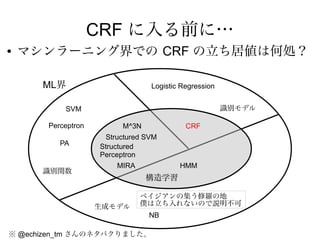
Conditional Random Fieldsって?
●
系列ラベリングに対数線形モデルを適用した物
Y B B I B I
X 今すぐ ここ から 逃げだし たい
B: 文節の開始を示すラベル
I: 文節に含まれることを示すラベル
系列ラベリング:入力系列Xが与えられた時に、適切なラベル列Yを与える
この発表では CRF と言えば Linear Chain CRF を指すよ。
9.
適切なラベリングとは
exp(W ・Φ ( X ,Y ))
P(Y | X )=
Z X ,W
Z X ,W : Σ Y P(Y | X )=1 を保証するための分配関数
Φ : 素性関数
W : 素性関数に対する重みベクトル
訓練データ(正しいラベルが付けられた系列データ)から学
習したパラメータWを用いて、入力系列Xに対する出力ラベル
系列Yの確率P(Y|X)が最大となるようなラベリングを行う
Viterbi アルゴリズムで効率的に行える
(あとで話す)
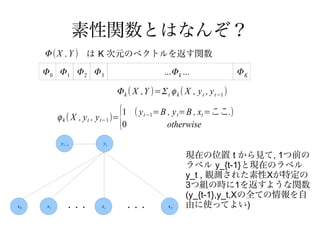
素性関数とはなんぞ?
Φ ( X , Y ) は K 次元のベクトルを返す関数
Φ0 Φ1 Φ2 Φ3 ...Φ k ... ΦK
Φ k ( X ,Y )= Σ t ϕ k ( X , y t , y t −1 )
ϕ k ( X , y t , y t−1 )= {
1 ( y t −1=B , y t=B , xt =ここ.)
0 otherwise
y t−1 yt
現在の位置 t から見て, 1つ前の
ラベル y_{t-1}と現在のラベル
y_t , 観測された素性Xが特定の
3つ組の時に1を返すような関数
(y_{t-1},y_t,Xの全ての情報を自
x0 x1 ・・・ xt ・・・ xT 由に使ってよい)
12.
よくある素性関数
yt
y t−1 yt
遷移素性とか言われたりする xt
ϕ 10 ( y t , y t −1)=
0 {
1 ( y t −1=BOS , y t =B) 観測素性とか言われたりする
otherwise
ϕ 0 (今すぐ , B) ϕ 5 (から , I )
ϕ 10 ( B , BOS ) ϕ 14 ( B , B) ϕ (今すぐ , I ) ϕ (逃げ出し , B)
1 6
スペースの省略 ϕ 11 ( I , BOS ) ϕ 15 ( B , I ) ϕ 2 (ここ , B) ϕ 7 (逃げ出し , I )
のためこう書く ϕ ( B , EOS ) ϕ 16 ( I , B)
12 ϕ 3 (ここ , I ) ϕ 8 (たい , B)
ϕ 13 ( I , EOS ) ϕ 17 ( I , I ) ϕ 4 (から , B) ϕ 9 (たい , I )
ラベルの種類は B , I の2つ, 入力系列Xが以下の時には上のような素性関数が作られる
X 今すぐ ここ から 逃げだし たい
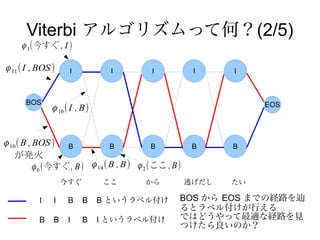
Viterbi アルゴリズムって何?(1/5)
●
グラフ上の重みが最大となる経路を求める手法
● 各位置 t で取り得るラベル種類が L, 系列長が
T の時は O(L^2 T) で最適パスが求まる
(まともに取り得るラベルを全列挙するとO(L^T) )
● 各位値 t のノードのスコアが最大となるような t-1 の
ノードを選んで接続する
15.
Viterbi アルゴリズムって何?(2/5)
ϕ 1(今すぐ , I )
ϕ 11 ( I , BOS ) I I I I I
BOS EOS
ϕ 16 ( I , B)
ϕ 10 ( B , BOS ) B B B B B
が発火
ϕ 0 (今すぐ , B) ϕ 14 ( B , B) ϕ 2 (ここ , B)
今すぐ ここ から 逃げだし たい
I I B B B というラベル付け BOS から EOS までの経路を辿
るとラベル付けが行える
B B I B I というラベル付け ではどうやって最適な経路を見
つけたら良いのか?
16.
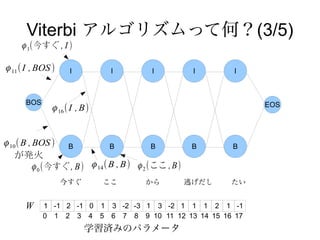
Viterbi アルゴリズムって何?(3/5)
ϕ 1(今すぐ , I )
ϕ 11 ( I , BOS ) I I I I I
BOS EOS
ϕ 16 ( I , B)
ϕ 10 ( B , BOS ) B B B B B
が発火
ϕ 0 (今すぐ , B) ϕ 14 ( B , B) ϕ 2 (ここ , B)
今すぐ ここ から 逃げだし たい
W 1 -1 2 -1 0 1 3 -2 -3 1 3 -2 1 1 1 2 1 -1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
学習済みのパラメータ
17.
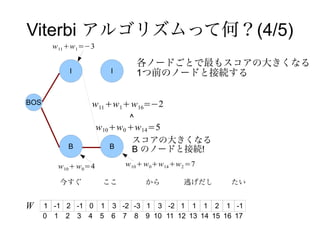
Viterbi アルゴリズムって何?(4/5)
w 11 +w 1=−3
各ノードごとで最もスコアの大きくなる
I I 1つ前のノードと接続する
BOS w 11 +w 1+ w 16=−2
^
w 10 +w 0 +w 14 =5
スコアの大きくなる
B B B のノードと接続!
w 10 + w 0=4 w 10 + w 0+w 14 +w 2 =7
今すぐ ここ から 逃げだし たい
W 1 -1 2 -1 0 1 3 -2 -3 1 3 -2 1 1 1 2 1 -1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18.
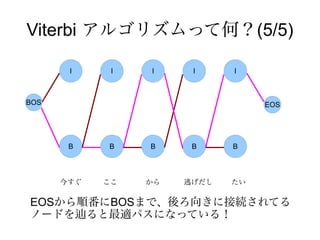
Viterbi アルゴリズムって何?(5/5)
I I I I I
BOS EOS
B B B B B
今すぐ ここ から 逃げだし たい
EOSから順番にBOSまで、後ろ向きに接続されてる
ノードを辿ると最適パスになっている!
重みベクトル W はどう求めるの?
W の更新式 勾配ベクトル
W t+1 = W t +Φ ( X ,Y )− Σ Y P (Y | X )Φ ( X ,Y )
' '
'
Y は学習データにある正解のラベル列
'
Y は生起しうる全てのラベル列
Σ Y P (Y | X )Φ( X , Y ) が求まれば割と簡単に更新出来る
' '
'
Forward-Backward アルゴリズムで効率的に求まる
● 勾配ベクトルの求め方は @sleepy_yoshi さん
のブログを見ると良い。
● http://d.hatena.ne.jp/sleepy_yoshi/20110329/p1
まずは式変形
Σ Y P(Y | X )Φ( X , Y )
' '
'
= ΣY P (Y ' | X ) Σ t ϕ( X , y t , y t −1 )
'
= Σt Σ y , y P ( y t−1 , y t | X ) ϕ( X , y t , y t −1)
t t−1
位置 t-1 から t へのラベルの遷移確率が求まればよい
y_0,...,y_{t-2} y_{t+1},...,y_T について
周辺化することで求められる
23.
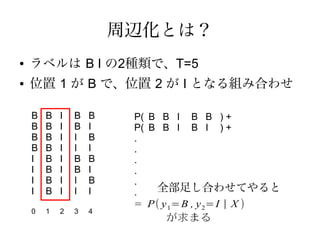
周辺化とは?
● ラベルは B I の2種類で、T=5
● 位置 1 が B で、位置 2 が I となる組み合わせ
B B I B B P( B B I B B ) +
B B I B I P( B B I B I ) +
B B I I B .
B B I I I .
I B I B B .
I B I B I .
I B I I B .
I B I I I . 全部足し合わせてやると
= P ( y 1= B , y 2= I | X )
0 1 2 3 4
が求まる
24.
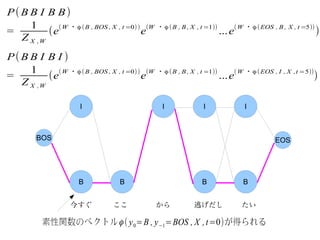
P(B B IB B)
1 ( W ・ϕ ( B , BOS , X , t =0) ) (W ・ϕ ( B , B , X , t =1)) ( W ・ϕ ( EOS , B , X , t =5))
= (e e ...e )
Z X ,W
P(B B I B I )
1 ( W ・ϕ ( B , BOS , X , t =0) ) (W ・ϕ ( B , B , X , t =1)) ( W ・ϕ ( EOS , I , X ,t =5))
= (e e ...e )
Z X ,W
I I I I
BOS EOS
B B B B
今すぐ ここ から 逃げだし たい
素性関数のベクトル ϕ ( y 0=B , y −1=BOS , X , t=0)が得られる
25.
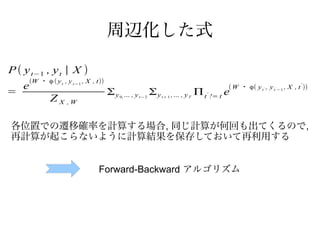
周辺化した式
P ( yt−1 , y t | X )
(W ・ ϕ ( y t , y t − 1 , X , t))
e ( W ・ ϕ( y t , y t − 1 , X , t ))
=
'
Σy Σy Π t != t e
' '
... , y t− 2 ,... , y T '
Z X ,W 0, t+ 1
各位置での遷移確率を計算する場合, 同じ計算が何回も出てくるので,
再計算が起こらないように計算結果を保存しておいて再利用する
Forward-Backward アルゴリズム
26.
Forward-Backward アルゴリズム
P (y t−1 , y t | X )
(W ・ ϕ ( y t , y t − 1 , X , t))
e ( W ・ ϕ( y t ' , y't−1 , X ,t ' ))
= Σy .. , y t − 2 Σy , ... , y T Π t != t e
'
Z X ,W 0,. t+ 1
(W ・ϕ (y t ' , y t− 1 , X , t ))
' '
Σy 0,.
.. , y t − 2 Σy t +1
,... , y T Πt ! =t e'
(W ・ϕ ( yt ' , y 't − 1 , X , t ' ))
= (Σ y 0,. .. , yt− 2 Π t =0,. .. ,t −1 e
' )
( W ・ϕ ( y t ' , y t − 1 , X , t ))
' '
( Σy t+ 1 ,... , y T Π t =t +1,... ,T +1 e
' )
t-1より前とtより後ろで式を分けて
(W ・ ϕ( y t ' , y t−1 , X ,t ))
' '
α ( y t , t )=Σ y 0,.
.. , y t− 1 Π t =0,... , t e
'
(W ・ ϕ( y t ' , y 't−1 , X ,t ' ))
β ( y t , t )=Σ y t+1 , ... , y T Π t =t+1,... , T +1 e
'
とおくと
27.
Forward-Backward アルゴリズム
( W ・ϕ ( y t , yt −1 , X ,t ))
e
P ( y t−1 , y t | X )= α ( y t−1 , t −1) β ( y t , t )
Z X ,W
と表せる。
α と β は次のように表せる
α ( y t , t )=Σ y e(W ・ϕ ( y , y , X , t) ) α ( y t −1 , t −1)
t− 1
t t− 1
β ( y t , t )=Σ y e(W ・ ϕ ( y , y , X , t+1)) β ( y t +1 , t +1)
t+1
t+ 1 t
ただし α (BOS ,−1)=1, β ( EOS , T +1)=1
Z X ,W = α ( EOS ,T +1)= β (BOS ,−1)となる 。
28.
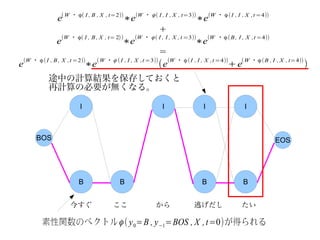
e( W ・ϕ( I , B , X , t=2))∗e(W ・ ϕ ( I , I , X , t=3))∗e(W ・ ϕ (I , I , X ,t =4))
+
(W ・ ϕ( I , B , X , t= 2)) (W ・ ϕ ( I , I , X , t =3)) (W ・ϕ (B , I , X ,t =4))
e ∗e ∗e
=
(W ・ ϕ ( I , B , X ,t =2)) ( W ・ ϕ ( I , I , X ,t =3)) (W ・ ϕ (I , I , X ,t =4)) (W ・ϕ ( B , I , X , t=4))
e ∗e (e +e )
途中の計算結果を保存しておくと
再計算の必要が無くなる。
I I I I
BOS EOS
B B B B
今すぐ ここ から 逃げだし たい
素性関数のベクトル ϕ ( y 0=B , y −1=BOS , X , t=0)が得られる
29.
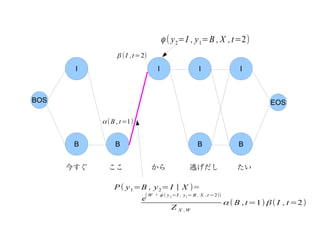
ϕ ( y2=I , y 1=B , X , t=2)
β ( I ,t = 2)
I I I I
BOS EOS
α ( B , t =1)
B B B B
今すぐ ここ から 逃げだし たい
P ( y 1=B , y 2= I | X )=
( W ・ ϕ ( y 2 =I , y1= B , X ,t =2))
e
α ( B ,t =1) β ( I , t =2)
Z X ,W
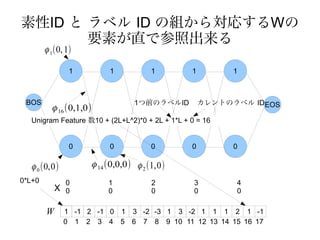
B とだけあるのはどうなるの?
B
マクロで取り出された素性
ϕ 10 ( B , B , BOS ) ϕ 10 ( B , B , B)
ϕ 11 ( B , I , BOS ) ϕ 11 ( B , I , B)
ϕ 12 ( B , B , EOS ) ϕ 12 ( B , B , E )
ϕ 13 ( B , I , EOS ) ϕ 13 ( B , I , E)
という素性関数が作られる
入力系列Xに依存しないため, 全ての位置についてBという
素性が取り出され, ラベル遷移だけを見る事が出来る

























![テンプレートの例(1/5)
yt
xt
2 形動 名詞場所 格助詞 サ五 助動詞たい
X 1 形容動詞 名詞 助詞 動詞 助動詞
0 今すぐ ここ から 逃げだし たい
-1 0 1 2 3
t
現在の位置 t からの相対位置 指定された位置の何行目の素性を取るか
U01:%x[0,0]
指定された位置の観測された
素性を取り出すマクロ
現在の位置のラベルのみ見る
観測された素性x_t に Prefix
として付加される](https://image.slidesharecdn.com/crf-110624171401-phpapp02/85/Crf-35-320.jpg)
![テンプレートの例(2/5)
yt
xt
2 形動 名詞場所 格助詞 サ五 助動詞たい
X 1 形容動詞 名詞 助詞 動詞 助動詞
0 今すぐ ここ から 逃げだし たい
-1 0 1 2 3
t
U01:%x[0,0] U01:ここ
U02:%x[0,1] U02:名詞
の様に置き換わる](https://image.slidesharecdn.com/crf-110624171401-phpapp02/85/Crf-36-320.jpg)

![テンプレートの例(4/5)
y t−1 yt B01:%x[0,0]
xt
B01:ここ と置き換わる
2 形動 名詞場所 格助詞 サ五 助動詞たい
X 1 形容動詞 名詞 助詞 動詞 助動詞
0 今すぐ ここ から 逃げだし たい
-1 0 1 2 3
t](https://image.slidesharecdn.com/crf-110624171401-phpapp02/85/Crf-38-320.jpg)
![テンプレートの例(5/5)
yt yt
x t−1 xt x t−1 xt x t+1
U03:%x[-1,0]/%[0,0] U04:%x[-1,0]/%[0,0]/%x[1,0]
観測値の bigram 観測値の trigram
“/”はただの文字列として観測された素性に付加される](https://image.slidesharecdn.com/crf-110624171401-phpapp02/85/Crf-39-320.jpg)







![すると・・・
U01:%x[0,0]
B X 今すぐ ここ から 逃げだし たい
素性テンプレート
U01:今すぐ U01:ここ U01:から U01:逃げ出し U01:たい
B B B B B
Unigram Feature のID 0 1 2 3 4
Bigram Feature のID 0 0 0 0 0](https://image.slidesharecdn.com/crf-110624171401-phpapp02/85/Crf-47-320.jpg)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)































