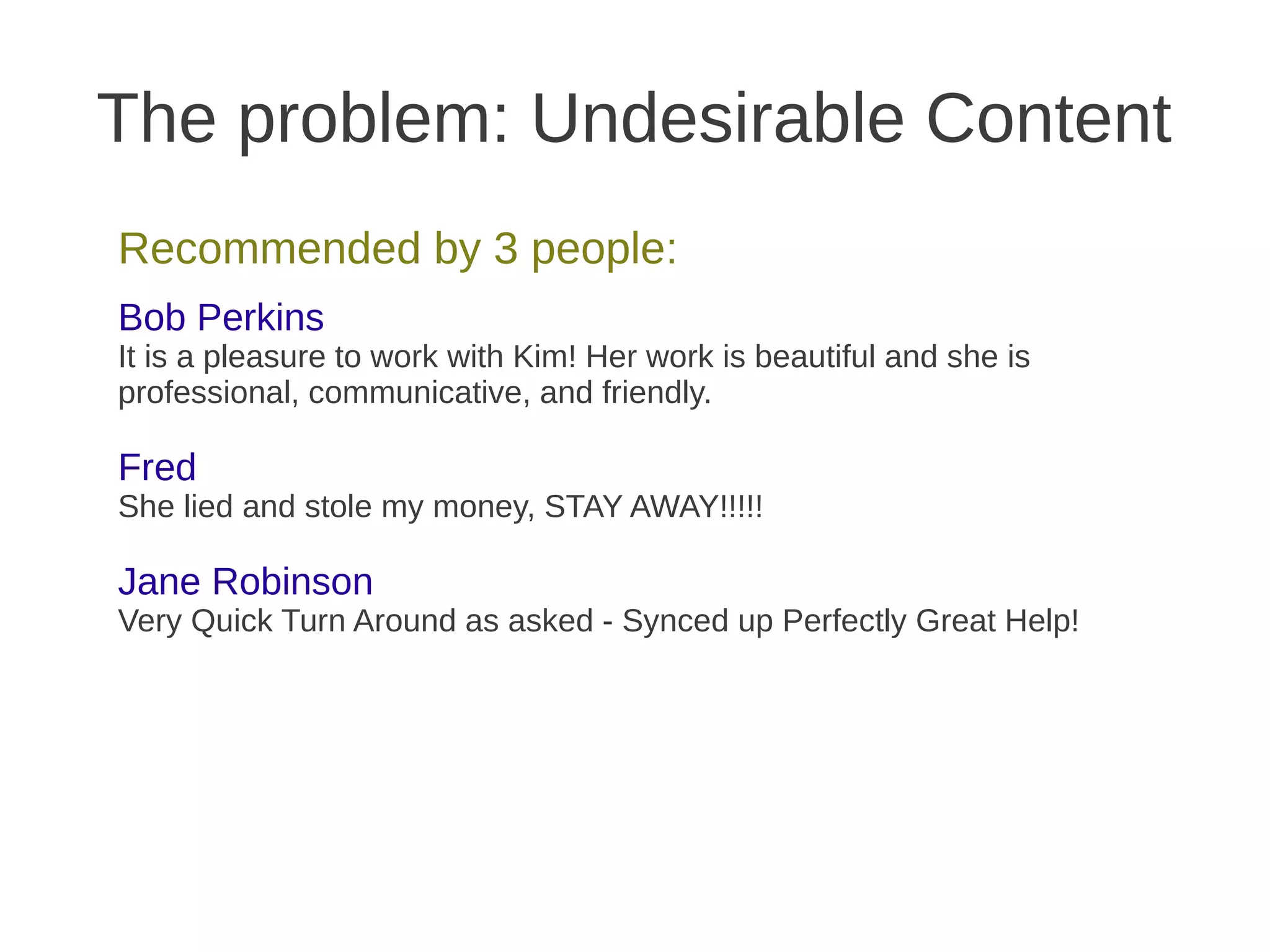



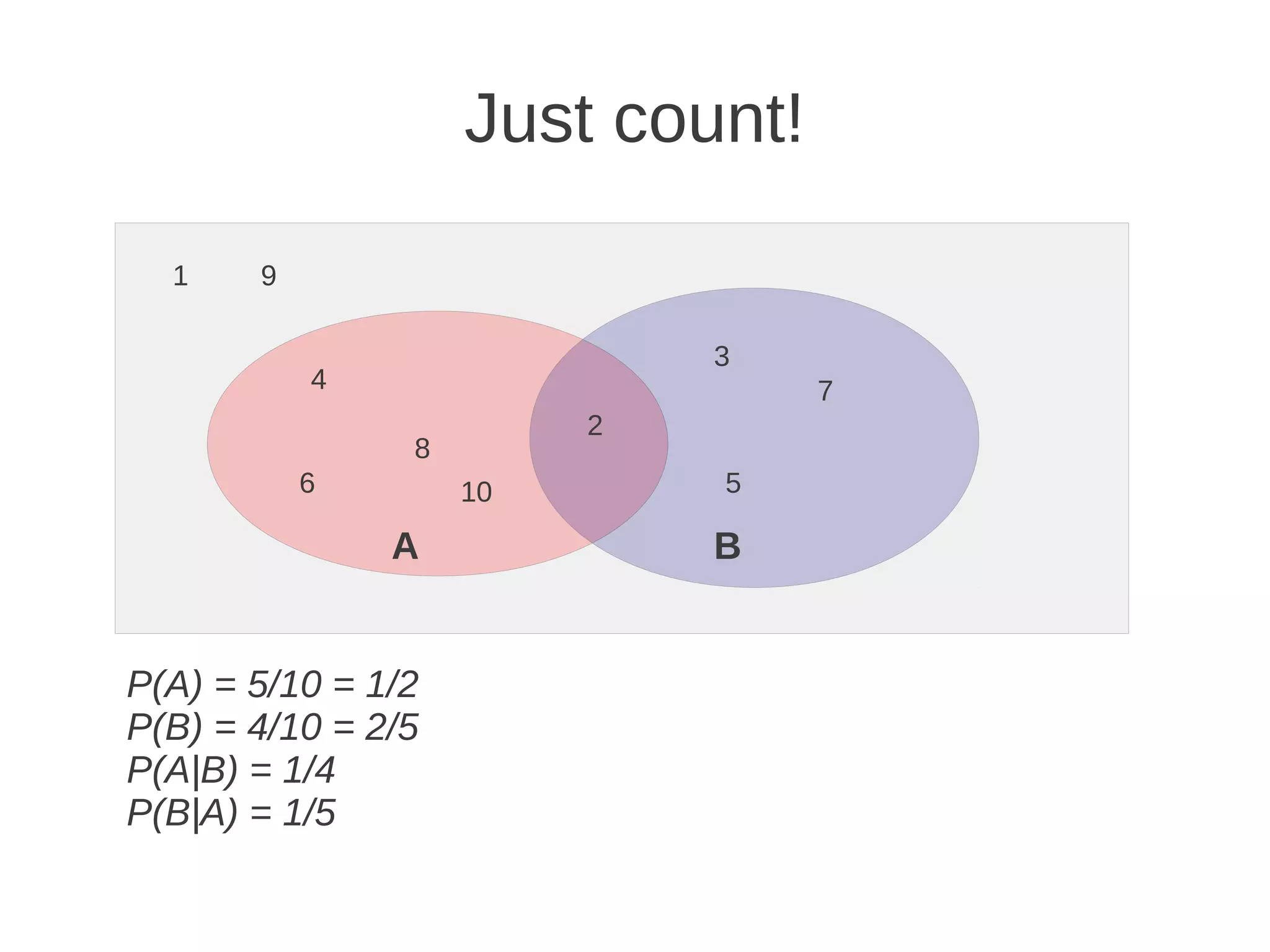



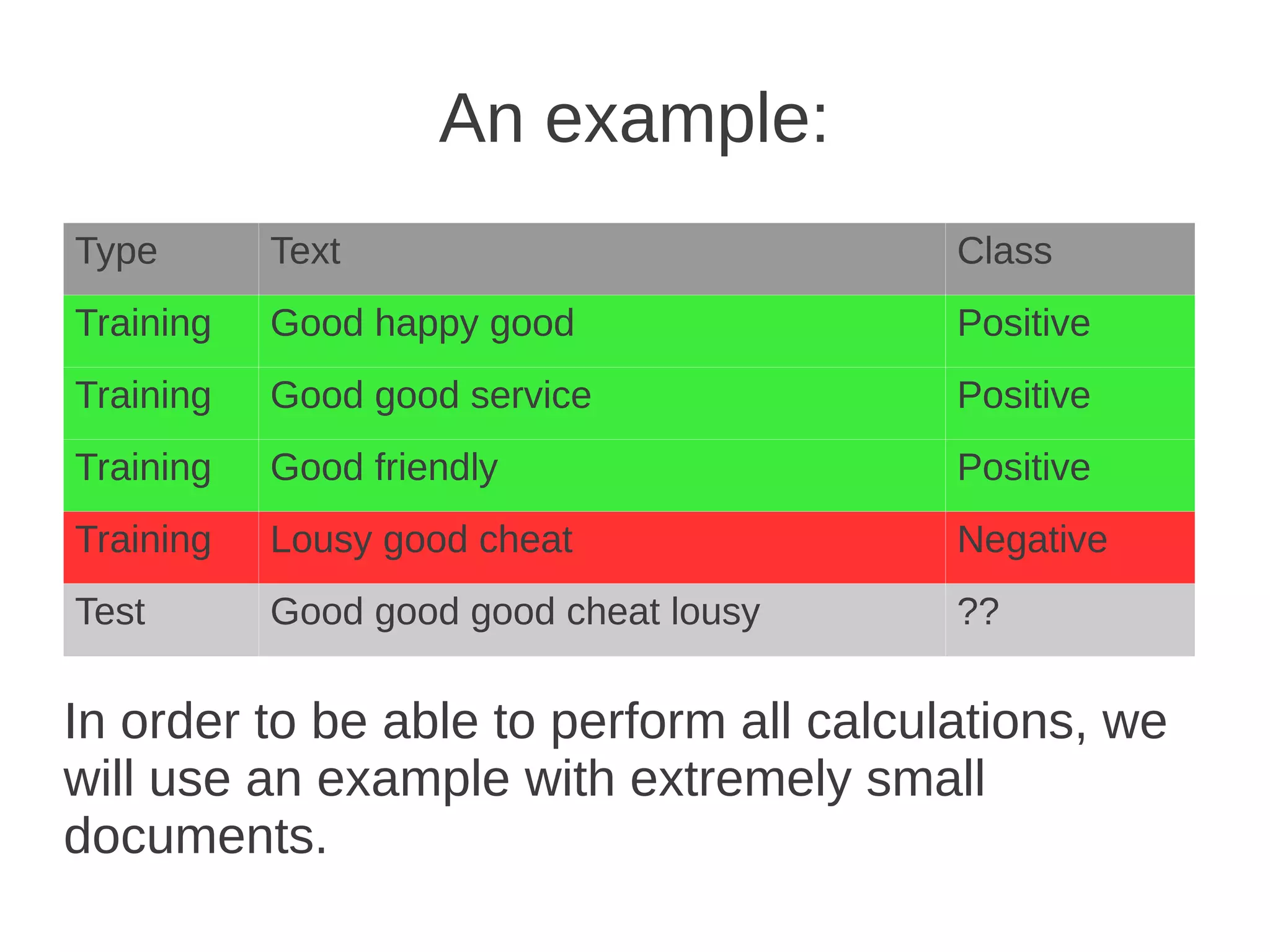
















The document discusses building a Naive Bayes classifier to filter undesirable content, detailing steps such as manually removing content, using banned word lists, and applying machine learning algorithms. It explains key concepts of probability, Bayes' theorem, tokenization challenges, and the training process for the classifier, along with practical considerations like smoothing and evaluating classifier performance. Eric Wilson also provides his contact information for further inquiries.



































































