More Related Content

PDF

PDF

PDF

PDF

PDF
はじめてのパターン認識 第8章 サポートベクトルマシン 
PDF

PDF

PDF
What's hot

PDF

PDF

PPTX

PDF

PDF

PDF
Amortize analysis of Deque with 2 Stack 
PDF

PDF

PDF

PDF

PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半 
PDF

PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会 
PDF
異常検知と変化検知 9章 部分空間法による変化点検知 
PDF

PPTX
Multiple optimization and Non-dominated sorting with rPref package in R 
PDF

PDF

PPTX

PDF
二部グラフの最小点被覆と最大安定集合と最小辺被覆の求め方 Viewers also liked

PDF

PDF
はじめてのパターン認識 第5章 k最近傍法(k_nn法) 
PPTX

PDF

PDF

PDF

PDF

PDF
How to use animation packages in R(Japanese) 
PDF

PDF

PDF

PDF

PDF
異常行動検出入門 – 行動データ時系列のデータマイニング – 
PDF

PDF

PDF

PDF

PPTX
Tokyo Webmining #12 Hapyrus 
PDF

PPTX
Similar to パターン認識 08 09 k-近傍法 lvq

PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜 
PPTX

PPTX

PDF

PDF

PDF

PDF
Math in Machine Learning / PCA and SVD with Applications 
PDF

PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築 
PPTX
DSB2019振り返り会:あのにっくき QWK を閾値調整なしで攻略した(かった) 
PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF

PDF

PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28) 
PDF

PDF
![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
Infinite SVM [改] - ICML 2011 読み会 
PDF

PPTX

PDF
パターン認識 08 09 k-近傍法 lvq
- 1.
Rで学ぶデータサイエンス
5パターン認識
第8章 k-近傍法
第9章 学習ベクトル量子化
2011/07/**
TwitterID:sleipnir002
- 2.
R一人勉強会のご紹介
Rで学ぶデータサイエンス 5パターン認識
(著)金森 敬文, 竹之内 高志, 村田 昇, 金 明哲
共立出版
今ならデモスクリプトがダウンロードできる!
http://www.kyoritsu-
pub.co.jp/service/service.html#019256
第1章 判別能力の評価 Done
第2章 k-平均法 Done
第3章 階層的クラスタリング
第4章 混合正規分布モデル Done
第5章 判別分析 おもしろネタ募集中
第6章 ロジスティック回帰
第7章 密度推定
第8章 k-近傍法 ←イマココ!
第9章 学習ベクトル量子化 ←イマココ!
第10章 決定木
第11章 サポートベクターマシン
第12章 正則化とパス追跡アルゴリズム
第13章 ミニマックス確率マシン
第14章 集団学習 さぁ、今すぐAmazonでクリック!!
第15章 2値判別から多値判別へ
- 3.
- 4.
第8、9章の目的
K-近傍法で教師ありクラス分類
学習ベクトル量子化で教師ありクラス分類
• k-近傍法
• 学習ベクトル量子化
- 5.
- 6.
k-近傍法のアルゴリズム
K-近傍法とは近くのデータで多数決を取る方法
e.g.3-近傍法の場合
• テストデータの近くに
ある学習データの多
数決でテストデータ テストデータ
のラベルを予測する。
• 多クラス変数でも簡 3近傍のトレーニングデータ
単に予測できる。
- 7.
- 8.
- 9.
- 10.
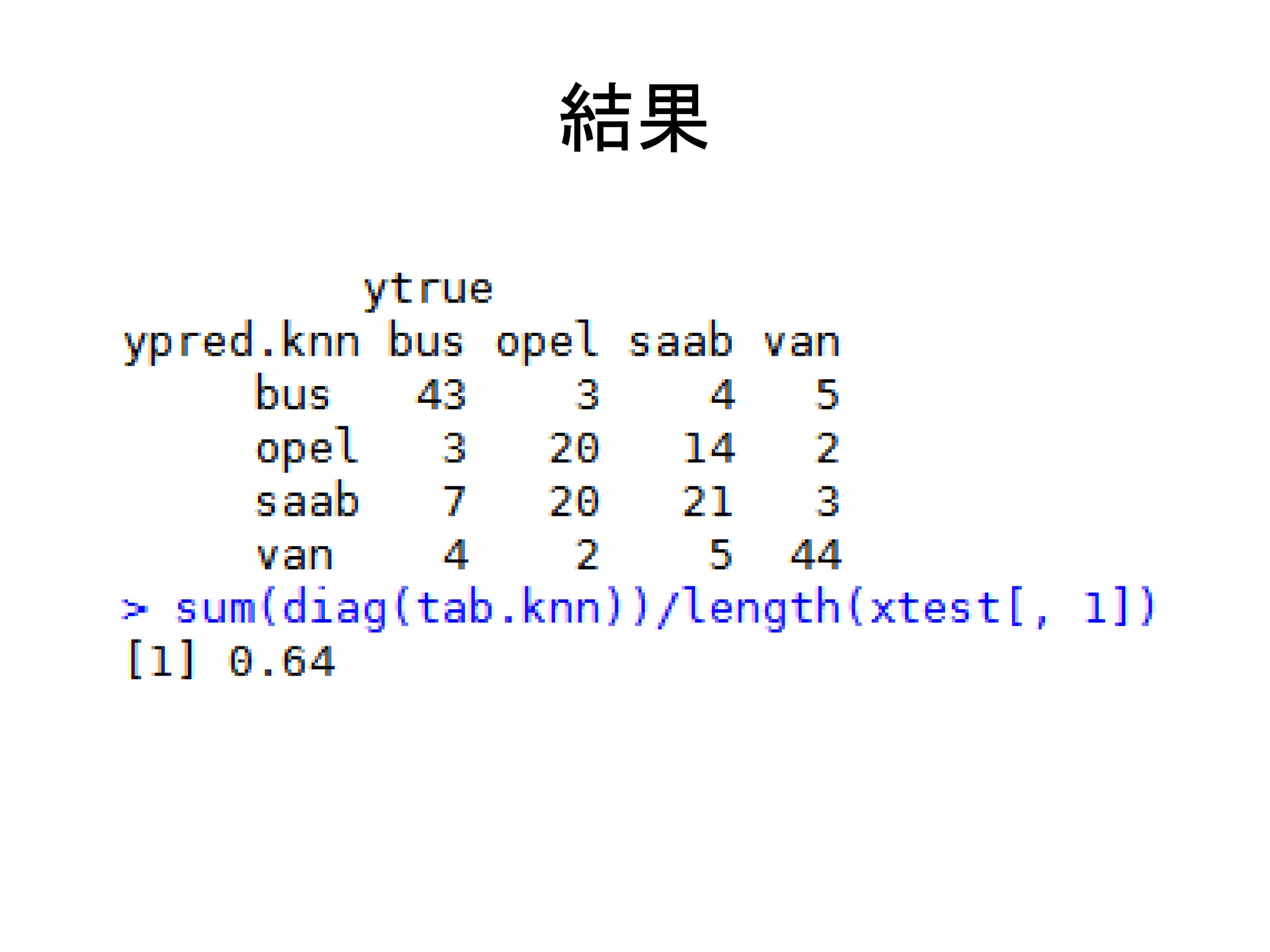
k-近傍法で予測する
library(class) Package class
library(mlbench)
data(Vehicle)
idtest<-seq(1,200)
idtrain<-seq(201,nrow(Vehicle))
xtest<-Vehicle[idtest, 1:18] テストデータの作成
ytrue<-Vehicle[idtest, 19]
xtrain<-Vehicle[idtrain, 1:18] トレーニングデータの作
ytrain<-Vehicle[idtrain, 19] 成
ypred.knn<-knn(xtrain, xtest, ytrain, k=3) 3-近傍法でで予測する
tab.knn<-table(ypred.knn, ytrue) クロス集計で結果を評
tab.knn
sum(diag(tab.knn))/length(xtest[, 1])
価する。
- 11.
- 12.
- 13.
LVQによる教師あり
多クラス判別問題
• 逐次型学習でコードブックベクトル(=モデ
ル)を学習する。
• SOMの教師あり版、k-平均法とk-近傍法のハ
イブリッドみたいなもの
– 学習:コードブックベクトルで空間をボロロイ分割
(k-平均法)
– 予測:コードブックベクトルでテストデータのラベ
ルk-近傍法で予測する。
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
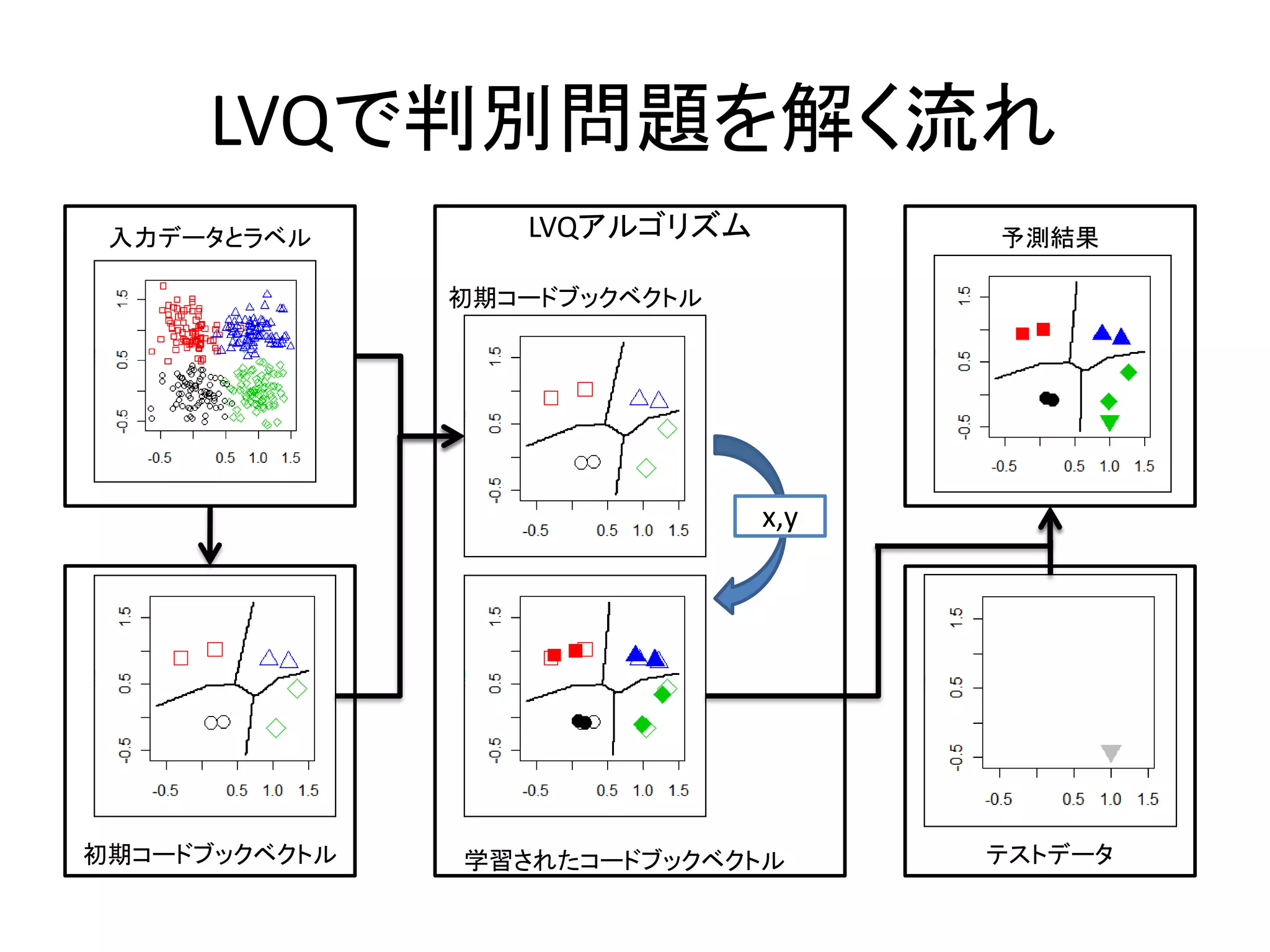
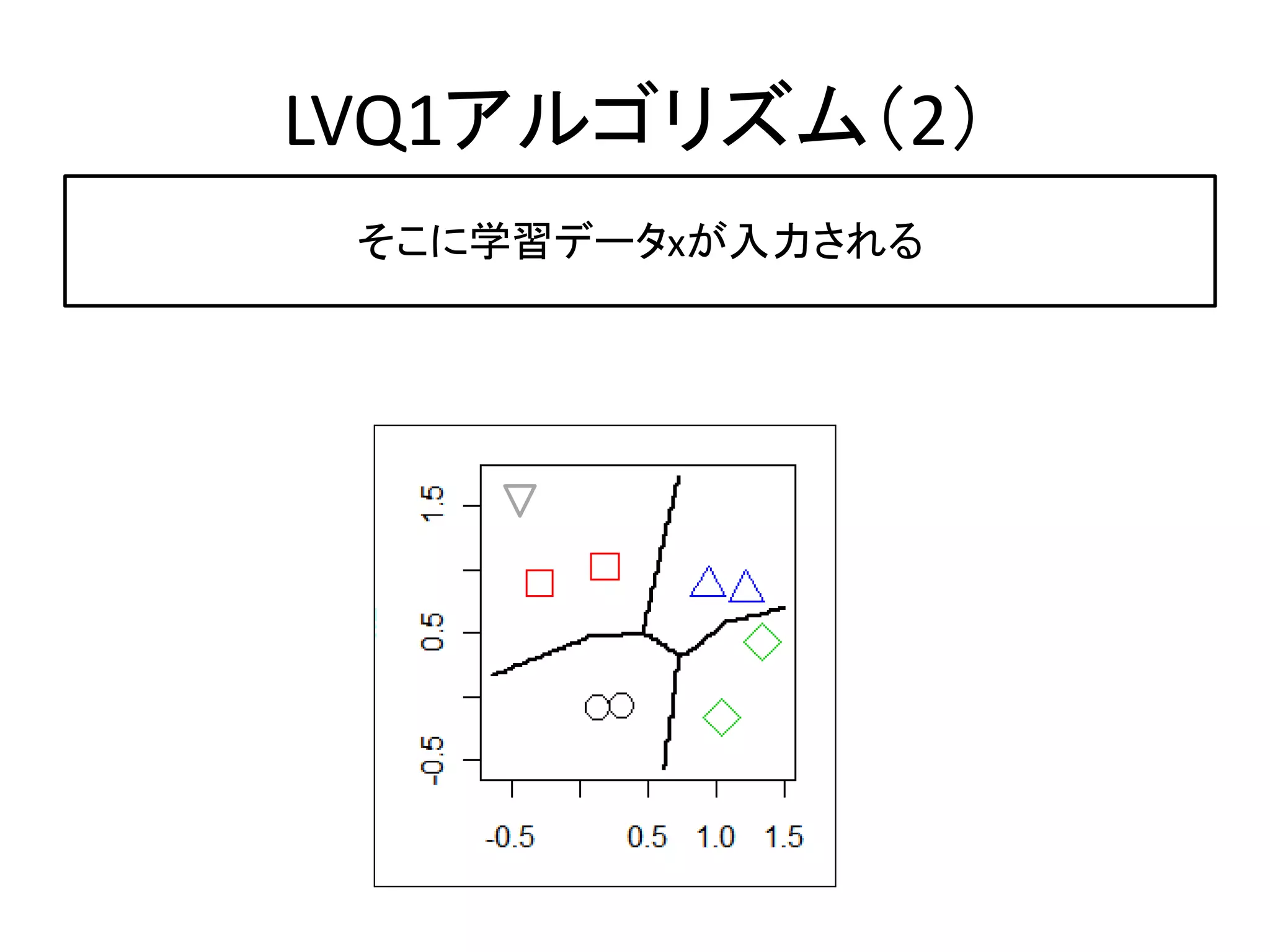
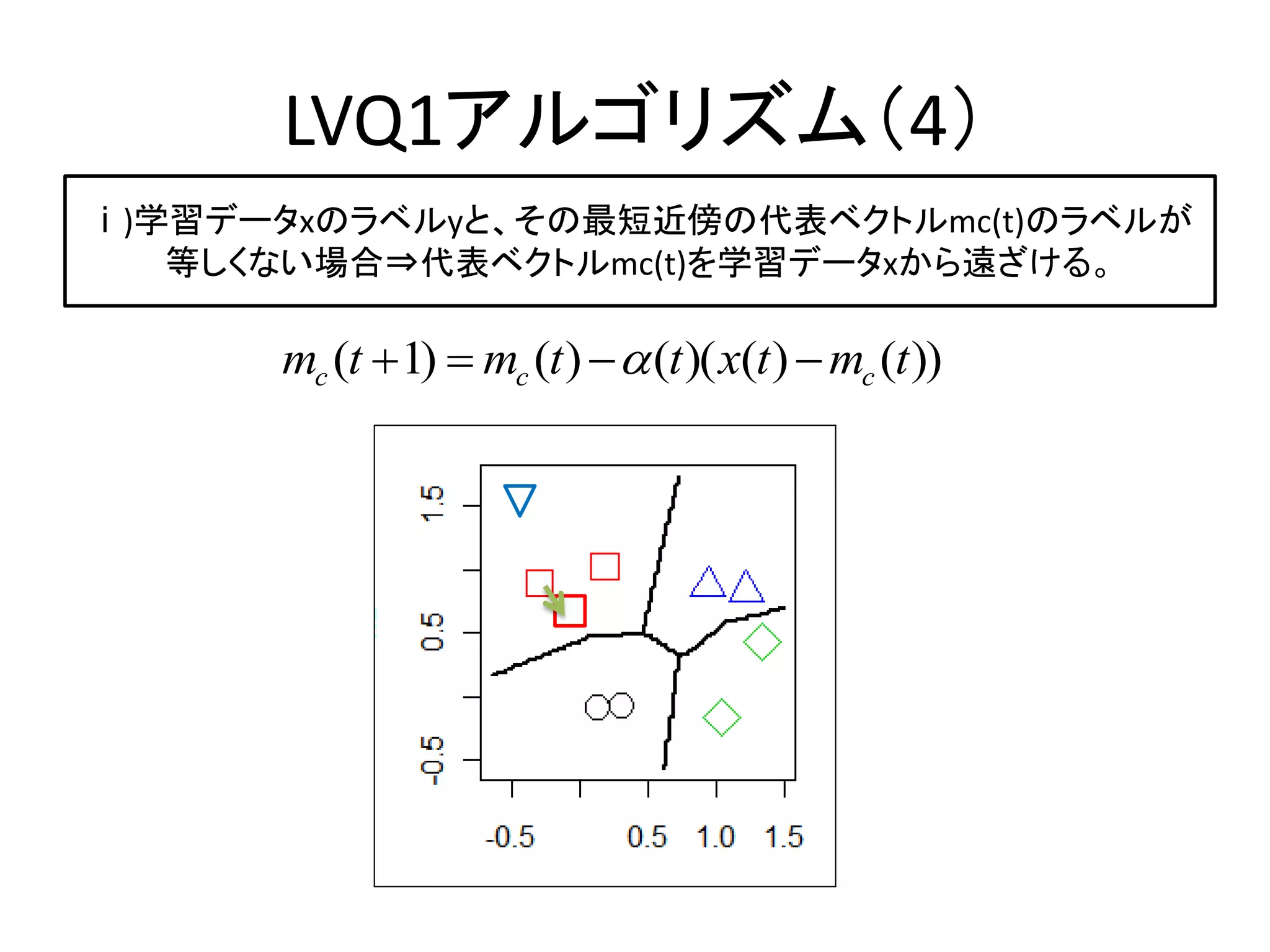
LVQで判別問題を解く
入力データとラベル LVQアルゴリズム=学習 予測結果
初期コードブックベクトル
lvq1
lvqinit x,y lvqtest
初期コードブックベクトル 学習されたコードブックベクトル テストデータ
- 24.
ClassパッケージのLVQ関数
初期コードブックを生成(k-近傍法でサンプリング)
lvqinit(x, cl, size, prior, k = 5)
LVQアルゴリズムでコードブックを生成
lvq1(x, cl, codebk, niter = 100 * nrow(codebk$x), alpha = 0.03)
コードブックを用いてテスト用にラベルを与える
lvqtest(codebk, test)
• Classパッケージ
- 25.
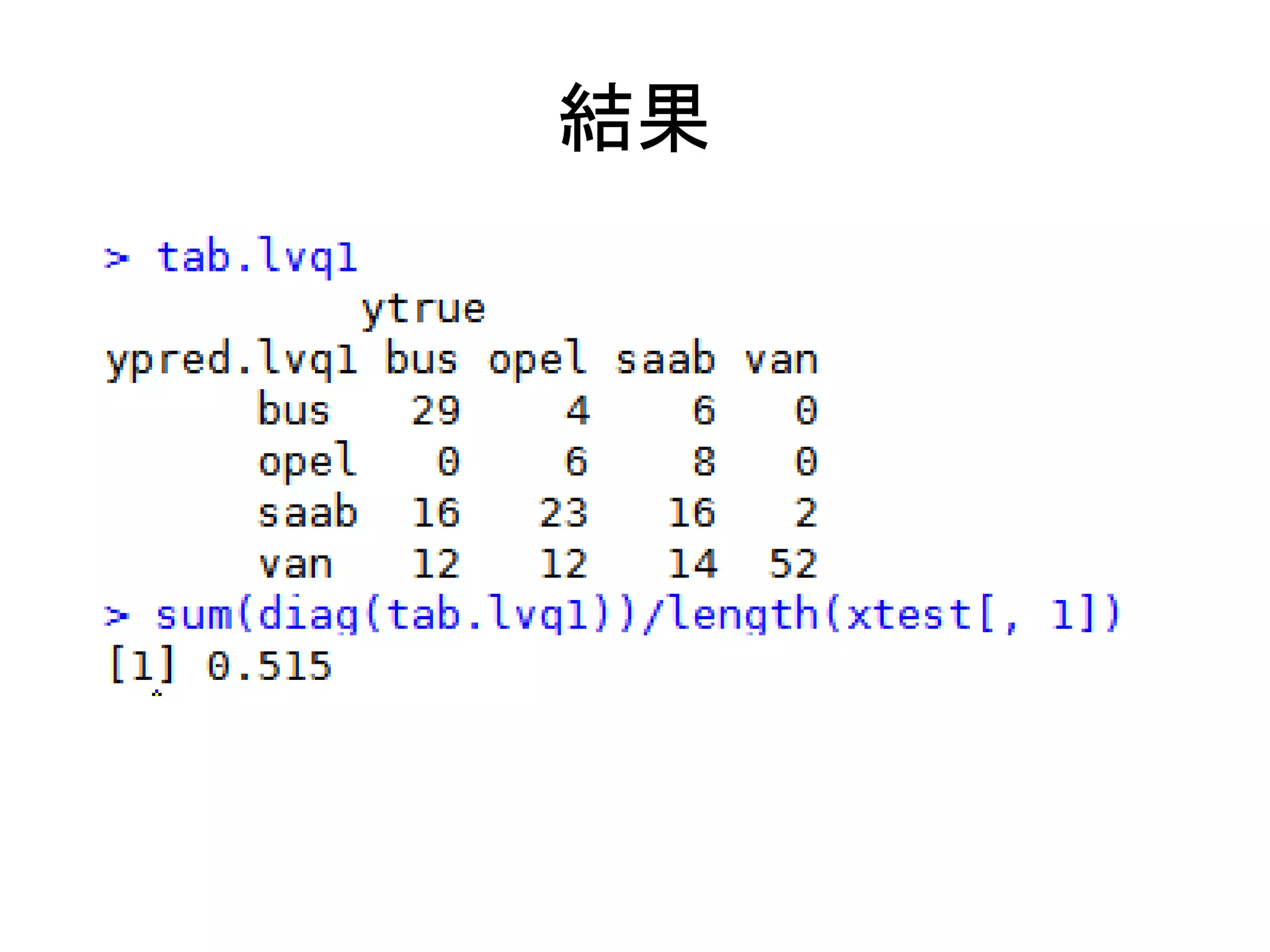
LVQ1で予測する
library(class) Package class
library(mlbench)
data(Vehicle)
idtest<-seq(1,200)
idtrain<-seq(201,nrow(Vehicle))
xtest<-Vehicle[idtest, 1:18]
ytrue<-Vehicle[idtest, 19] テストデータの作成
xtrain<-Vehicle[idtrain, 1:18]
ytrain<-Vehicle[idtrain, 19] 初期コードブックベクト
cdinit<-lvqinit(xtrain, ytrain,10) ルの生成
cdvec<-lvq1(xtrain, ytrain, cdinit)
ypred.lvq1<-lvqtest(cdvec, xtest)
LVQ1でコードブックベク
tab.lvq1<-table(ypred.lvq1, ytrue) トルの生成
tab.lvq1
sum(diag(tab.lvq1))/length(xtest[, 1]) クロス集計で結果を評
価する。
- 26.
- 27.








![k-近傍法で予測する
library(class) Package class
library(mlbench)
data(Vehicle)
idtest<-seq(1,200)
idtrain<-seq(201,nrow(Vehicle))
xtest<-Vehicle[idtest, 1:18] テストデータの作成
ytrue<-Vehicle[idtest, 19]
xtrain<-Vehicle[idtrain, 1:18] トレーニングデータの作
ytrain<-Vehicle[idtrain, 19] 成
ypred.knn<-knn(xtrain, xtest, ytrain, k=3) 3-近傍法でで予測する
tab.knn<-table(ypred.knn, ytrue) クロス集計で結果を評
tab.knn
sum(diag(tab.knn))/length(xtest[, 1])
価する。](https://image.slidesharecdn.com/08-09k-lvq-110717231234-phpapp02/75/08-09-k-lvq-10-2048.jpg)










![LVQ1で予測する
library(class) Package class
library(mlbench)
data(Vehicle)
idtest<-seq(1,200)
idtrain<-seq(201,nrow(Vehicle))
xtest<-Vehicle[idtest, 1:18]
ytrue<-Vehicle[idtest, 19] テストデータの作成
xtrain<-Vehicle[idtrain, 1:18]
ytrain<-Vehicle[idtrain, 19] 初期コードブックベクト
cdinit<-lvqinit(xtrain, ytrain,10) ルの生成
cdvec<-lvq1(xtrain, ytrain, cdinit)
ypred.lvq1<-lvqtest(cdvec, xtest)
LVQ1でコードブックベク
tab.lvq1<-table(ypred.lvq1, ytrue) トルの生成
tab.lvq1
sum(diag(tab.lvq1))/length(xtest[, 1]) クロス集計で結果を評
価する。](https://image.slidesharecdn.com/08-09k-lvq-110717231234-phpapp02/75/08-09-k-lvq-25-2048.jpg)