Download as PDF, PPTX







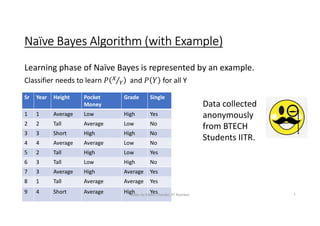
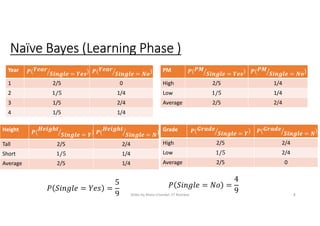







The document provides an overview of Bayesian classification and the Naive Bayes algorithm. It discusses how Thomas Bayes formulated Bayes' theorem and how the Naive Bayes classifier works by making the assumption that features are independent. The document explains the learning and testing phases of the Naive Bayes algorithm using examples, including how to handle continuous valued features. It also notes some issues like violating the independence assumption and how to prevent underflow problems in implementations.



































































