Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yasutomo Kawanishi
PDF, PPTX
86,836 views
Pythonによる機械学習入門 ~Deep Learningに挑戦~
IEEE ITSS Nagoya Chapterでの講演資料
Technology
◦
Related topics:
Deep Learning
•
Read more
105
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 81
2
/ 81
Most read
3
/ 81
4
/ 81
Most read
5
/ 81
6
/ 81
7
/ 81
8
/ 81
Most read
9
/ 81
10
/ 81
11
/ 81
12
/ 81
13
/ 81
14
/ 81
15
/ 81
16
/ 81
17
/ 81
18
/ 81
19
/ 81
20
/ 81
21
/ 81
22
/ 81
23
/ 81
24
/ 81
25
/ 81
26
/ 81
27
/ 81
28
/ 81
29
/ 81
30
/ 81
31
/ 81
32
/ 81
33
/ 81
34
/ 81
35
/ 81
36
/ 81
37
/ 81
38
/ 81
39
/ 81
40
/ 81
41
/ 81
42
/ 81
43
/ 81
44
/ 81
45
/ 81
46
/ 81
47
/ 81
48
/ 81
49
/ 81
50
/ 81
51
/ 81
52
/ 81
53
/ 81
54
/ 81
55
/ 81
56
/ 81
57
/ 81
58
/ 81
59
/ 81
60
/ 81
61
/ 81
62
/ 81
63
/ 81
64
/ 81
65
/ 81
66
/ 81
67
/ 81
68
/ 81
69
/ 81
70
/ 81
71
/ 81
72
/ 81
73
/ 81
74
/ 81
75
/ 81
76
/ 81
77
/ 81
78
/ 81
79
/ 81
80
/ 81
81
/ 81
More Related Content
PDF
新分野に飛び入って半年で業績を作るには
by
Asai Masataro
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
文字認識はCNNで終わるのか?
by
Seiichi Uchida
PDF
レコメンドエンジン作成コンテストの勝ち方
by
Shun Nukui
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PPTX
2014 3 13(テンソル分解の基礎)
by
Tatsuya Yokota
PPTX
BERT分類ワークショップ.pptx
by
Kouta Nakayama
PPTX
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
新分野に飛び入って半年で業績を作るには
by
Asai Masataro
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
文字認識はCNNで終わるのか?
by
Seiichi Uchida
レコメンドエンジン作成コンテストの勝ち方
by
Shun Nukui
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
2014 3 13(テンソル分解の基礎)
by
Tatsuya Yokota
BERT分類ワークショップ.pptx
by
Kouta Nakayama
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
What's hot
PDF
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
PDF
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
by
JunSuzuki21
PDF
XGBoostからNGBoostまで
by
Tomoki Yoshida
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
自然言語処理による議論マイニング
by
Naoaki Okazaki
PPTX
画像処理基礎
by
大貴 末廣
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
PDF
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
PDF
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
PPTX
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
PPTX
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
PDF
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
by
Deep Learning JP
PDF
機械学習による生存予測
by
Yasuaki Sakamoto
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PDF
[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...
by
Deep Learning JP
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
PDF
(2021.10) 機械学習と機械発見 データ中心型の化学・材料科学の教訓とこれから
by
Ichigaku Takigawa
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
by
JunSuzuki21
XGBoostからNGBoostまで
by
Tomoki Yoshida
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
自然言語処理による議論マイニング
by
Naoaki Okazaki
画像処理基礎
by
大貴 末廣
強化学習 DQNからPPOまで
by
harmonylab
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
by
Deep Learning JP
機械学習による生存予測
by
Yasuaki Sakamoto
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...
by
Deep Learning JP
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
(2021.10) 機械学習と機械発見 データ中心型の化学・材料科学の教訓とこれから
by
Ichigaku Takigawa
Viewers also liked
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
PDF
一般向けのDeep Learning
by
Preferred Networks
PDF
サービスサイエンス 〜サービスイノベーションの創出に向けて〜
by
Yuriko Sawatani
PDF
言語と画像の表現学習
by
Yuki Noguchi
PDF
単語・句の分散表現の学習
by
Naoaki Okazaki
PPTX
Lecture 29 Convolutional Neural Networks - Computer Vision Spring2015
by
Jia-Bin Huang
PDF
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
PPTX
ディープラーニングで株価予測をやってみた
by
卓也 安東
PPTX
アルゴリズム取引のシステムを開発・運用してみて分かったこと
by
Satoshi KOBAYASHI
PDF
Deep Residual Learning (ILSVRC2015 winner)
by
Hirokatsu Kataoka
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PDF
OpenCVをAndroidで動かしてみた
by
徹 上野山
KEY
OpenCVの基礎
by
領一 和泉田
PDF
最新業界事情から見るデータサイエンティストの「実像」
by
Takashi J OZAKI
PDF
OpenCV 3.0 on iOS
by
Shuichi Tsutsumi
PDF
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
PDF
機械学習概論 講義テキスト
by
Etsuji Nakai
PDF
Introduction to Chainer
by
Shunta Saito
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
一般向けのDeep Learning
by
Preferred Networks
サービスサイエンス 〜サービスイノベーションの創出に向けて〜
by
Yuriko Sawatani
言語と画像の表現学習
by
Yuki Noguchi
単語・句の分散表現の学習
by
Naoaki Okazaki
Lecture 29 Convolutional Neural Networks - Computer Vision Spring2015
by
Jia-Bin Huang
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
ディープラーニングで株価予測をやってみた
by
卓也 安東
アルゴリズム取引のシステムを開発・運用してみて分かったこと
by
Satoshi KOBAYASHI
Deep Residual Learning (ILSVRC2015 winner)
by
Hirokatsu Kataoka
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
OpenCVをAndroidで動かしてみた
by
徹 上野山
OpenCVの基礎
by
領一 和泉田
最新業界事情から見るデータサイエンティストの「実像」
by
Takashi J OZAKI
OpenCV 3.0 on iOS
by
Shuichi Tsutsumi
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
機械学習概論 講義テキスト
by
Etsuji Nakai
Introduction to Chainer
by
Shunta Saito
Similar to Pythonによる機械学習入門 ~Deep Learningに挑戦~
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PPTX
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
画像認識で物を見分ける
by
Kazuaki Tanida
PDF
Machine learning CI/CD with OSS
by
yusuke shibui
PPTX
[輪講] 第1章
by
Takenobu Sasatani
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
Python初心者がKerasで画像判別をやってみた
by
KAIKenzo
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
PPTX
機械学習 - MNIST の次のステップ
by
Daiyu Hatakeyama
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
PDF
機械学習 入門
by
Hayato Maki
PPTX
Azure Machine Learning services 2019年6月版
by
Daiyu Hatakeyama
PDF
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
by
Takashi J OZAKI
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PDF
機械学習の理論と実践
by
Preferred Networks
PPTX
[機械学習]文章のクラス分類
by
Tetsuya Hasegawa
PPTX
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
画像認識で物を見分ける
by
Kazuaki Tanida
Machine learning CI/CD with OSS
by
yusuke shibui
[輪講] 第1章
by
Takenobu Sasatani
機械学習の基礎
by
Ken Kumagai
Python初心者がKerasで画像判別をやってみた
by
KAIKenzo
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
機械学習 - MNIST の次のステップ
by
Daiyu Hatakeyama
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
機械学習 入門
by
Hayato Maki
Azure Machine Learning services 2019年6月版
by
Daiyu Hatakeyama
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
by
Takashi J OZAKI
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
機械学習の理論と実践
by
Preferred Networks
[機械学習]文章のクラス分類
by
Tetsuya Hasegawa
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
More from Yasutomo Kawanishi
PDF
TransPose: Towards Explainable Human Pose Estimation by Transformer
by
Yasutomo Kawanishi
PDF
全日本コンピュータビジョン勉強会:Disentangling and Unifying Graph Convolutions for Skeleton-B...
by
Yasutomo Kawanishi
PPTX
Pythonによる画像処理について
by
Yasutomo Kawanishi
PPTX
ACCV2014参加報告
by
Yasutomo Kawanishi
PDF
背景モデリングに関する研究など
by
Yasutomo Kawanishi
PDF
画像処理でのPythonの利用
by
Yasutomo Kawanishi
PDF
第17回関西CVPRML勉強会 (一般物体認識) 1,2節
by
Yasutomo Kawanishi
PPTX
SNSでひろがるプライバシ制御センシング
by
Yasutomo Kawanishi
KEY
SHOGUN使ってみました
by
Yasutomo Kawanishi
TransPose: Towards Explainable Human Pose Estimation by Transformer
by
Yasutomo Kawanishi
全日本コンピュータビジョン勉強会:Disentangling and Unifying Graph Convolutions for Skeleton-B...
by
Yasutomo Kawanishi
Pythonによる画像処理について
by
Yasutomo Kawanishi
ACCV2014参加報告
by
Yasutomo Kawanishi
背景モデリングに関する研究など
by
Yasutomo Kawanishi
画像処理でのPythonの利用
by
Yasutomo Kawanishi
第17回関西CVPRML勉強会 (一般物体認識) 1,2節
by
Yasutomo Kawanishi
SNSでひろがるプライバシ制御センシング
by
Yasutomo Kawanishi
SHOGUN使ってみました
by
Yasutomo Kawanishi
Pythonによる機械学習入門 ~Deep Learningに挑戦~
1.
Pythonによる機械学習⼊⾨ 〜Deep Learningに挑戦〜 ITSS名古屋チャプタ2016年度 第1回講演会 2016/07/15 名古屋⼤学
情報科学研究科 メディア科学専攻 助教 川⻄康友
2.
本⽇の内容 l機械学習 lプログラミング⾔語Python lPythonでの機械学習 l各種⼿法の⽐較 lDeep Learningの利⽤ (Chainer
/ Keras) lまとめ サンプルコードはgithubにあります https://github.com/yasutomo57jp/ssii2016_tutorial https://github.com/yasutomo57jp/deeplearning_samples
3.
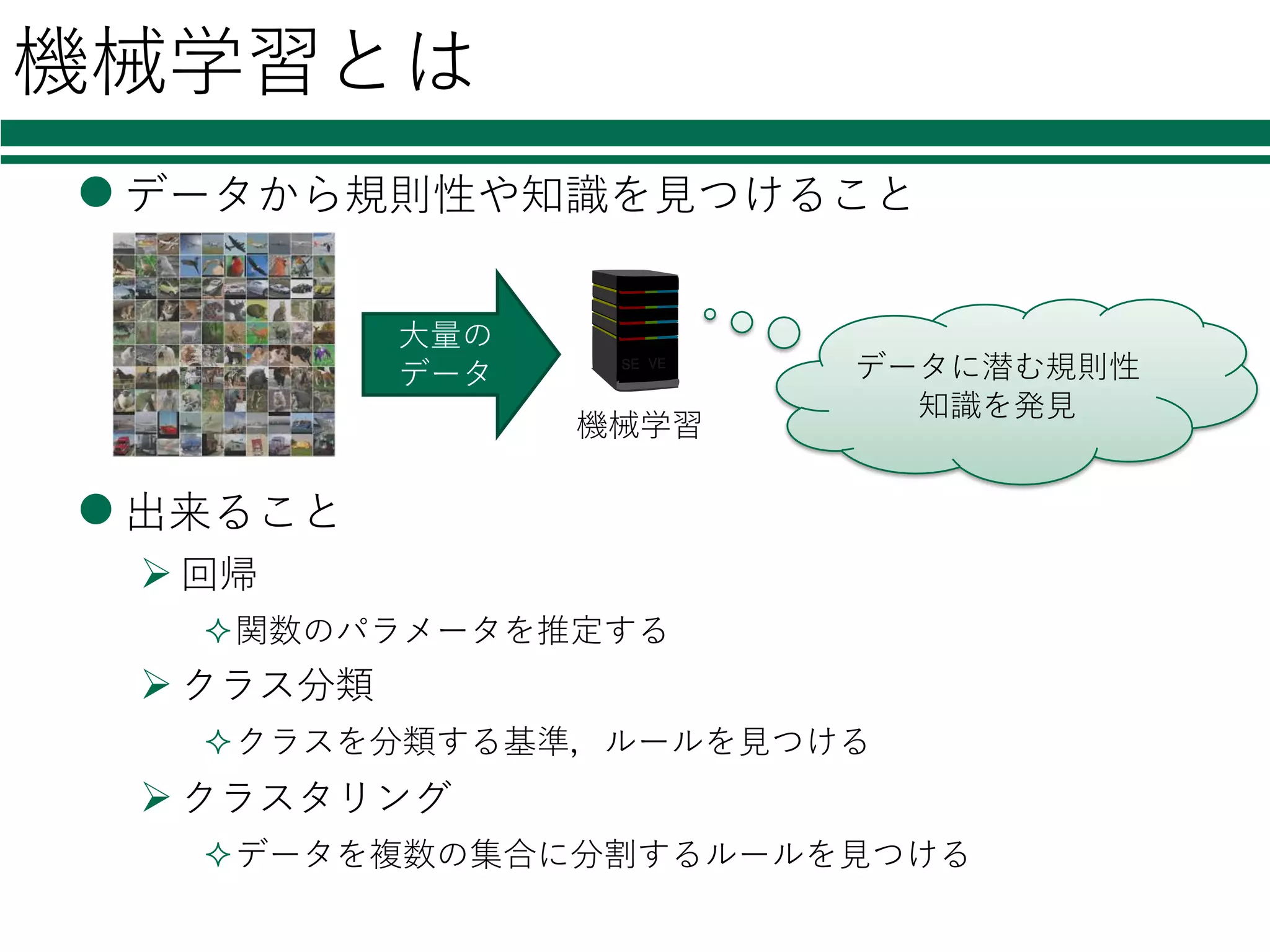
機械学習とは l データから規則性や知識を⾒つけること l 出来ること Ø
回帰 ²関数のパラメータを推定する Ø クラス分類 ²クラスを分類する基準,ルールを⾒つける Ø クラスタリング ²データを複数の集合に分割するルールを⾒つける データに潜む規則性 知識を発⾒ ⼤量の データ 機械学習
4.
機械学習の例:多クラス分類 l画像分類問題 Ø画像を⼊⼒として,どのクラスに属するかを出⼒ Ø例 ²MNIST:⼿書き⽂字認識 ²bird-200:⿃の200種分類問題 ²Caltech-101:101種類の物体認識 分類する基準を, ⼤量の学習データから 機械学習によって獲得する
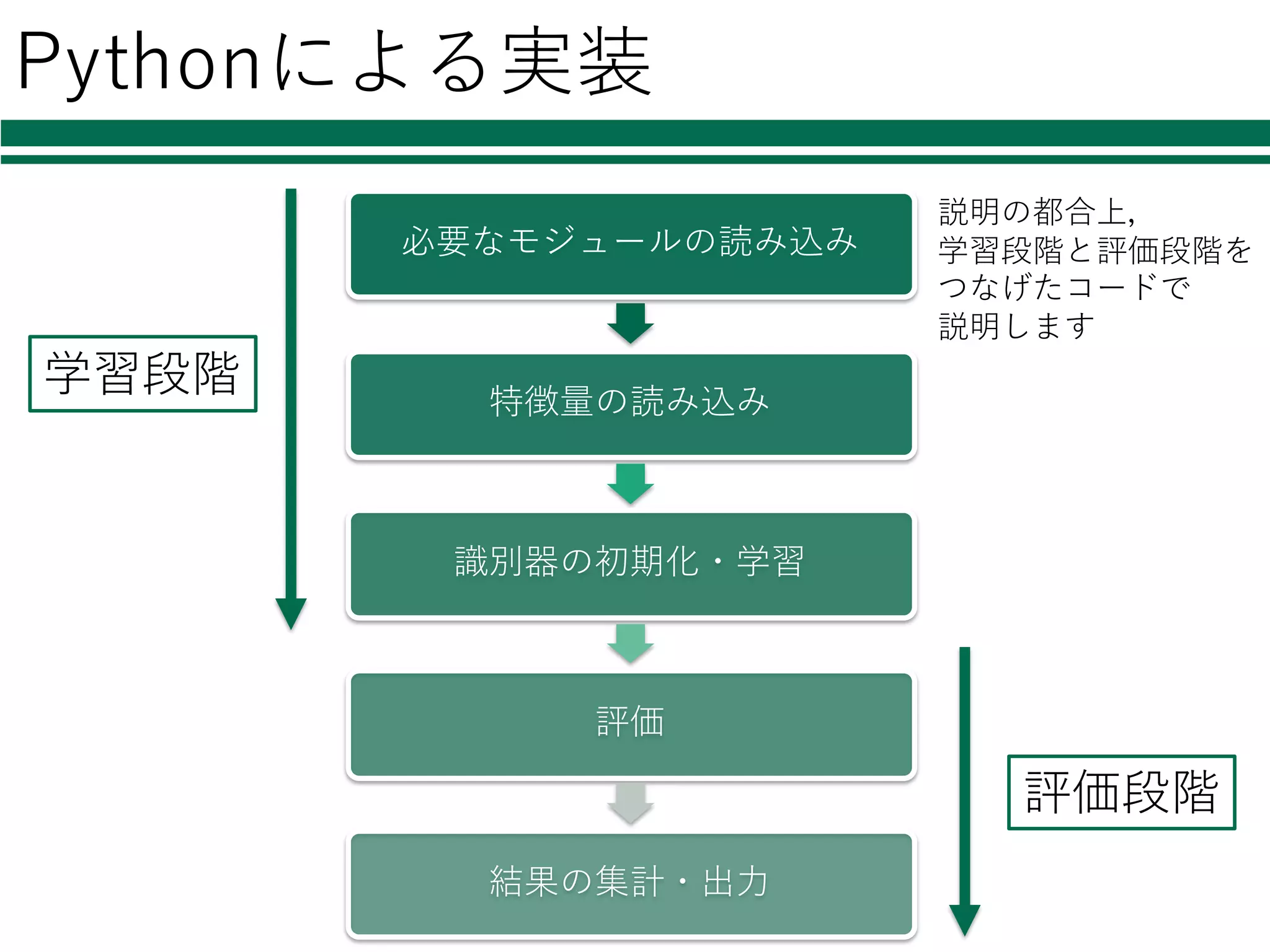
5.
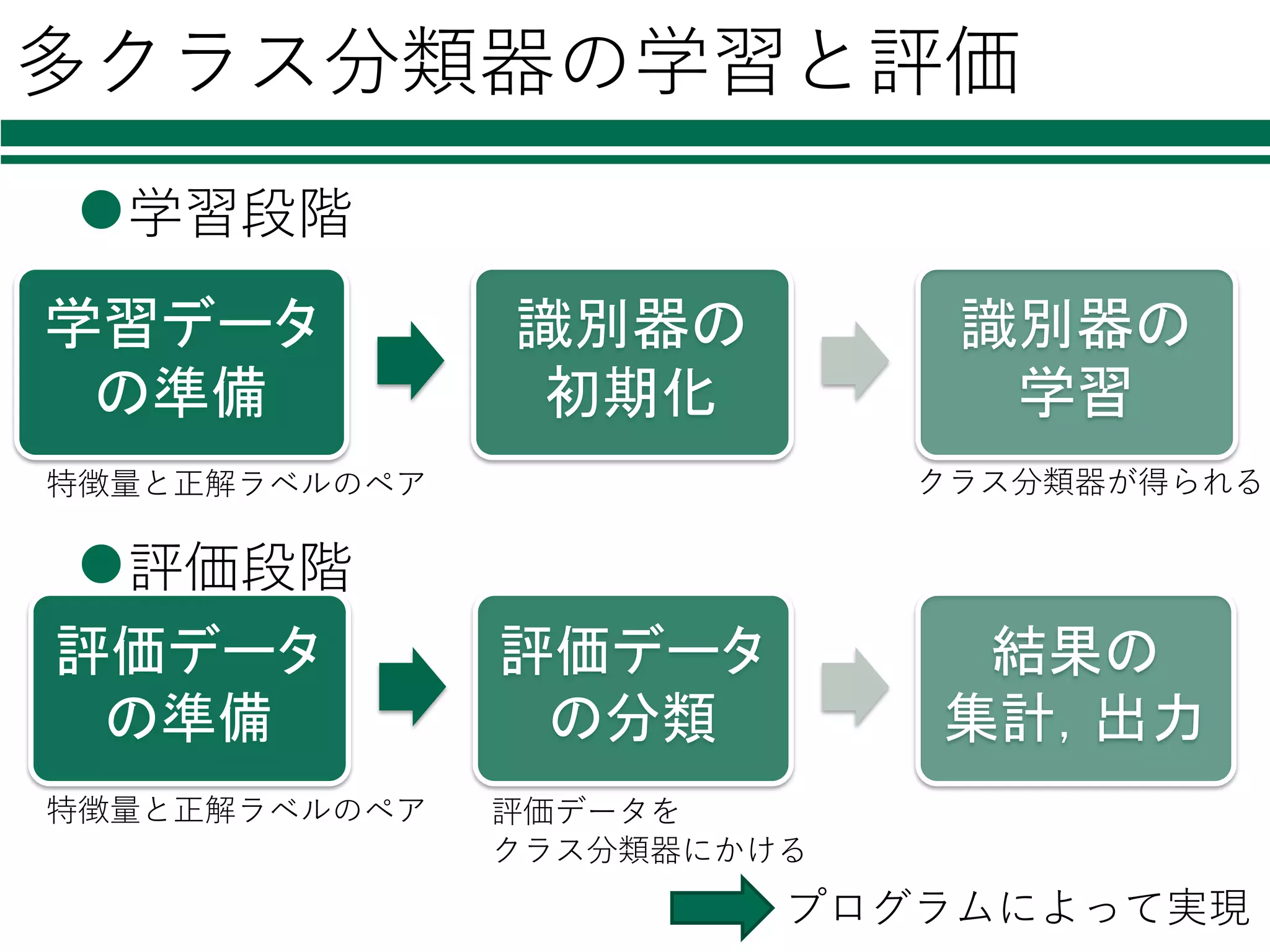
多クラス分類器の学習と評価 l学習段階 l評価段階 学習データ の準備 識別器の 初期化 識別器の 学習 評価データ の準備 評価データ の分類 結果の 集計,出力 プログラムによって実現 特徴量と正解ラベルのペア 評価データを クラス分類器にかける クラス分類器が得られる特徴量と正解ラベルのペア
6.
多クラス分類器の実現 lよく使われるプログラミング⾔語/ツール ØC/C++ ØMatlab ØR ØPython Øその他(GUIで⼿軽に使えるもの) ²Weka (Java), Orange(Python),
… ⼈⼯知能(機械学習)ブーム + 機械学習ではPythonがよく使われる
7.
Pythonのいいところ l無料で使える l実⾏・デバッグが容易 Øスクリプト⾔語であるメリット lシンプルで覚えやすい Ø基本的な⽂法が簡単 lどの環境でも動く ØWin, Mac, Linux l様々なモジュールが存在 lC/C++との組み合わせも可能
8.
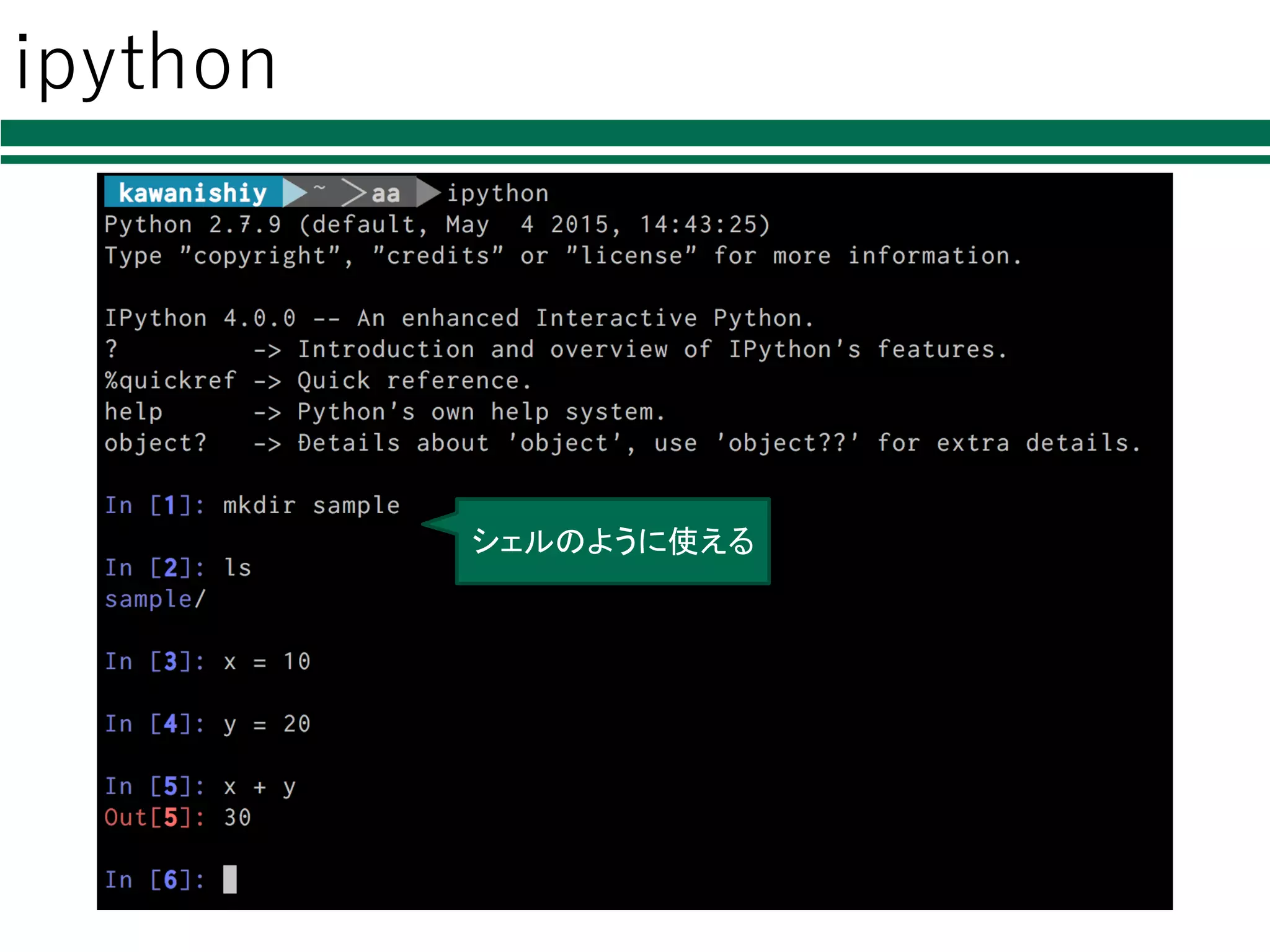
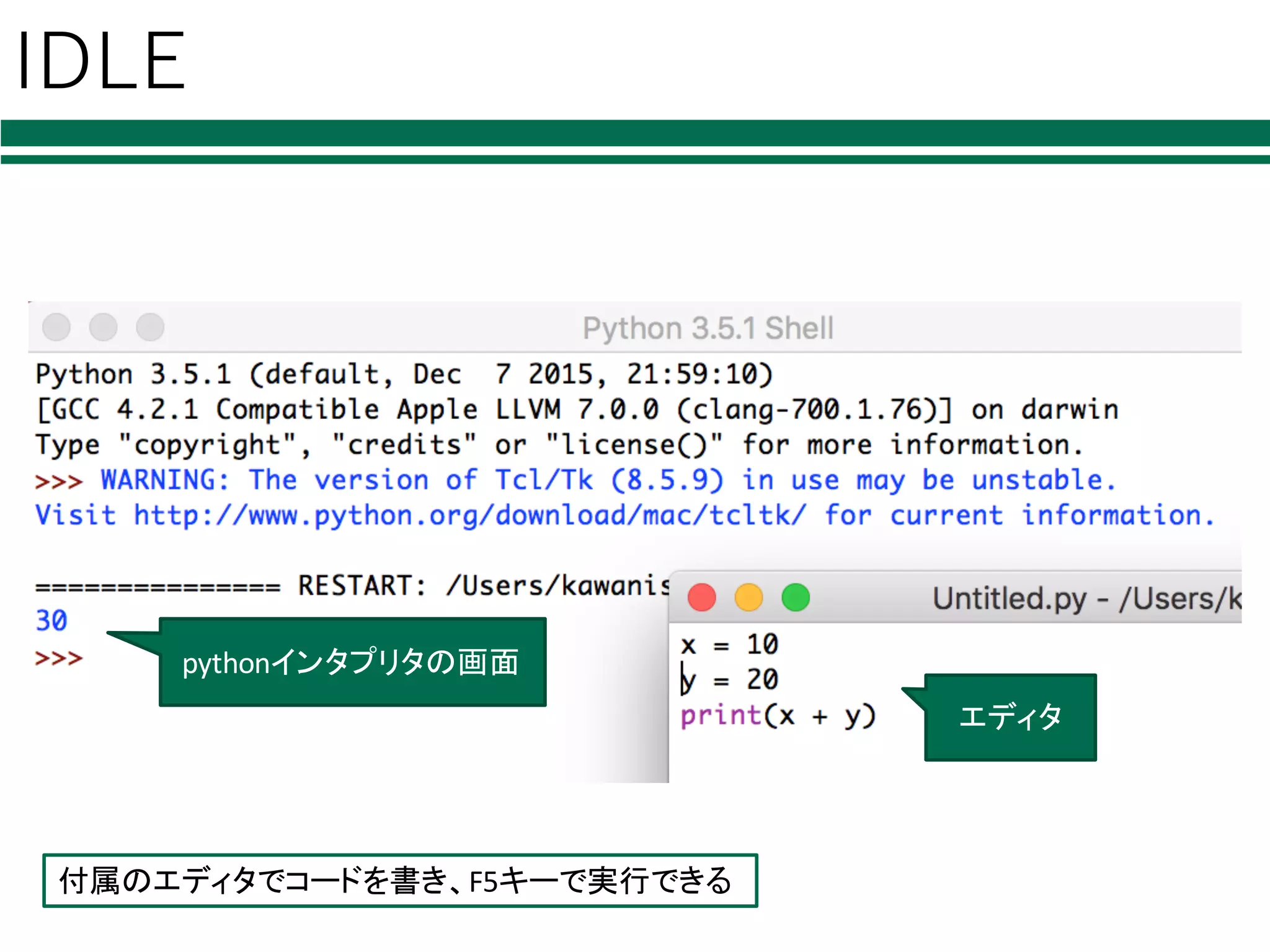
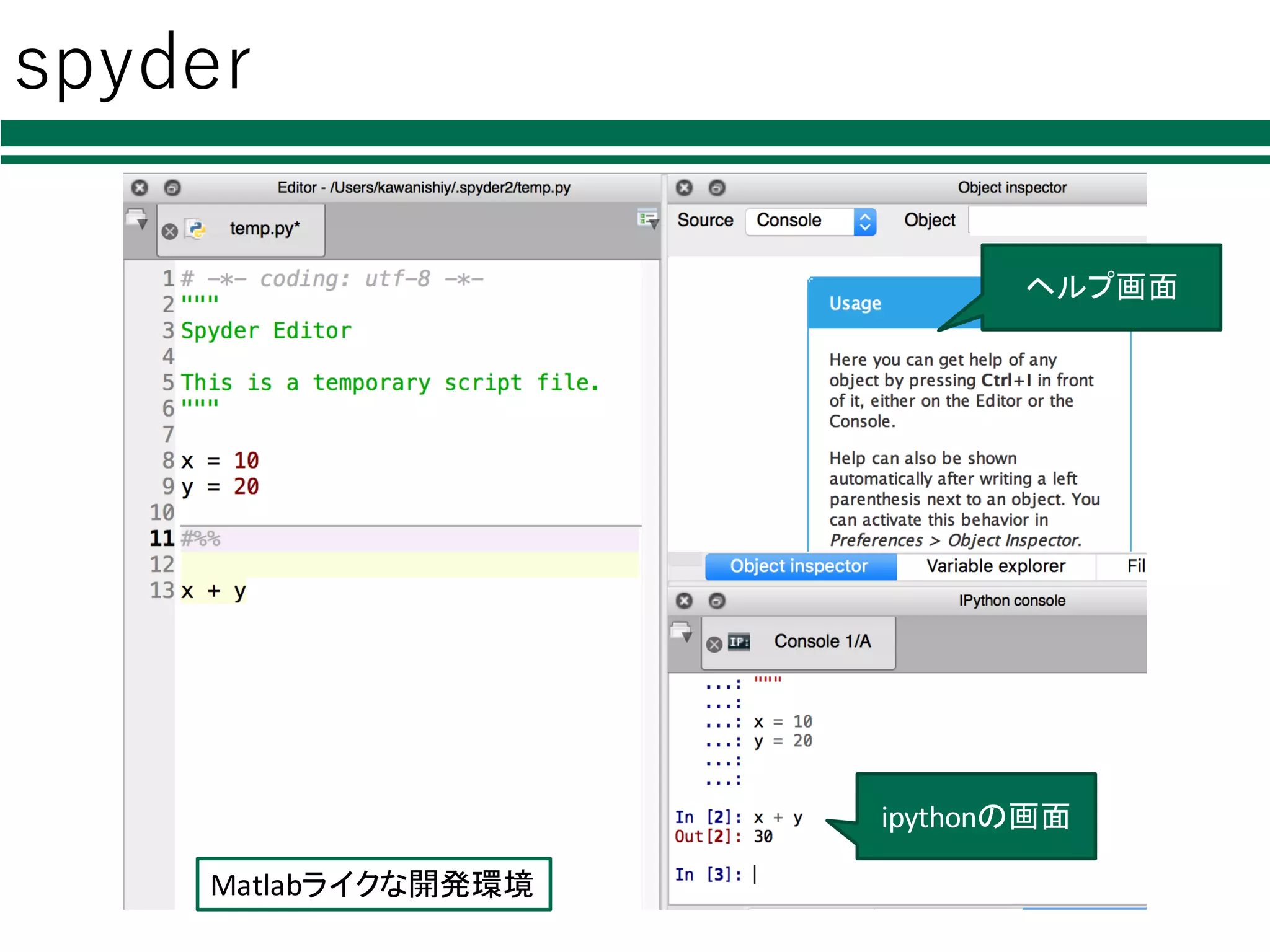
様々なPython環境 lpythonインタプリタ Øpythonコードを1⾏ずつ⼊⼒・実⾏ lエディタ+pythonインタプリタ Ø好きなエディタでコードを書く Øpython hoge.py で実⾏ lipython(インタラクティブPython) Øシェル機能を搭載したpythonインタプリタ lIDLE,
spyder, PyCharm, Eclipse+PyDev Ø統合開発環境
9.
pythonインタプリタ
10.
ipython シェルのように使える
11.
IDLE 付属のエディタでコードを書き、F5キーで実行できる pythonインタプリタの画面 エディタ
12.
spyder Matlabライクな開発環境 ipythonの画面 ヘルプ画面
13.
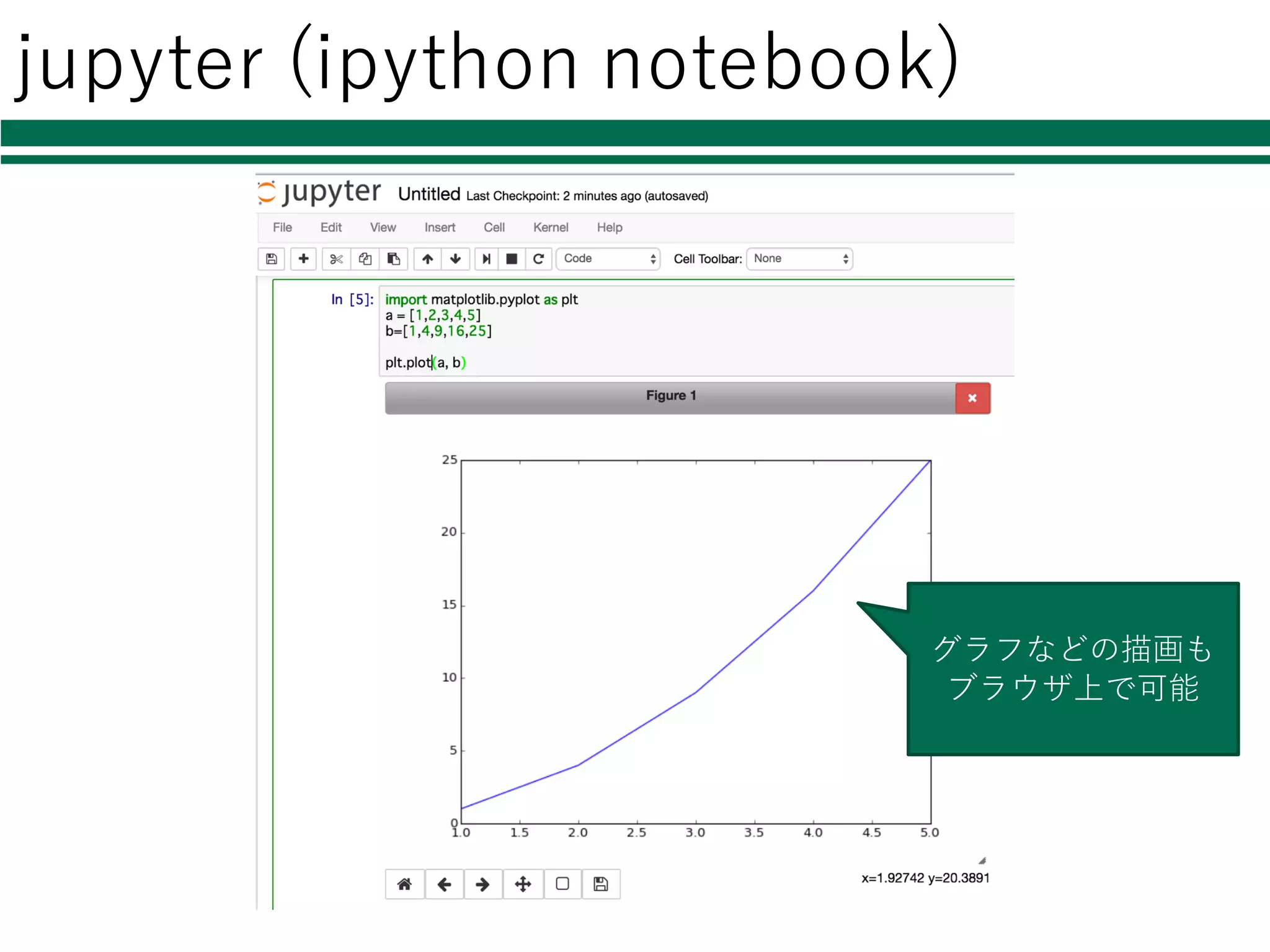
jupyter (ipython notebook) ブラウザ上でipythonの 実⾏結果を表⽰
14.
jupyter (ipython notebook) グラフなどの描画も ブラウザ上で可能
15.
Pythonとモジュール l Pythonは基本機能はとてもシンプル Ø 拡張モジュールが豊富 ²
⾏列演算など:numpy ² 科学技術計算など:scipy ² グラフの描画など:matplotlib ² 機械学習:scikit-learn ² ディープラーニング:pylearn2, caffe, chainer, keras ² 画像処理:pillow, scikit-image, opencv ² シミュレーション:simpy ² 解析的な計算:theano ² インタラクティブシェル:ipython Ø https://pypi.python.org/pypi で公開 ² easy_install コマンドや,pip コマンドで簡単にインストール可能 ² ⾃作モジュールを簡単に公開できる機能もある
16.
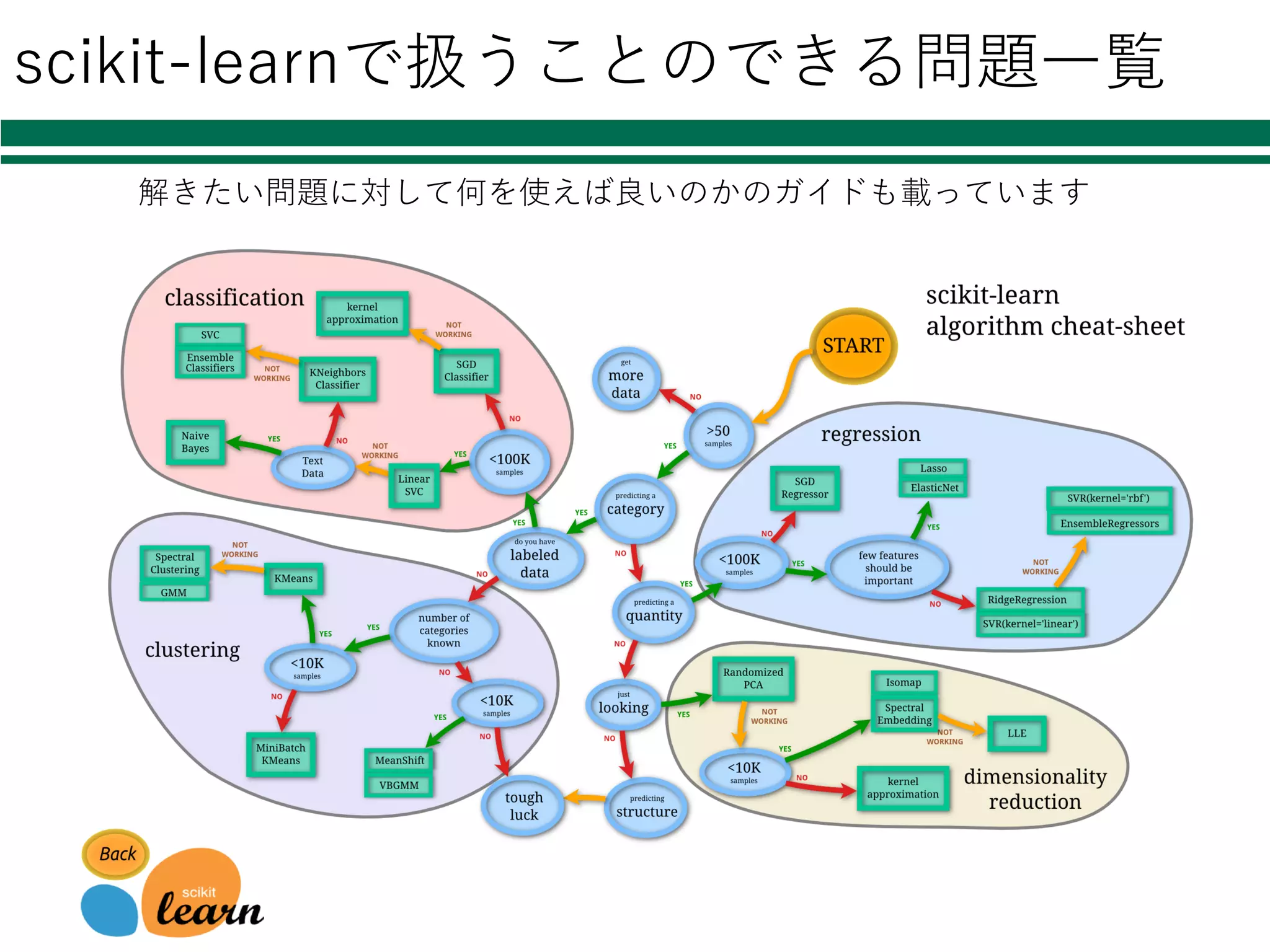
Pythonでの機械学習 l機械学習パッケージ scikit-learn Øhttp://scikit-learn.org/ Ø機械学習に関する 様々な⼿法が実装されたライブラリ ²クラス分類 ²クラスタリング ²回帰 ²データマイニング ØBSDライセンス
17.
scikit-learnで扱うことのできる問題⼀覧 解きたい問題に対して何を使えば良いのかのガイドも載っています
18.
多クラス分類問題の例題 lMNIST database of
handwritten digits Ø0〜9の⼿書き数字認識問題 Ø7万枚の画像+正解ラベル Ø例題としてよく利⽤される Øscikit-learnでもデータセットが提供されている ²fetch_mldata("MNIST original") で取得可能
19.
Pythonによる実装 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ 学習段階 評価段階 説明の都合上, 学習段階と評価段階を つなげたコードで 説明します
20.
Pythonによる実装 線形Support Vector Machine
(線形SVM)を使った実装例 1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.datasets import fetch_mldata from sklearn.cross_validation import train_test_split from sklearn.svm import LinearSVC as Classifier from sklearn.metrics import confusion_matrix import numpy as np mnist = fetch_mldata("MNIST original", data_home=".") data = np.asarray(mnist.data, np.float32) data_train, data_test, label_train, label_test = train_test_split(data, mnist.target, test_size=0.2) classifier = Classifier() classifier.fit(data_train, label_train) result = classifier.predict(data_test) cmat = confusion_matrix(label_test, result) print(cmat) たった13行で書けてしまう!
21.
Pythonによる実装 from sklearn.datasets import
fetch_mldata from sklearn.cross_validation import train_test_split from sklearn.svm import LinearSVC as Classifier from sklearn.metrics import confusion_matrix import numpy as np mnist = fetch_mldata("MNIST original", data_home=" data = np.asarray(mnist.data, np.float32) data_train, data_test, label_train, label_test = t classifier = Classifier() classifier.fit(data_train, label_train) result = classifier.predict(data_test) cmat = confusion_matrix(label_test, result) print(cmat) 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒
22.
特徴量の読み込み 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ [[0, 0, 0,
..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.] minst.targetmnist.data 特徴量とラベルの表現形式 学習⽤正解ラベル学習⽤特徴量 numpyのndarray(多次元配列)形式 1⾏が1つの特徴量.それに対応するラベル. (サンプル数, 特徴量)の⾏列
23.
特徴量の読み込み 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ data_train, data_test, label_train,
label_test = ¥ train_test_split(data, mnist.target, test_size=0.2) 特徴量と正解ラベルを 学習データと評価データへ分割 [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.] mnist.data mnist.target data_test label_testdata_train label_train 学習データ 評価データ 2割を評価用 にする
24.
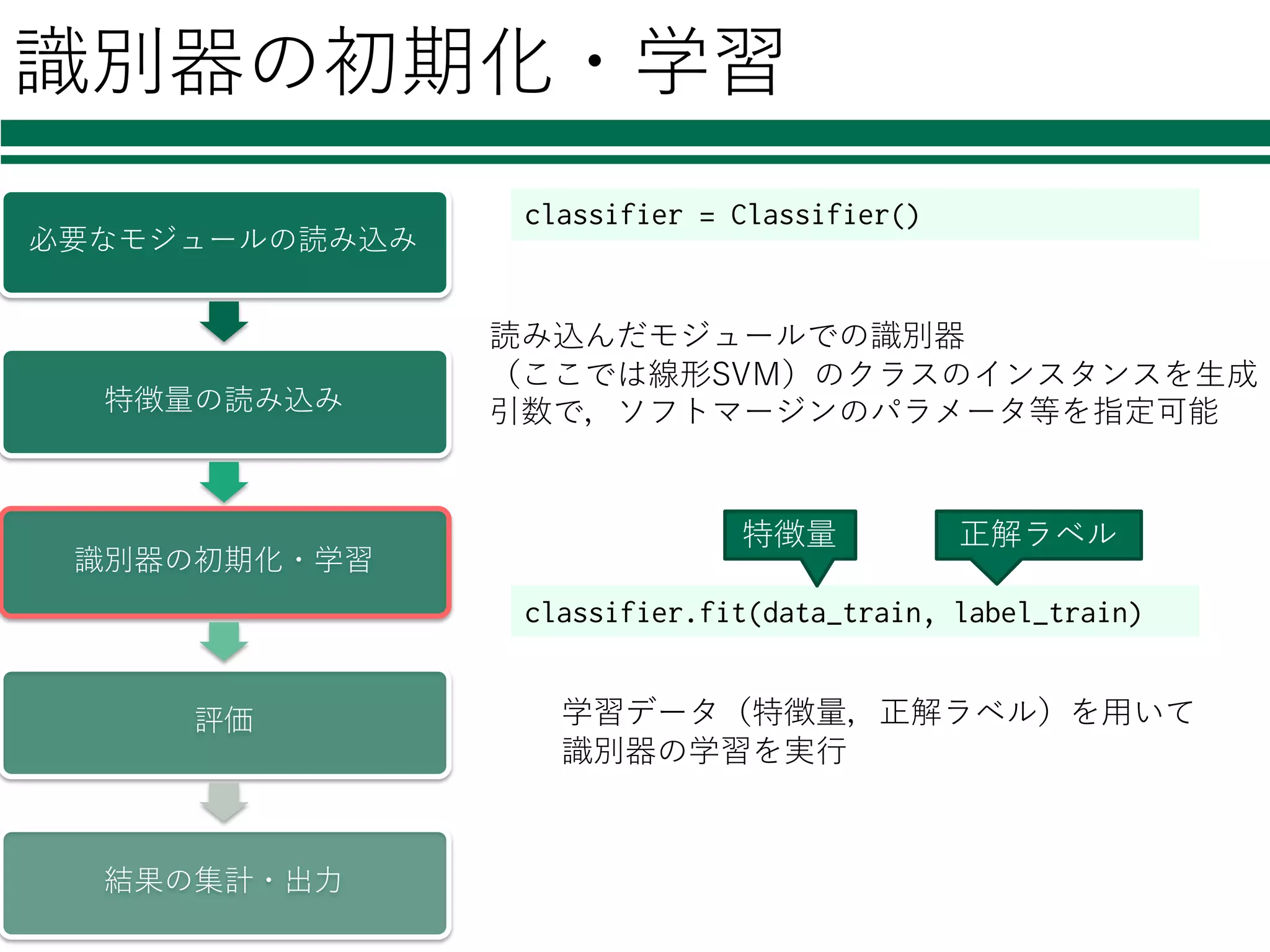
識別器の初期化・学習 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ classifier = Classifier() 読み込んだモジュールでの識別器 (ここでは線形SVM)のクラスのインスタンスを⽣成 引数で,ソフトマージンのパラメータ等を指定可能 classifier.fit(data_train,
label_train) 学習データ(特徴量,正解ラベル)を⽤いて 識別器の学習を実⾏ 特徴量 正解ラベル
25.
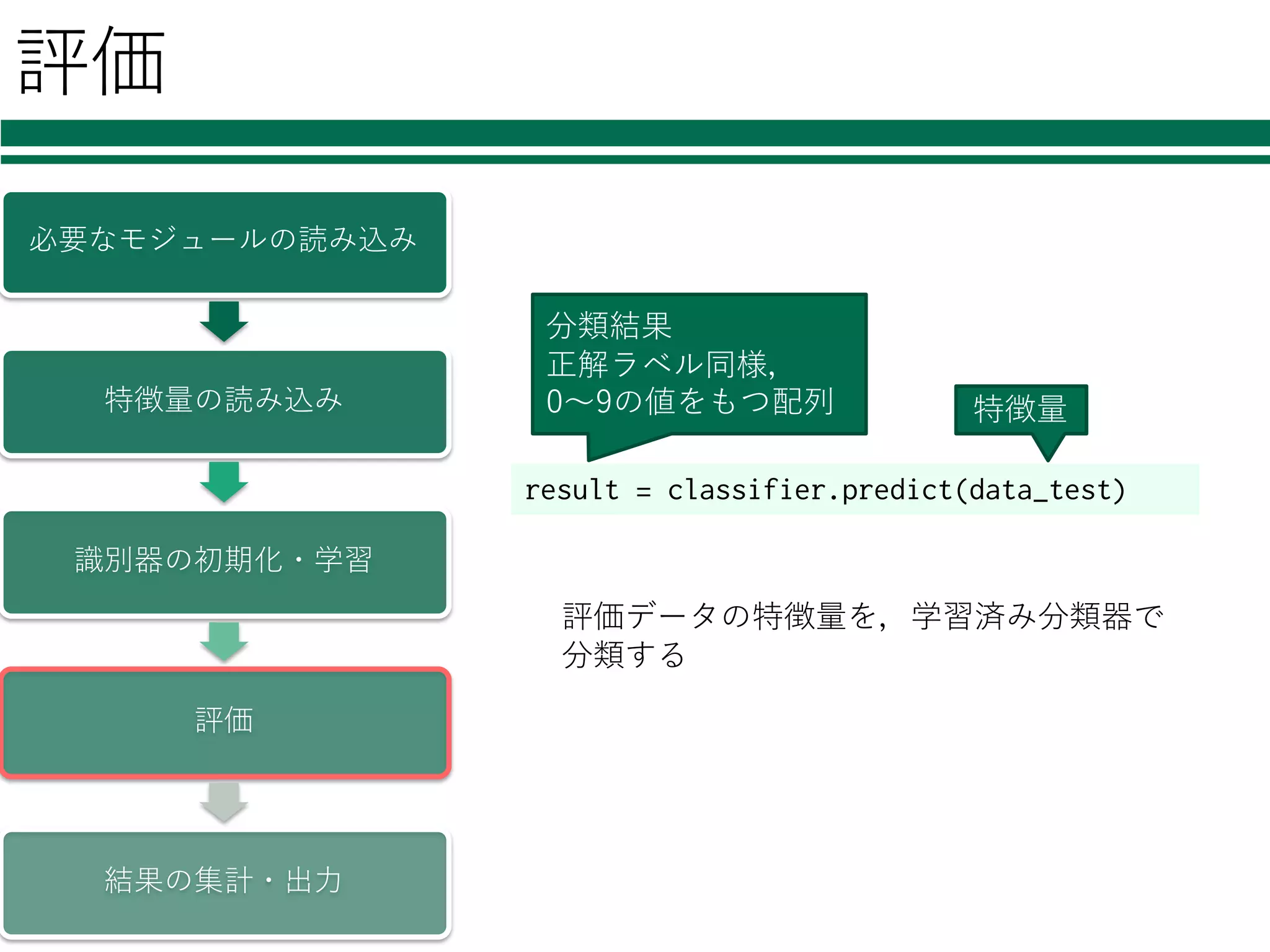
評価 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ result = classifier.predict(data_test) 評価データの特徴量を,学習済み分類器で 分類する 特徴量 分類結果 正解ラベル同様, 0〜9の値をもつ配列
26.
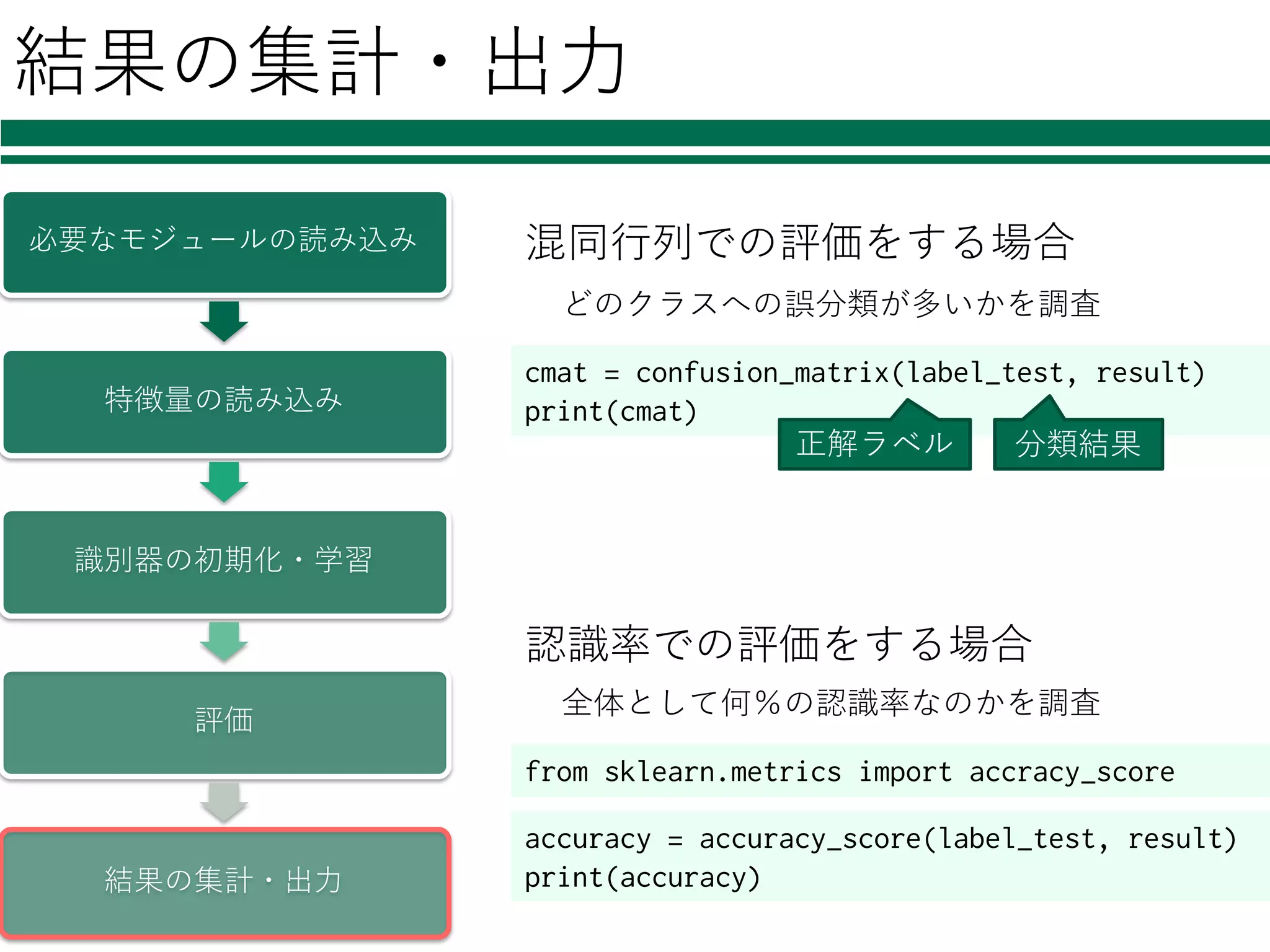
結果の集計・出⼒ 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ accuracy = accuracy_score(label_test,
result) print(accuracy) 全体として何%の認識率なのかを調査 cmat = confusion_matrix(label_test, result) print(cmat) 混同⾏列での評価をする場合 認識率での評価をする場合 正解ラベル 分類結果 どのクラスへの誤分類が多いかを調査 from sklearn.metrics import accracy_score
27.
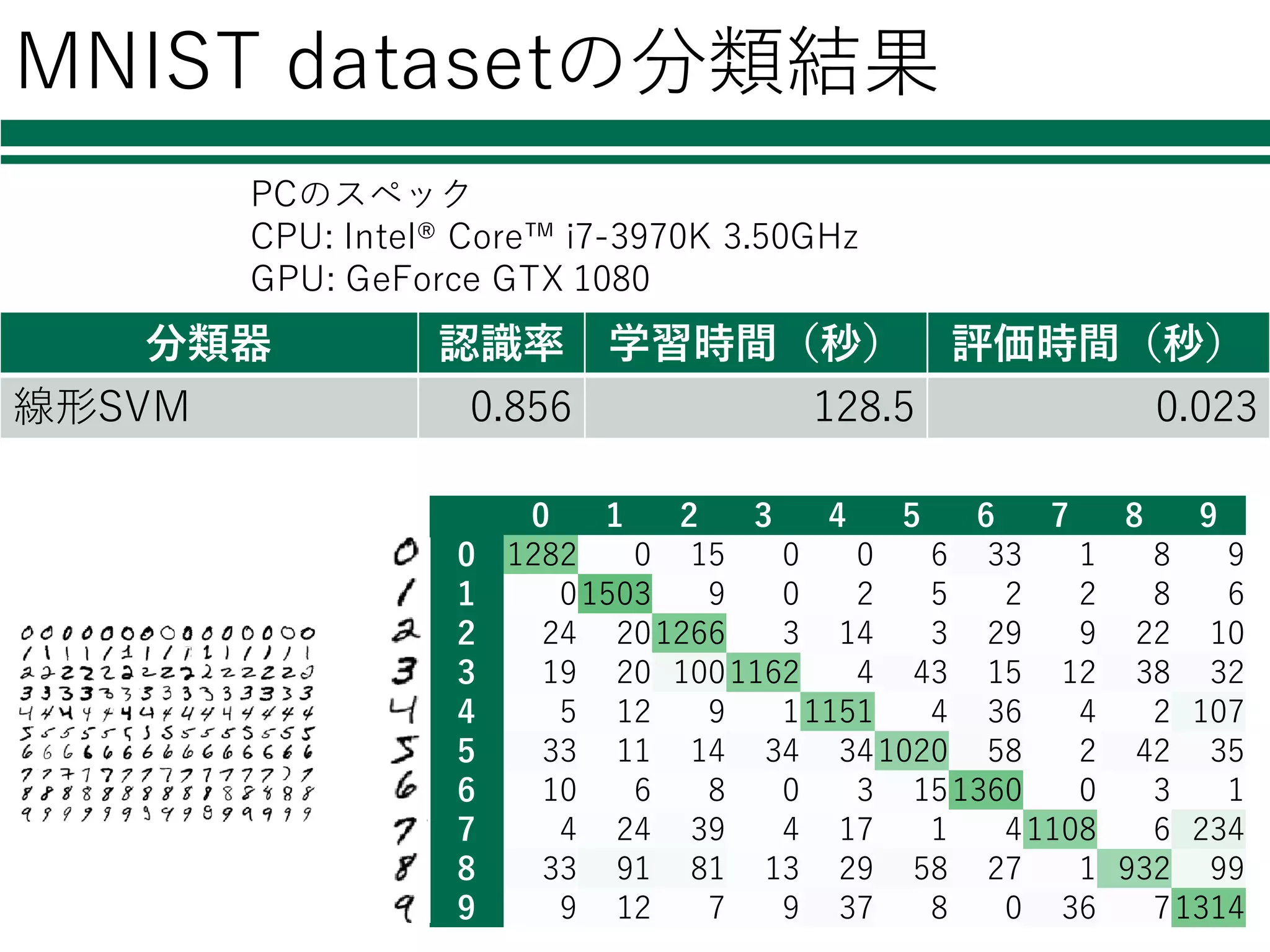
MNIST datasetの分類結果 0 1
2 3 4 5 6 7 8 9 0 1282 0 15 0 0 6 33 1 8 9 1 01503 9 0 2 5 2 2 8 6 2 24 201266 3 14 3 29 9 22 10 3 19 20 1001162 4 43 15 12 38 32 4 5 12 9 11151 4 36 4 2 107 5 33 11 14 34 341020 58 2 42 35 6 10 6 8 0 3 151360 0 3 1 7 4 24 39 4 17 1 41108 6 234 8 33 91 81 13 29 58 27 1 932 99 9 9 12 7 9 37 8 0 36 71314 分類器 認識率 学習時間(秒) 評価時間(秒) 線形SVM 0.856 128.5 0.023 PCのスペック CPU: Intel® Core™ i7-3970K 3.50GHz GPU: GeForce GTX 1080
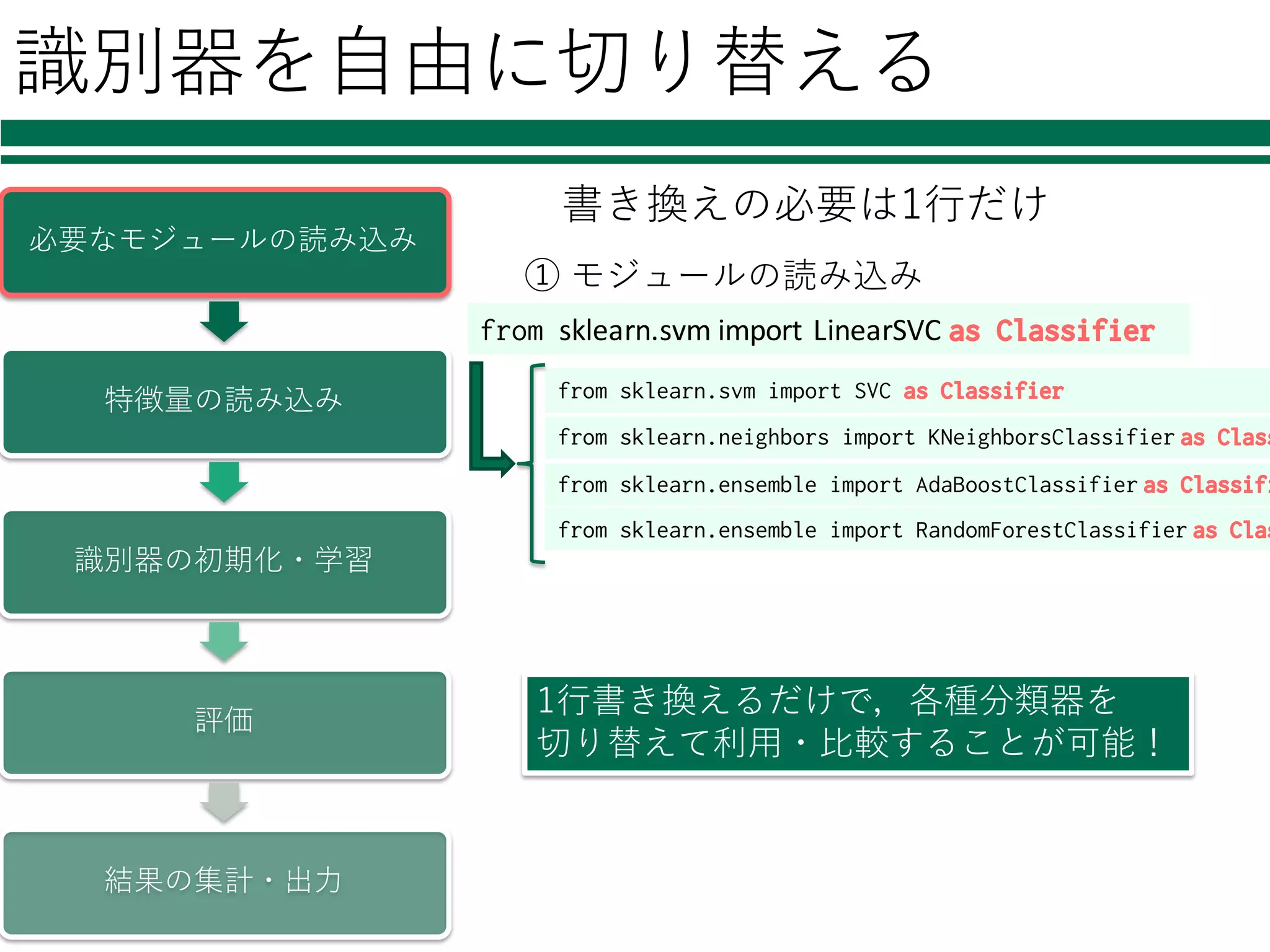
28.
識別器を⾃由に切り替える 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ 書き換えの必要は1⾏だけ from sklearn.svm import LinearSVC
as Classifier ① モジュールの読み込み from sklearn.svm import SVC as Classifier from sklearn.neighbors import KNeighborsClassifier as Class from sklearn.ensemble import AdaBoostClassifier as Classifi from sklearn.ensemble import RandomForestClassifier as Clas 1⾏書き換えるだけで,各種分類器を 切り替えて利⽤・⽐較することが可能!
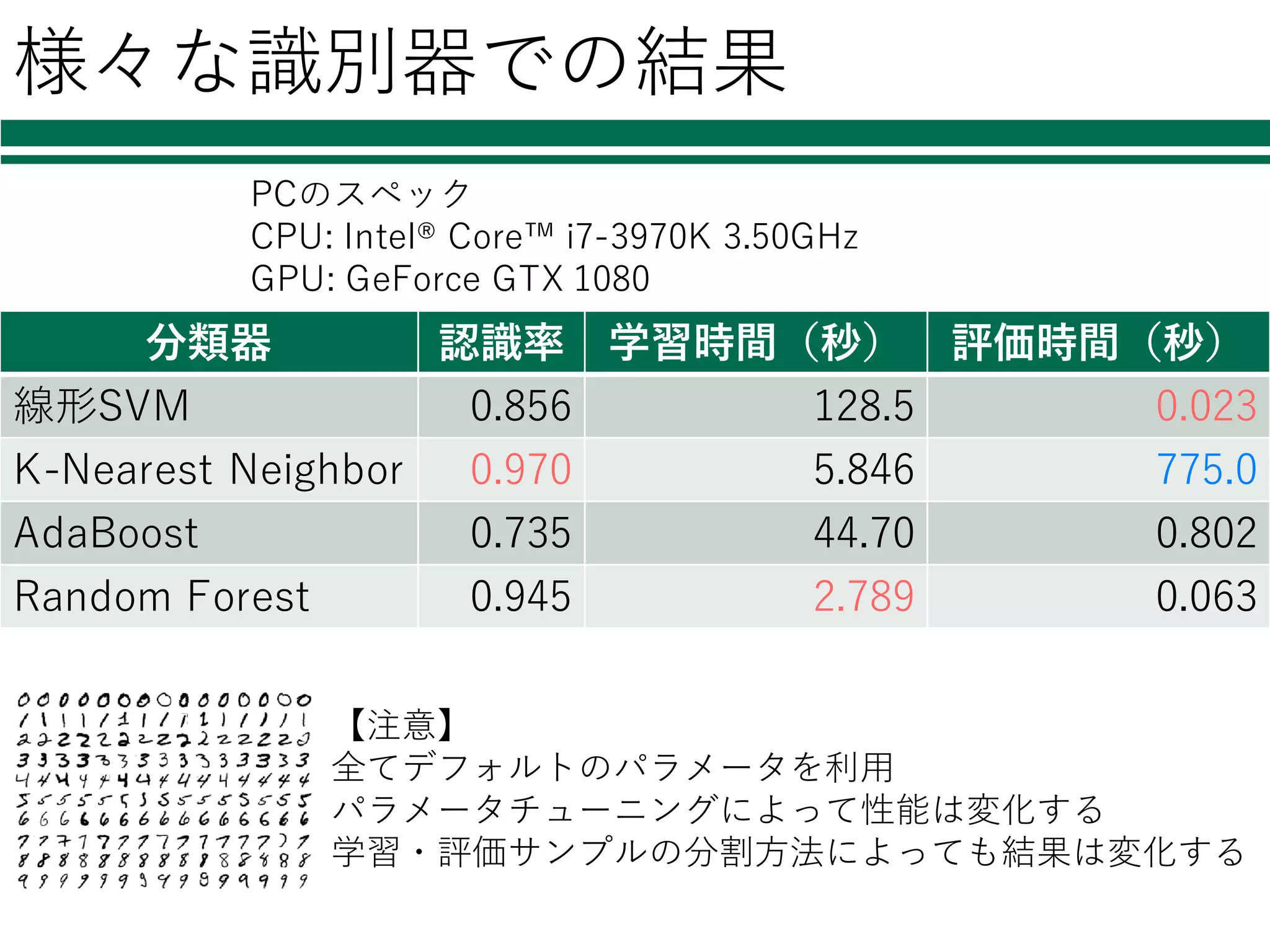
29.
様々な識別器での結果 分類器 認識率 学習時間(秒)
評価時間(秒) 線形SVM 0.856 128.5 0.023 K-Nearest Neighbor 0.970 5.846 775.0 AdaBoost 0.735 44.70 0.802 Random Forest 0.945 2.789 0.063 【注意】 全てデフォルトのパラメータを利⽤ パラメータチューニングによって性能は変化する 学習・評価サンプルの分割⽅法によっても結果は変化する PCのスペック CPU: Intel® Core™ i7-3970K 3.50GHz GPU: GeForce GTX 1080
30.
mnist = fetch_mldata("MNIST
original", data_home=".") 特徴量の読み込み 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ 今回はMINST databaseを使ったが… load_svmlight_file(filename) 1. OpenCV等を使って予め特徴抽出し,保存 別の取り組みたい問題のために ⾃前で抽出した特徴量を使う場合 2. 保存した特徴量を読み込んでクラス分類 データの保存には svmlight 形式が便利 読み込み⽤の関数が存在 特徴量とラベルをまとめて読み込める
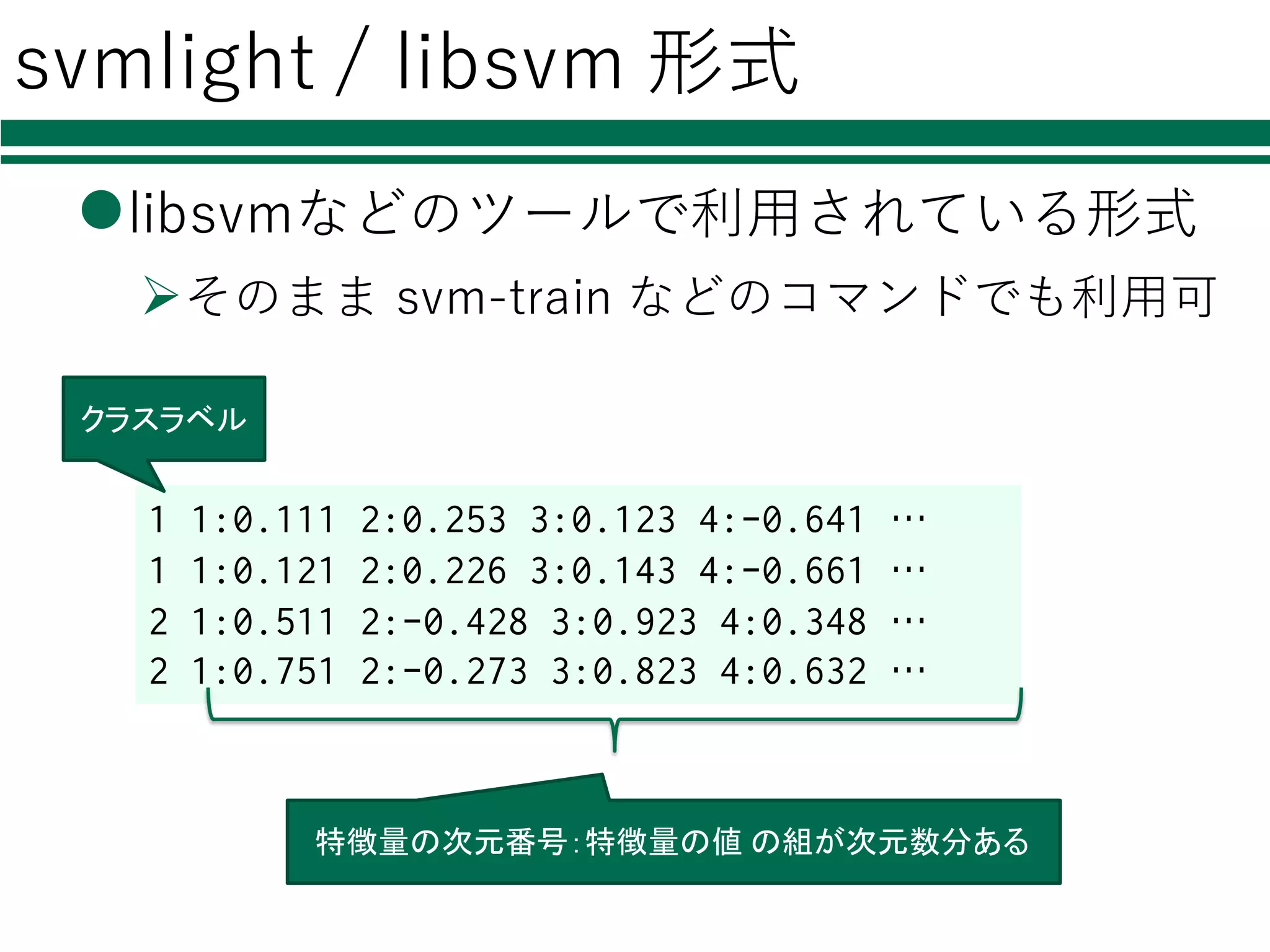
31.
svmlight / libsvm
形式 llibsvmなどのツールで利⽤されている形式 Øそのまま svm-train などのコマンドでも利⽤可 1 1:0.111 2:0.253 3:0.123 4:-0.641 … 1 1:0.121 2:0.226 3:0.143 4:-0.661 … 2 1:0.511 2:-0.428 3:0.923 4:0.348 … 2 1:0.751 2:-0.273 3:0.823 4:0.632 … クラスラベル 特徴量の次元番号:特徴量の値 の組が次元数分ある
32.
mnist = fetch_mldata("MNIST
original", data_home=".") 特徴量の読み込み 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ 今回はMINST databaseを使ったが… load_svmlight_file(filename) 1. OpenCV等を使って予め特徴抽出し,保存 別の取り組みたい問題のために ⾃前で抽出した特徴量を使う場合 2. 保存した特徴量を読み込んでクラス分類 データの保存には svmlight 形式が便利 読み込み⽤の関数が存在 特徴量とラベルをまとめて読み込める
33.
DEEP LEARNINGに挑戦
34.
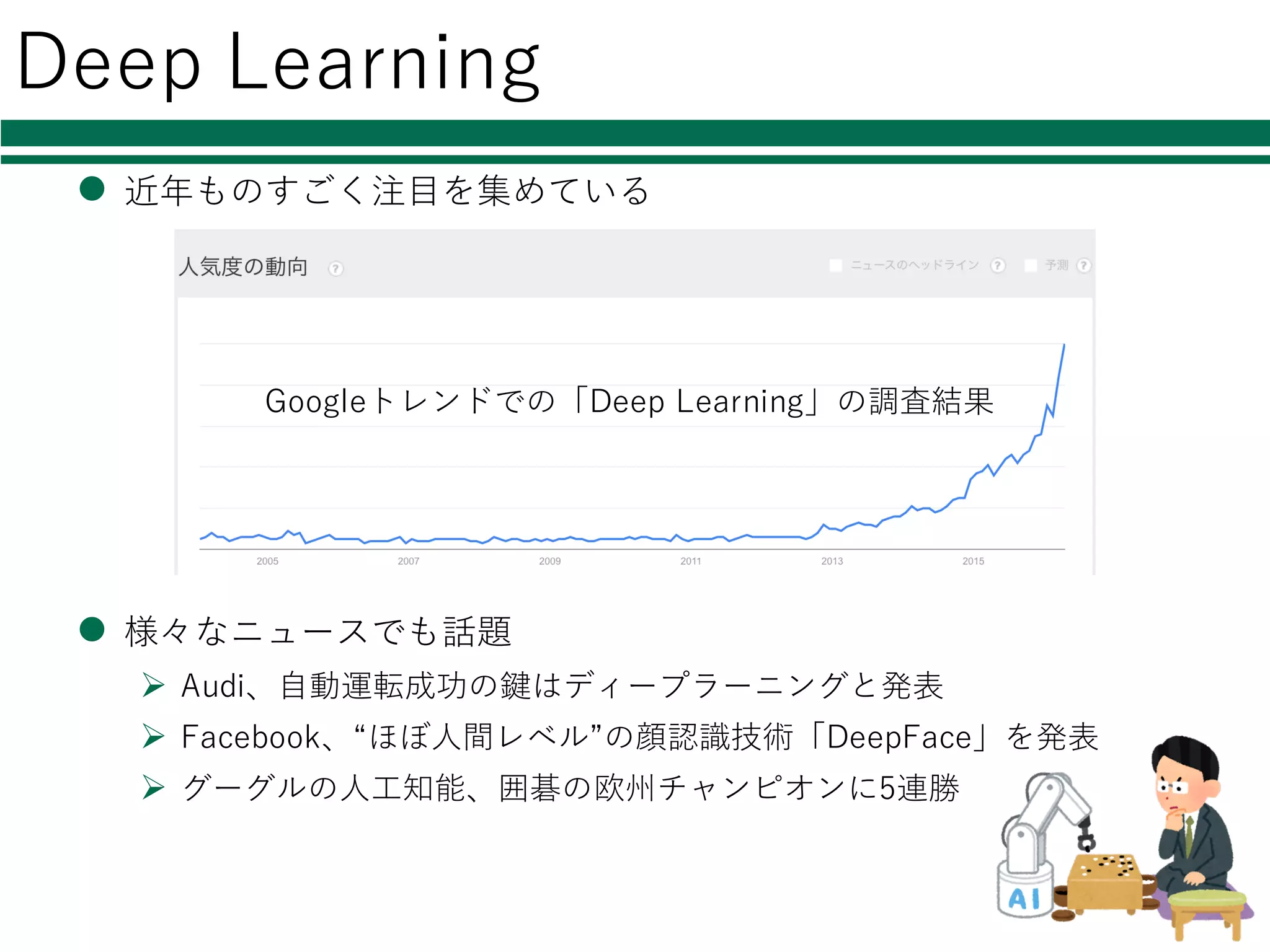
Deep Learning l 近年ものすごく注⽬を集めている l
様々なニュースでも話題 Ø Audi、⾃動運転成功の鍵はディープラーニングと発表 Ø Facebook、“ほぼ⼈間レベル”の顔認識技術「DeepFace」を発表 Ø グーグルの⼈⼯知能、囲碁の欧州チャンピオンに5連勝 Googleトレンドでの「Deep Learning」の調査結果
35.
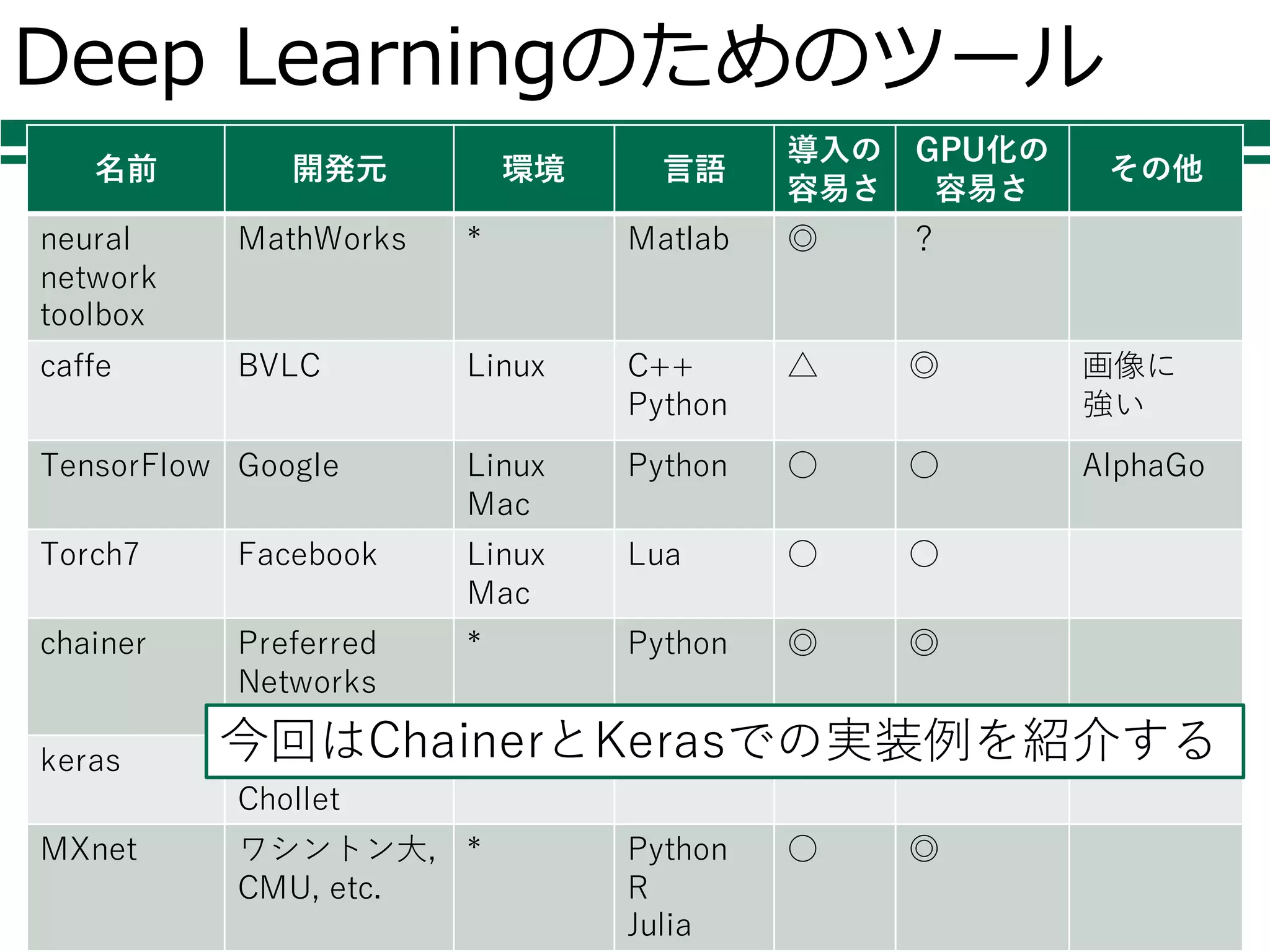
Deep Learningのためのツール 名前 開発元
環境 ⾔語 導⼊の 容易さ GPU化の 容易さ その他 neural network toolbox MathWorks * Matlab ◎ ? caffe BVLC Linux C++ Python △ ◎ 画像に 強い TensorFlow Google Linux Mac Python ○ ○ AlphaGo Torch7 Facebook Linux Mac Lua ○ ○ chainer Preferred Networks * Python ◎ ◎ keras Francois Chollet * Python ◎ ◎ MXnet ワシントン⼤, CMU, etc. * Python R Julia ○ ◎ 今回はChainerとKerasでの実装例を紹介する
36.
Deep Learningライブラリの基本 l誤差逆伝播法による学習 Ø各層で関数を微分して重み更新 ²関数の微分機能が必要 l関数を表現するオブジェクト Ø演算結果ではなく,式の構造を保持 Ø微分機能:微分した関数のオブジェクトを返す lその他の便利機能 ØGPU上で計算する機能 Øネットワーク(関数の集まり)の構築機能 Ø学習データを与えると⾃動的に学習してくれる機能
37.
今回紹介する例題と実装 lクラス分類器として Ø(Deep) Neural Network Ø3層のニューラルネットワークを例に説明 l特徴抽出+クラス分類器として ØConvolutional
Neural Network ØConvolution 2層,全結合3層を例に l学習済みモデルの読み込みと実⾏・Fine tuning
38.
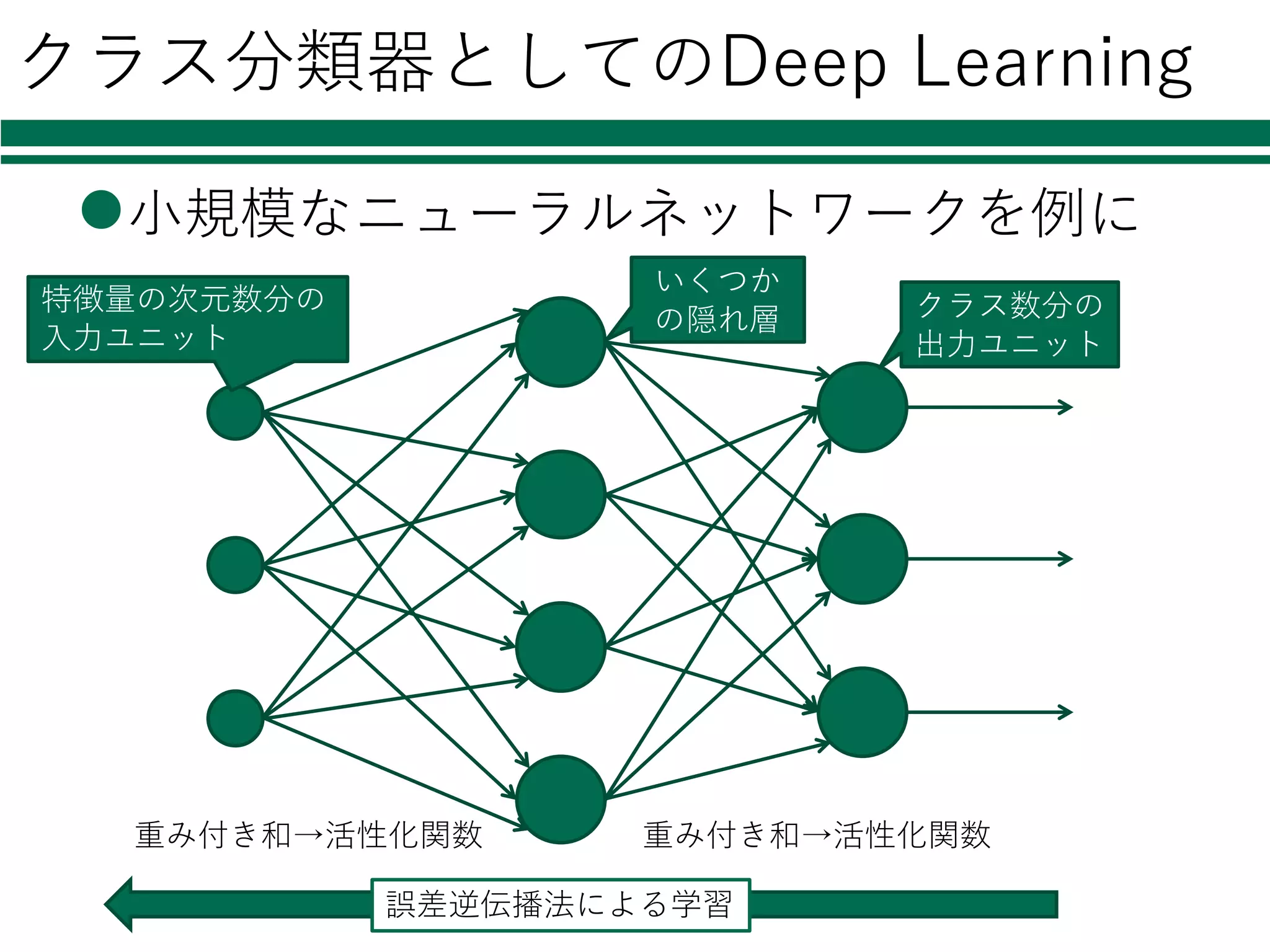
クラス分類器としてのDeep Learning l⼩規模なニューラルネットワークを例に 重み付き和→活性化関数 重み付き和→活性化関数 いくつか の隠れ層
クラス数分の 出⼒ユニット 特徴量の次元数分の ⼊⼒ユニット 誤差逆伝播法による学習
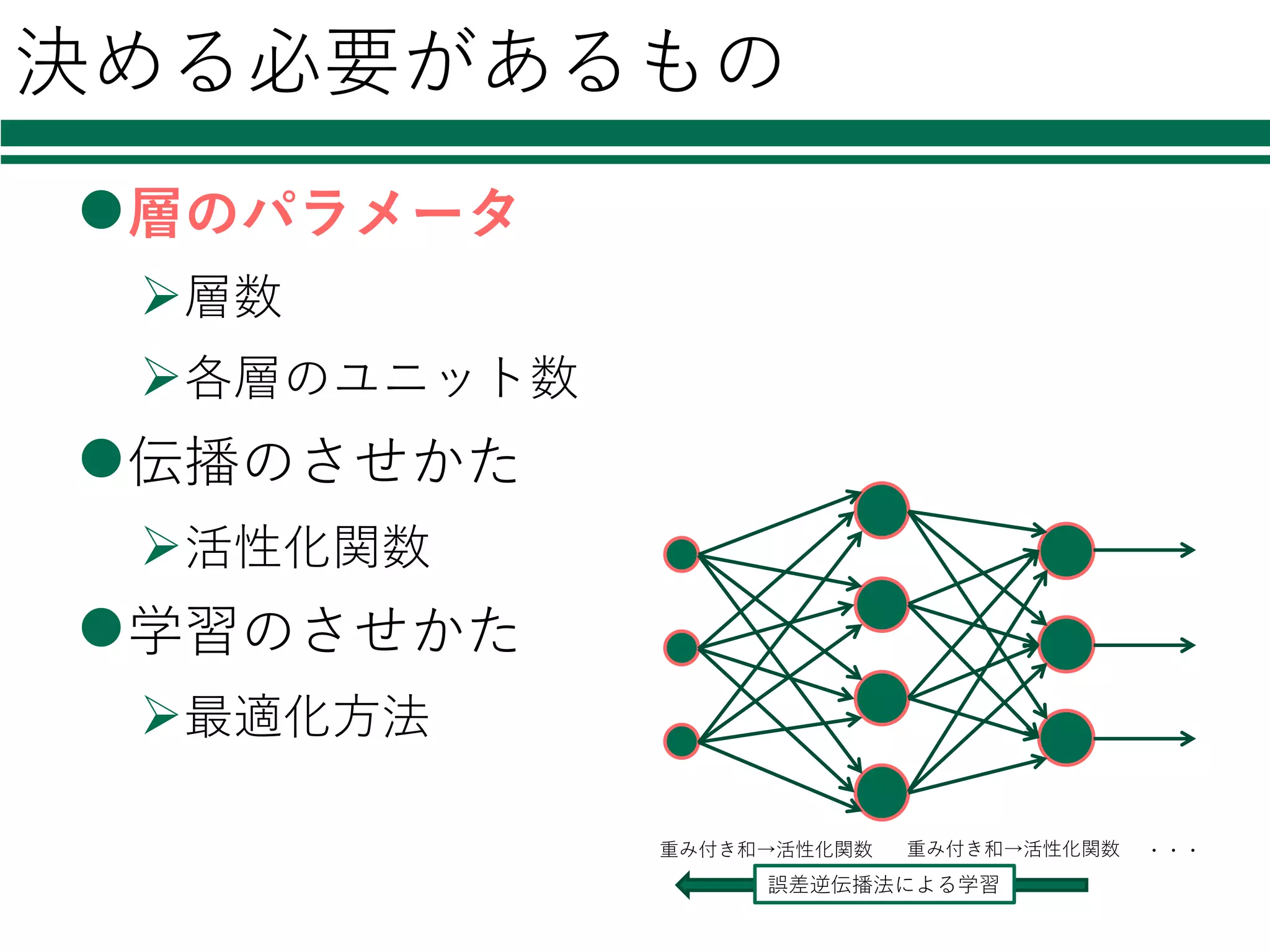
39.
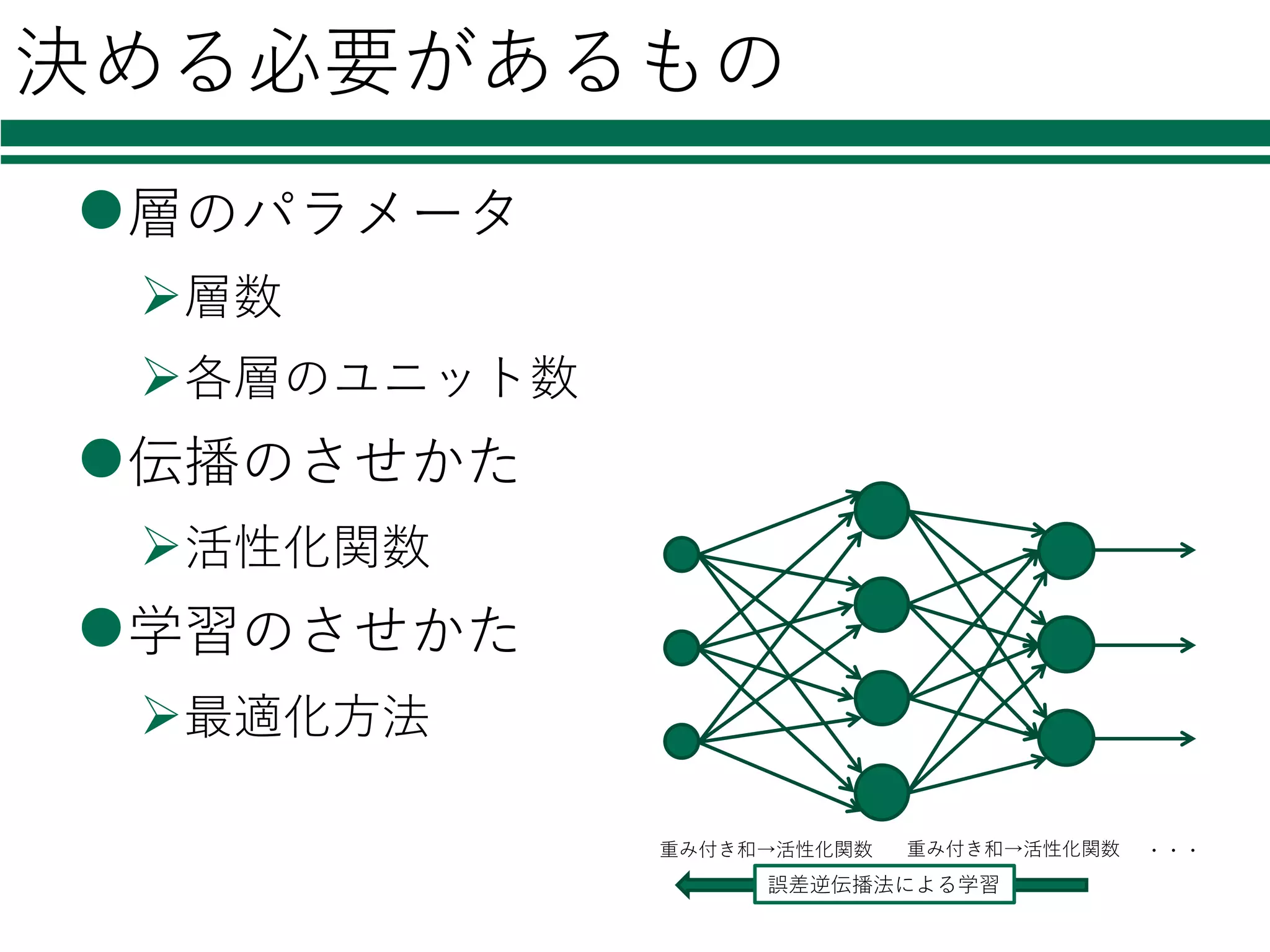
決める必要があるもの l層のパラメータ Ø層数 Ø各層のユニット数 l伝播のさせかた Ø活性化関数 l学習のさせかた Ø最適化⽅法 重み付き和→活性化関数 重み付き和→活性化関数 ・・・ 誤差逆伝播法による学習
40.
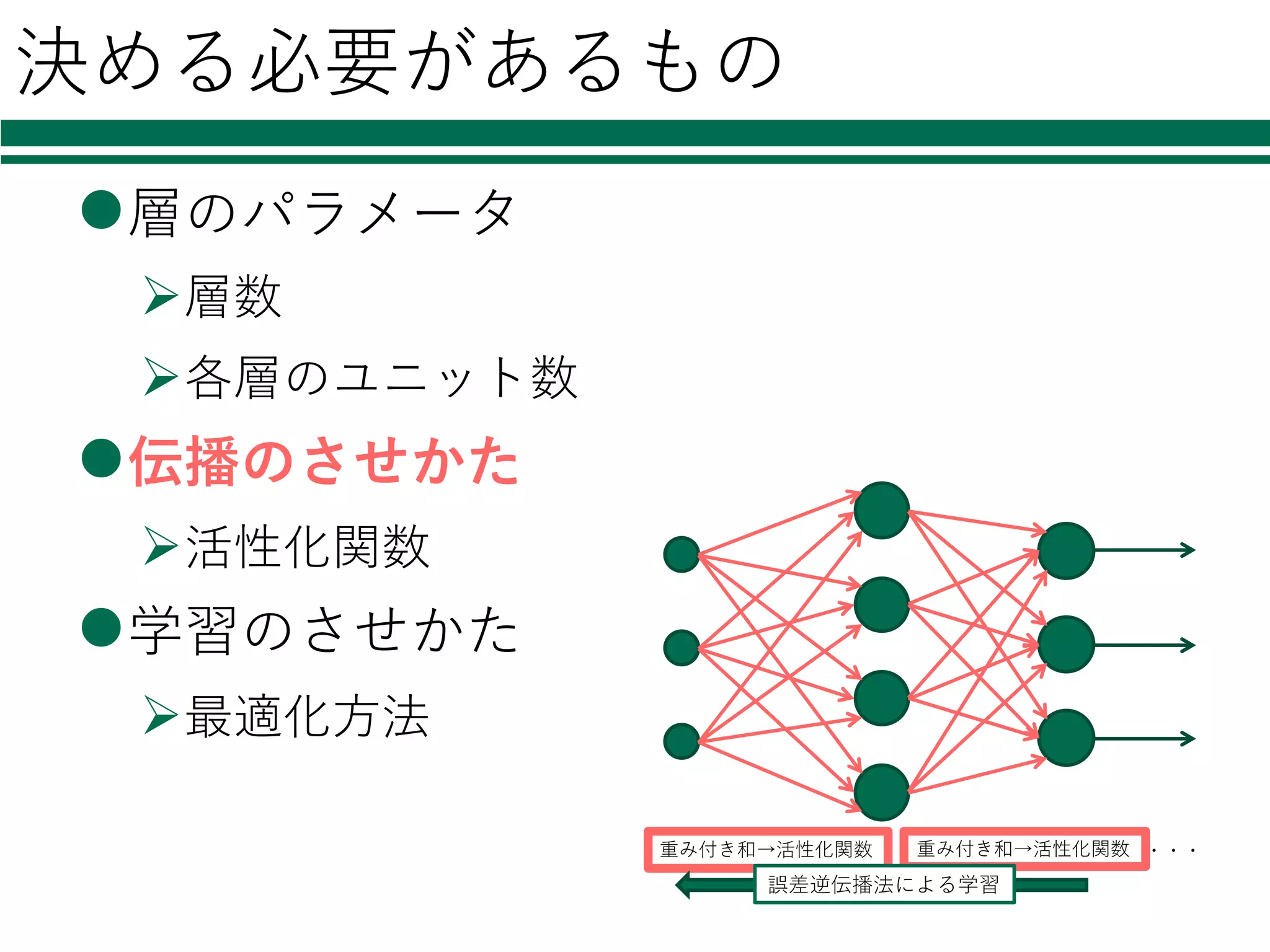
決める必要があるもの l層のパラメータ Ø層数 Ø各層のユニット数 l伝播のさせかた Ø活性化関数 l学習のさせかた Ø最適化⽅法 重み付き和→活性化関数 重み付き和→活性化関数 ・・・ 誤差逆伝播法による学習
41.
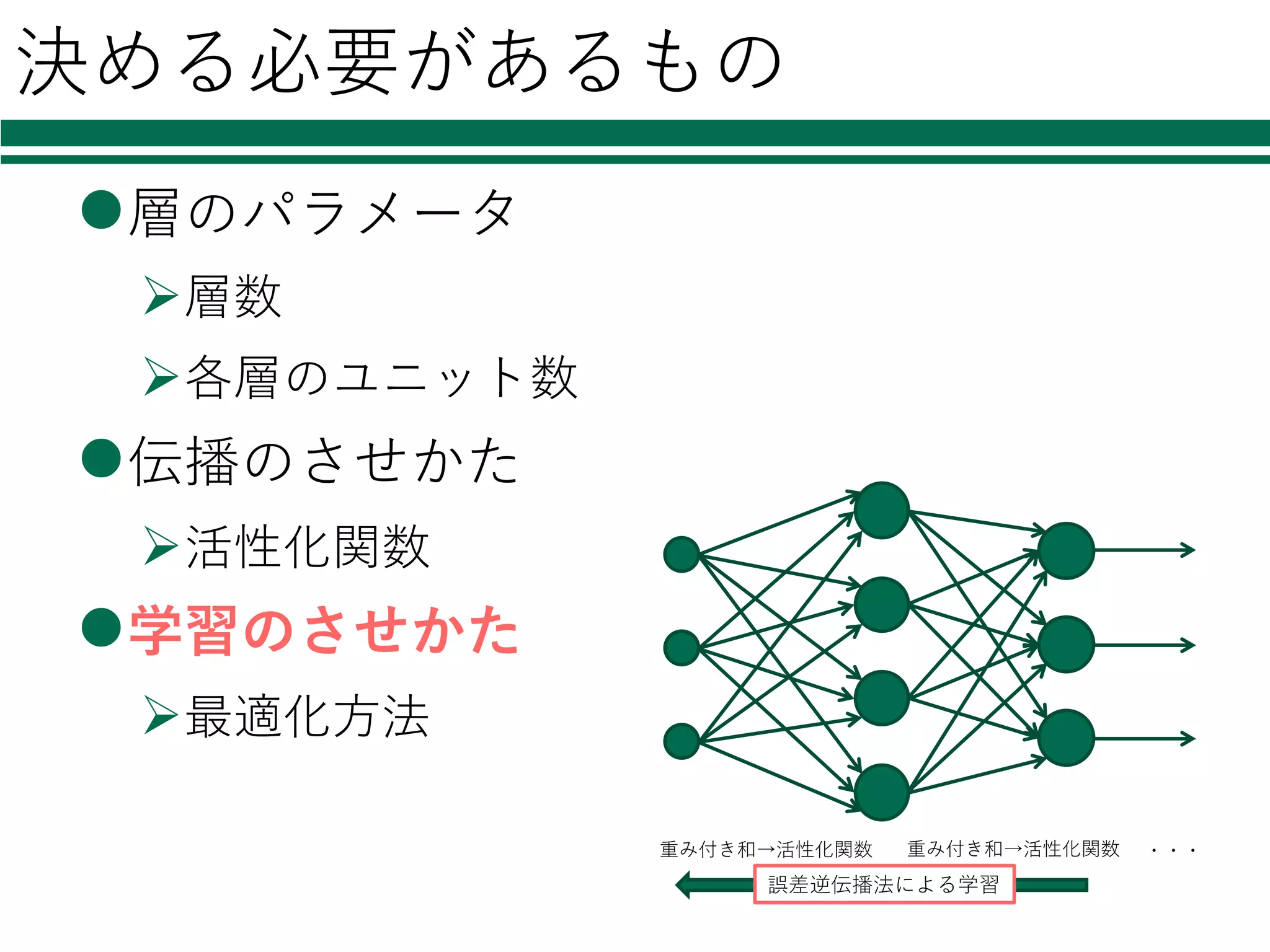
決める必要があるもの l層のパラメータ Ø層数 Ø各層のユニット数 l伝播のさせかた Ø活性化関数 l学習のさせかた Ø最適化⽅法 重み付き和→活性化関数 重み付き和→活性化関数 ・・・ 誤差逆伝播法による学習
42.
決める必要があるもの l層のパラメータ Ø層数 Ø各層のユニット数 l伝播のさせかた Ø活性化関数 l学習のさせかた Ø最適化⽅法 重み付き和→活性化関数 重み付き和→活性化関数 ・・・ 誤差逆伝播法による学習
43.
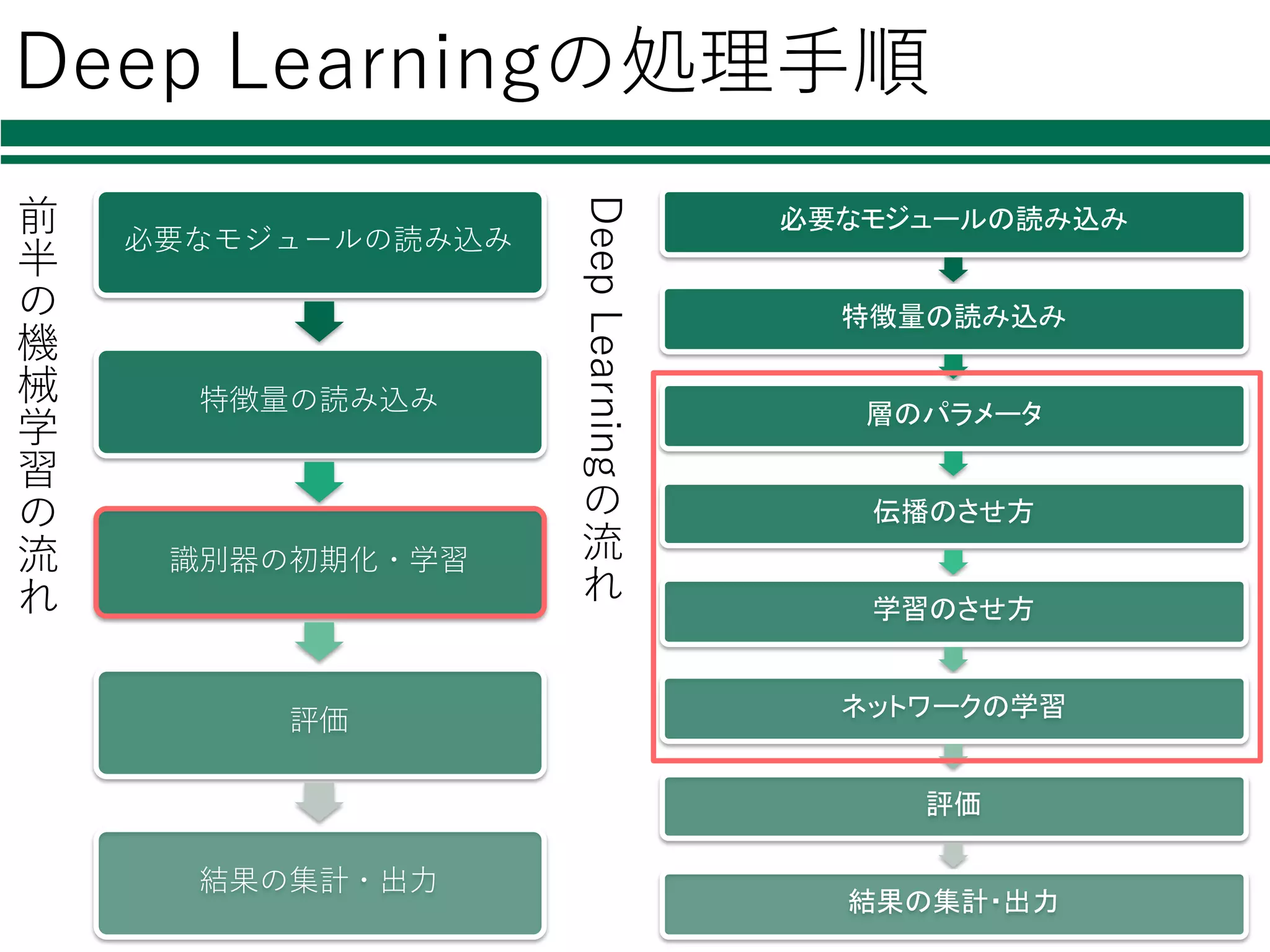
Deep Learningの処理⼿順 必要なモジュールの読み込み 特徴量の読み込み 識別器の初期化・学習 評価 結果の集計・出⼒ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 前 半 の 機 械 学 習 の 流 れ DeepLearning の 流 れ
44.
CHAINERでの実装
45.
必要なモジュールの読み込み 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 from chainer import
Chain from chainer import Variable from chainer import optimizers import chainer.functions as F import chainer.links as L from sklearn.metrics import confusion_matrix import numpy as np chainerで必要なものをインポート その他,機械学習の評価⽤等のために 必要なインポート
46.
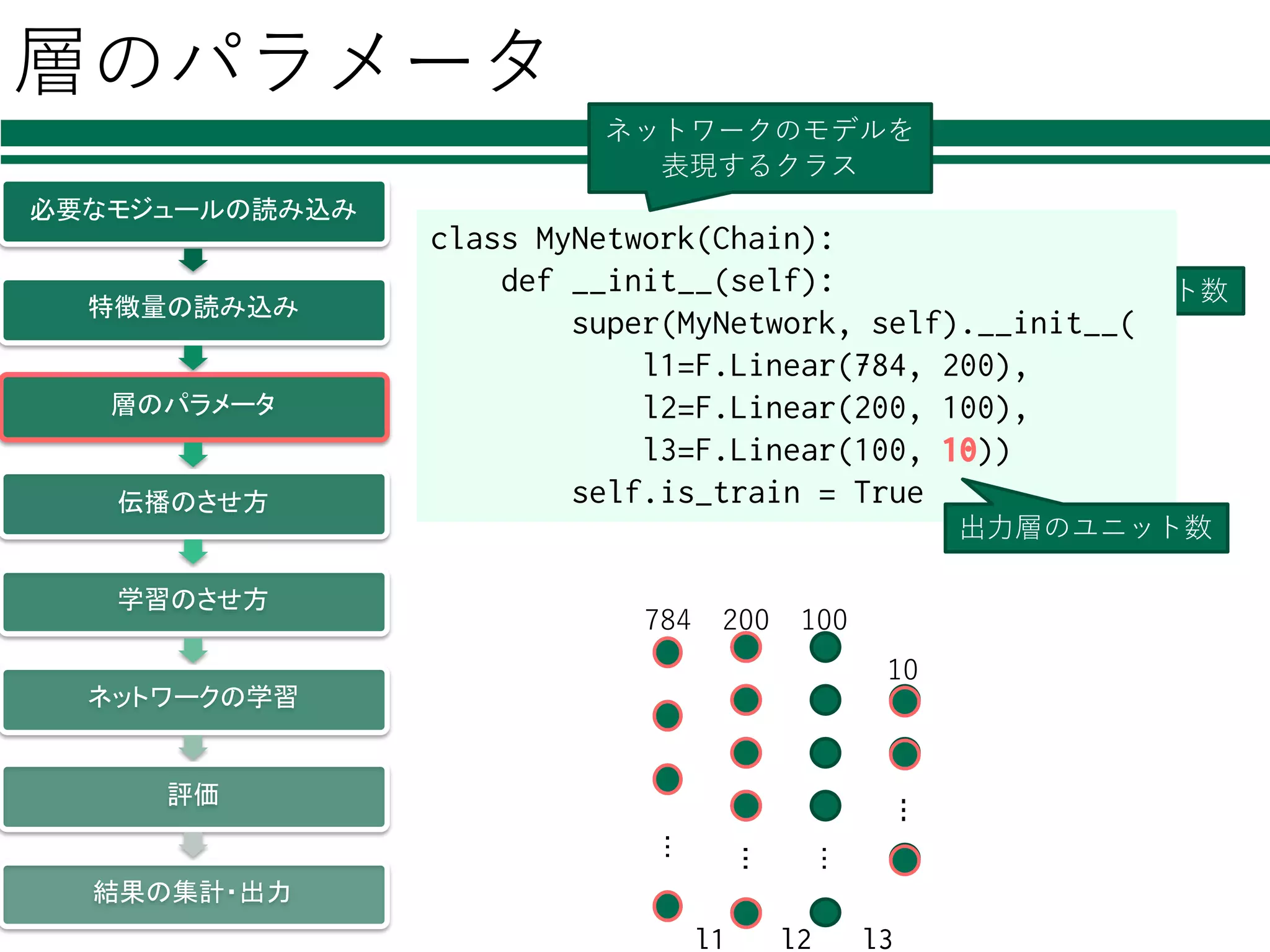
層のパラメータ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 class MyNetwork(Chain): def __init__(self): super(MyNetwork,
self).__init__( l1=F.Linear(784, 200), l2=F.Linear(200, 100), l3=F.Linear(100, 10)) self.is_train = True ・・・ ・・・ ・・・ ・・・ 784 200 100 10 ・・・ ・・・ ・・・ class MyNetwork(Chain): def __init__(self): super(MyNetwork, self).__init__( l1=F.Linear(784, 200), l2=F.Linear(200, 100), l3=F.Linear(100, 10)) self.is_train = True ⼊⼒層のユニット数 中間層のユニット数 class MyNetwork(Chain): def __init__(self): super(MyNetwork, self).__init__( l1=F.Linear(784, 200), l2=F.Linear(200, 100), l3=F.Linear(100, 10)) self.is_train = True 出⼒層のユニット数 ネットワークのモデルを 表現するクラス l1 l2 l3
47.
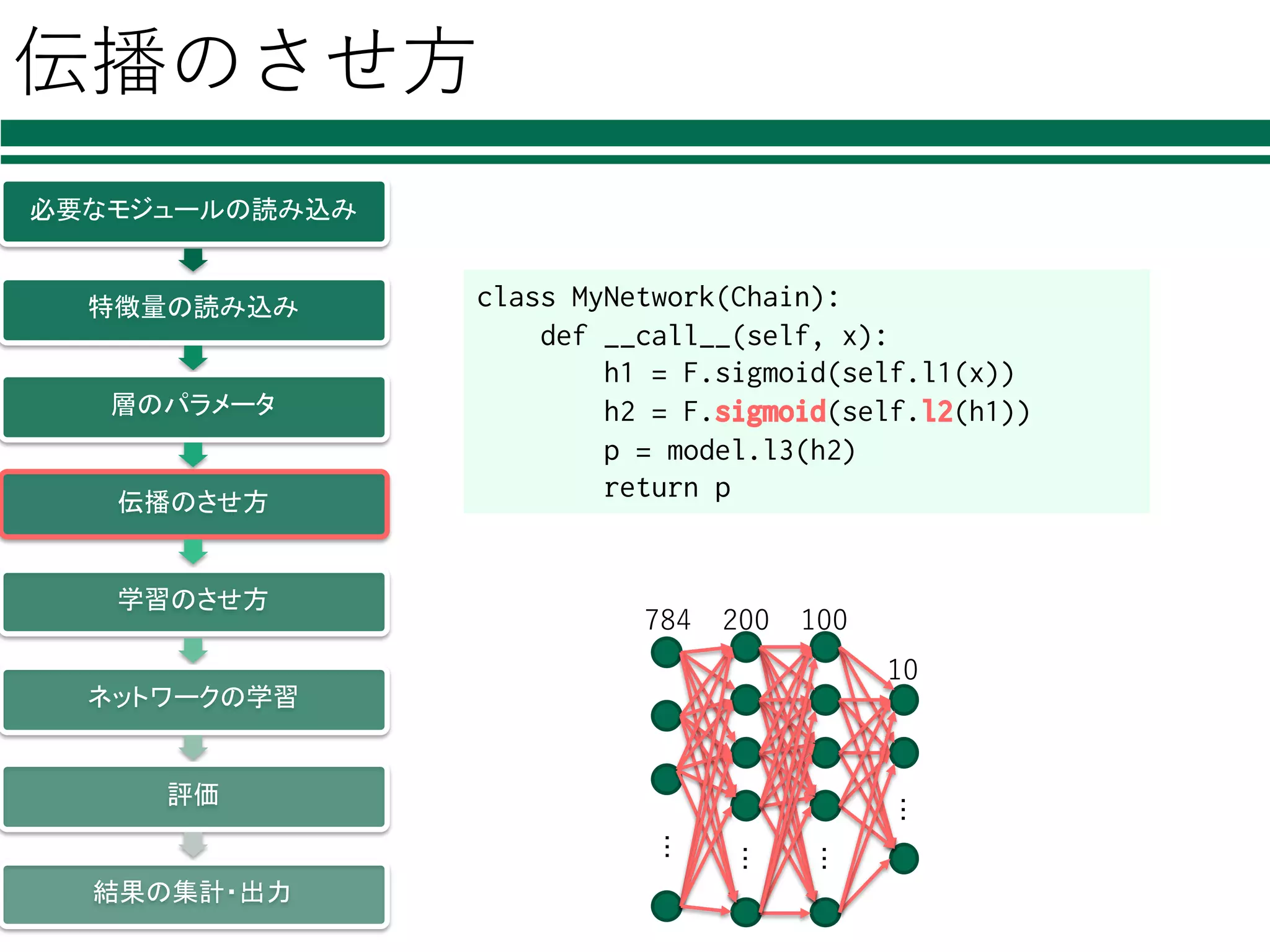
伝播のさせ⽅ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ・・・ ・・・ ・・・ ・・・ 784 200 100 10 class
MyNetwork(Chain): def __call__(self, x): h1 = F.sigmoid(self.l1(x)) h2 = F.sigmoid(self.l2(h1)) p = model.l3(h2) return p class MyNetwork(Chain): def __call__(self, x): h1 = F.sigmoid(self.l1(x)) h2 = F.sigmoid(self.l2(h1)) p = model.l3(h2) return p
48.
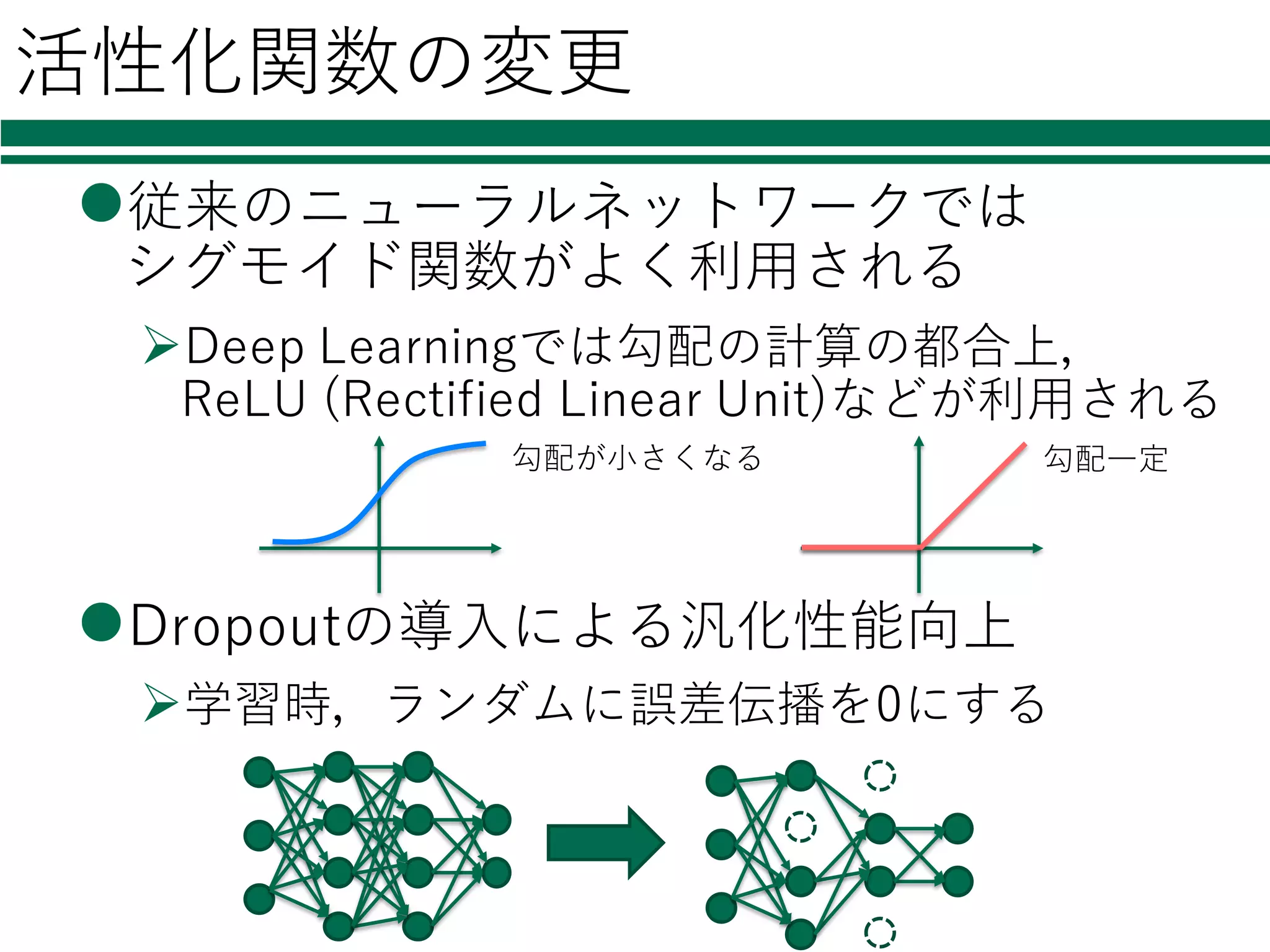
活性化関数の変更 l従来のニューラルネットワークでは シグモイド関数がよく利⽤される ØDeep Learningでは勾配の計算の都合上, ReLU (Rectified
Linear Unit)などが利⽤される lDropoutの導⼊による汎化性能向上 Ø学習時,ランダムに誤差伝播を0にする 勾配が⼩さくなる 勾配⼀定
49.
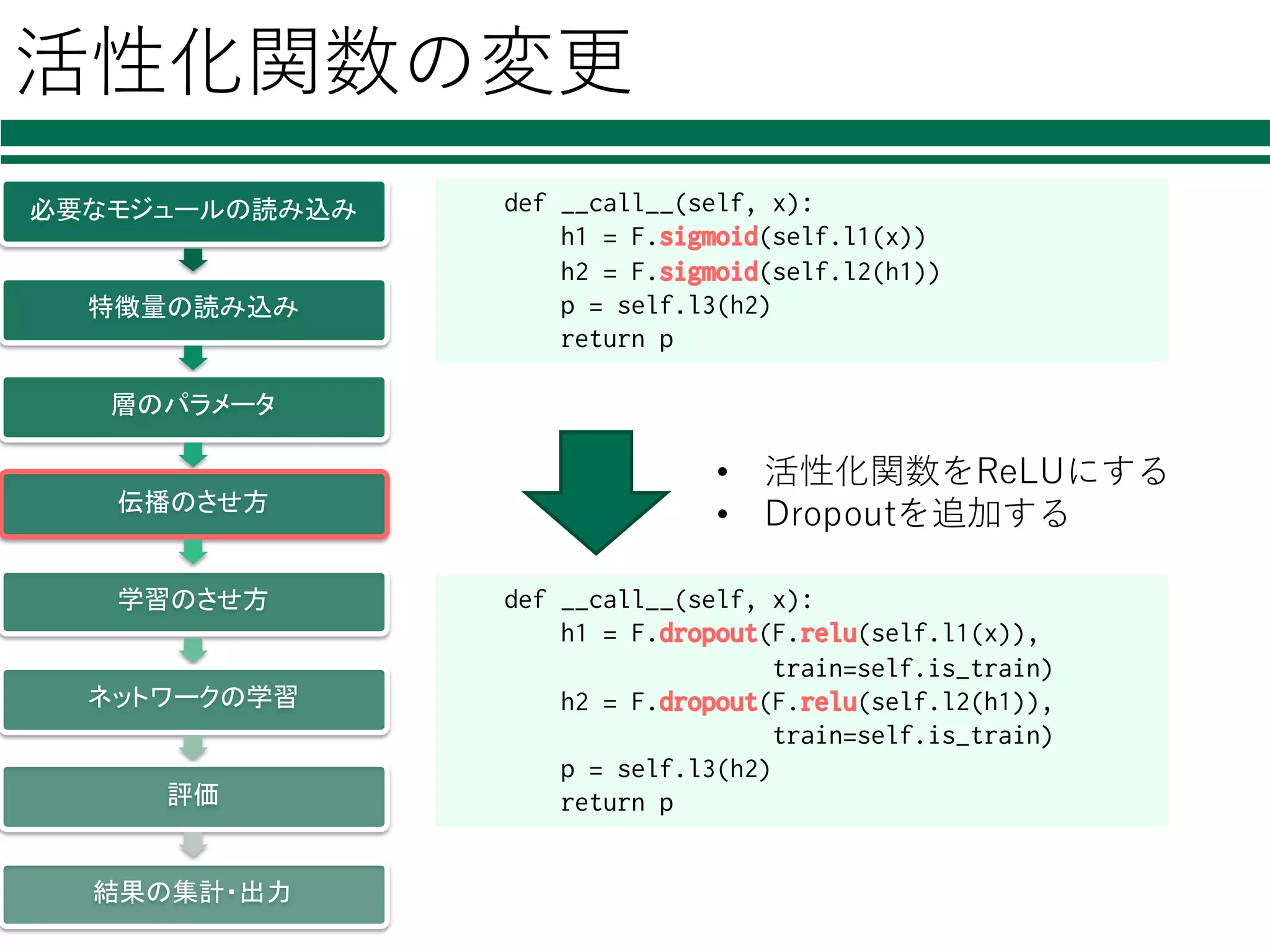
活性化関数の変更 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 def __call__(self, x): h1
= F.sigmoid(self.l1(x)) h2 = F.sigmoid(self.l2(h1)) p = self.l3(h2) return p def __call__(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) p = self.l3(h2) return p def __call__(self, x): h1 = F.dropout(F.relu(self.l1(x)), train=self.is_train) h2 = F.dropout(F.relu(self.l2(h1)), train=self.is_train) p = self.l3(h2) return p • 活性化関数をReLUにする • Dropoutを追加する
50.
学習のさせ⽅ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ネットワークのインスタンスの⽣成 分類器としての評価を⾏うクラスを利⽤ network = MyNetwork() model
= L.Classifier(network) model.compute_accuracy = True 誤差関数を指定可能
51.
学習のさせ⽅ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 optimizer = optimizers.Adam() optimizer.setup(model) SGD
( Stochastic Gradient Descent) AdaGrad RMSprop Adam (ADAptive Moment estimation) modelを登録する ⾊々なパラメータ更新⽅法が利⽤可 学習率を ⾃動的に 調整する 改良 基本的には確率的勾配法が利⽤される 確率的勾配法のバリエーション
52.
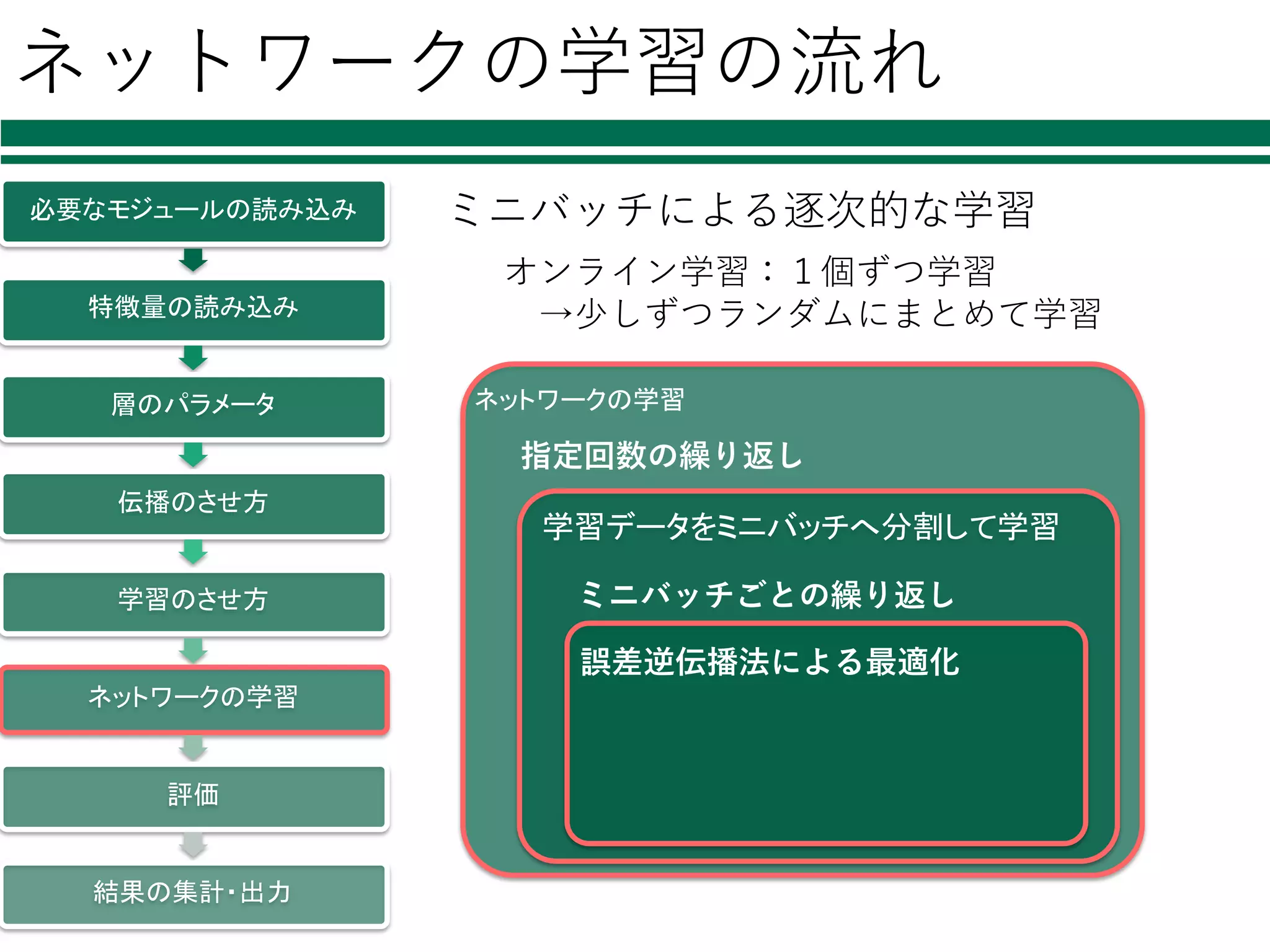
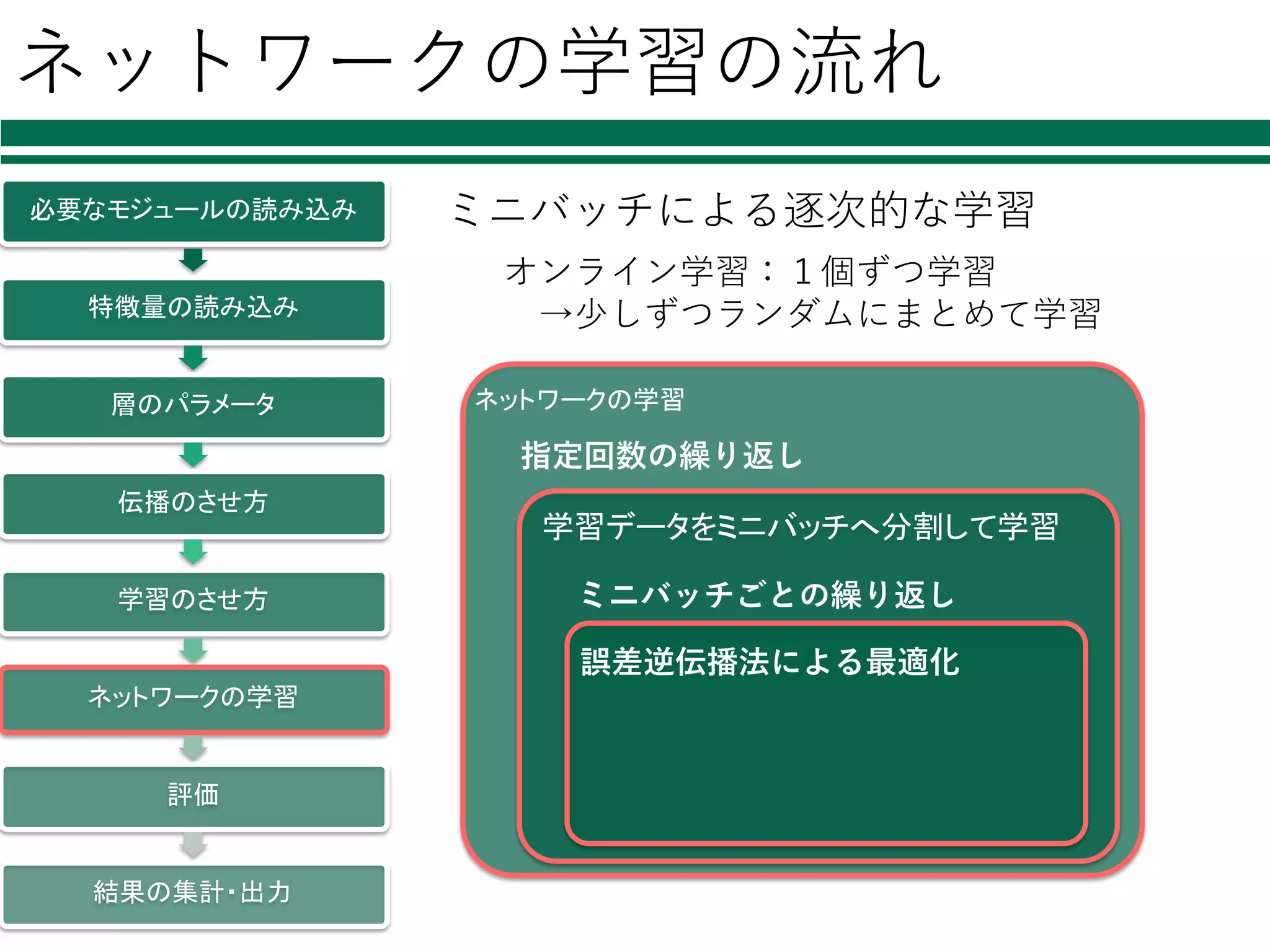
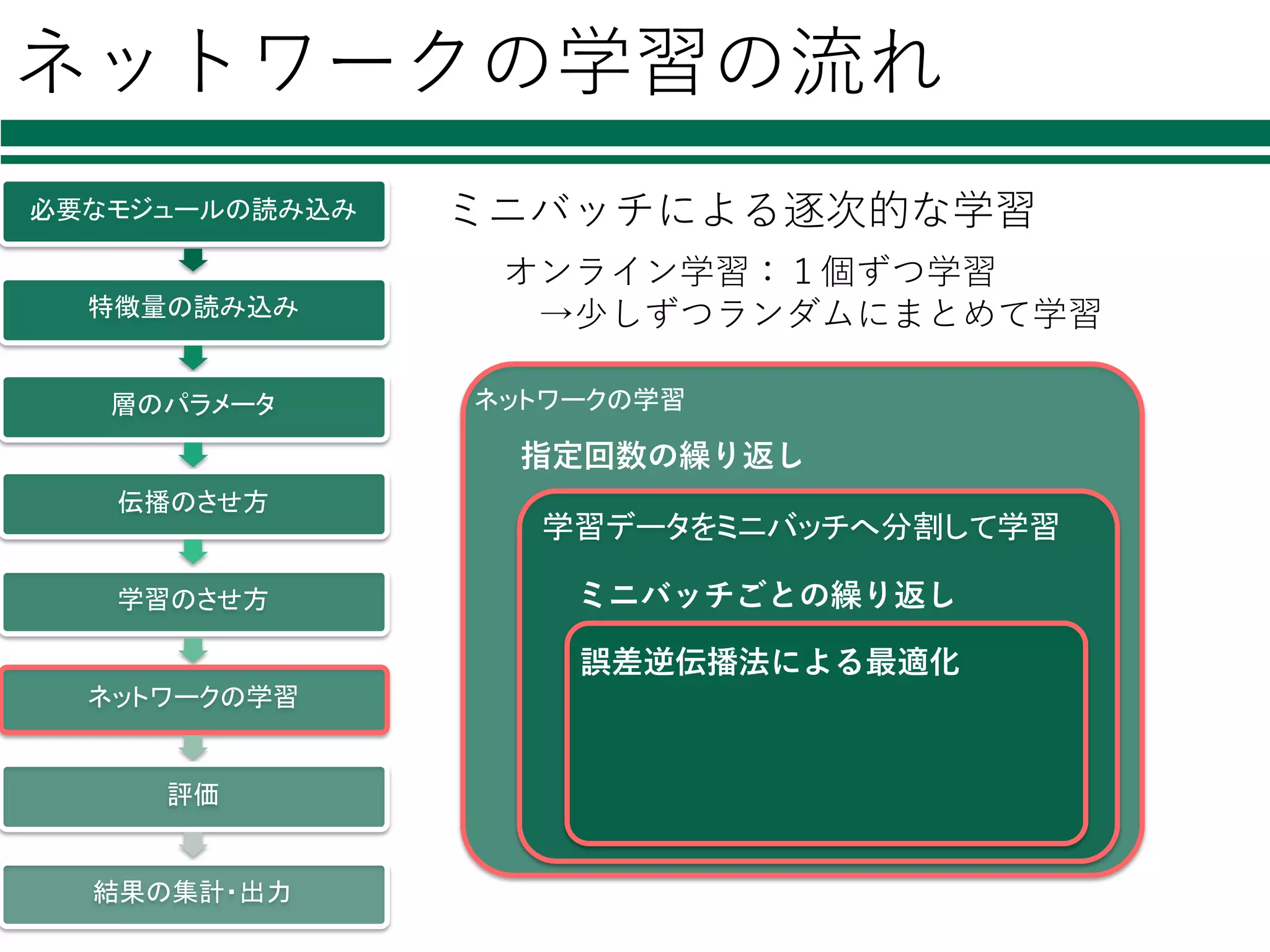
ネットワークの学習の流れ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ミニバッチによる逐次的な学習 オンライン学習:1個ずつ学習 →少しずつランダムにまとめて学習 ネットワークの学習 学習データをミニバッチへ分割して学習 指定回数の繰り返し ミニバッチごとの繰り返し 誤差逆伝播法による最適化
53.
ネットワークの学習 1/2 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 x_batch =
data_train[perm[i:i+batchsize]] t_batch = label_train[perm[i:i+batchsize]] optimizer.zero_grads() x = Variable(x_batch) t = Variable(t_batch) loss = model(x, t) accuracy = model.accuracy loss.backward() optimizer.update() ミニバッチごとの誤差逆伝播法による学習 ミニバッチ 型を変換 ネットワークを通して 誤差を評価 誤差の逆伝播 パラメータの更新
54.
ネットワークの学習の流れ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ミニバッチによる逐次的な学習 ネットワークの学習 学習データをミニバッチへ分割して学習 指定回数の繰り返し ミニバッチごとの繰り返し 誤差逆伝播法による最適化 オンライン学習:1個ずつ学習 →少しずつランダムにまとめて学習
55.
ネットワークの学習 2/2 perm =
np.random.permutation(N) sum_accuracy = 0 sum_loss = 0 for i in range(0, N, batchsize): (前述の順伝播,誤差逆伝播で lossとaccuracyを得る) sum_loss += float(loss.data) * len(x_batch) sum_accuracy += float(accuracy.data) * len(x_batc l = sum_loss / N a = sum_accuracy /N print("loss: %f, accuracy: %f" % (l, a)) ミニバッチの分割の 仕⽅を決定 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ミニバッチの分割と繰り返し この処理を, ミニバッチの分割の仕⽅を変えながらepoch分繰り返す 繰り返し回数
56.
ネットワークの学習の流れ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 ミニバッチによる逐次的な学習 ネットワークの学習 学習データをミニバッチへ分割して学習 指定回数の繰り返し ミニバッチごとの繰り返し 誤差逆伝播法による最適化 オンライン学習:1個ずつ学習 →少しずつランダムにまとめて学習
57.
評価のしかた network.is_train = False test_input
= Variable(data_test) result_scores = network(test_input) 各クラスのスコアが出てくるので argmax を取る 今回は学習時ではない = Dropoutしない results = np.argmax(result_scores, axis=1) 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 評価データをネットワークに通す 最終出⼒層の最⼤値を選択
58.
CUDAによるGPUを使った⾼速化 model = L.Classifier(network) model.to_gpu() x
= Variable(cuda.to_gpu(x_batch)) 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 CPU上での計算をGPU上へ移す (to_gpu()) model と Variableへ渡す変数をGPUへ GPUの利⽤ from chainer import cuda 必要なモジュールをインポート modelをGPUへ Variableへ渡す変数をGPUへ
59.
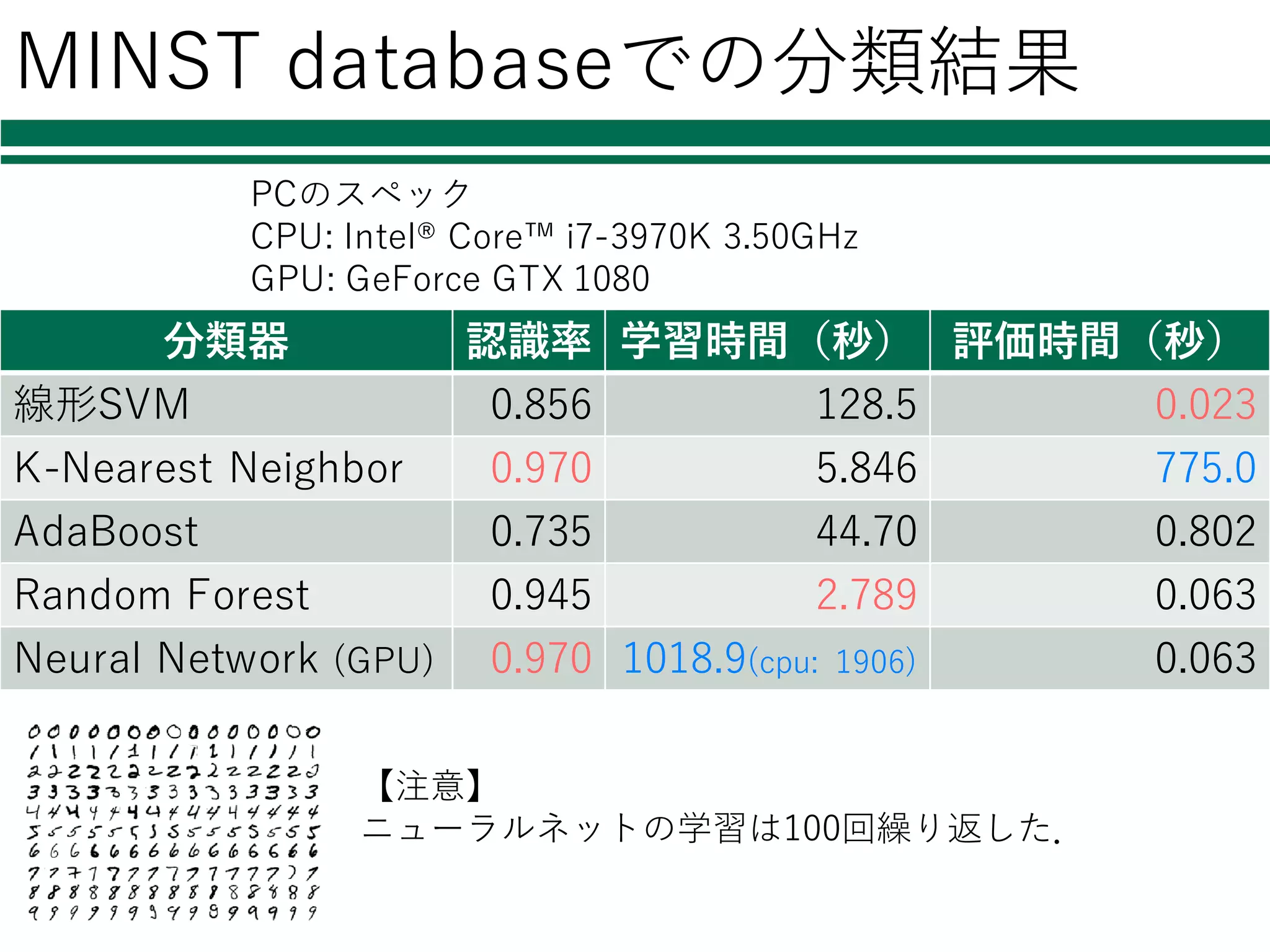
MINST databaseでの分類結果 分類器 認識率
学習時間(秒) 評価時間(秒) 線形SVM 0.856 128.5 0.023 K-Nearest Neighbor 0.970 5.846 775.0 AdaBoost 0.735 44.70 0.802 Random Forest 0.945 2.789 0.063 Neural Network (GPU) 0.970 1018.9(cpu: 1906) 0.063 【注意】 ニューラルネットの学習は100回繰り返した. PCのスペック CPU: Intel® Core™ i7-3970K 3.50GHz GPU: GeForce GTX 1080
60.
KERASでの実装
61.
Kerasの仕組み lメインの計算部分はバックエンドが担当 Øバックエンド ²Theano ²TensorFlow ØバックエンドがGPU対応していれば, ⾃動的にGPUで実⾏される l直感的な記述法 Øネットワークの層を順番に書く Øscikit-learn的な学習(fit),評価(predict)
62.
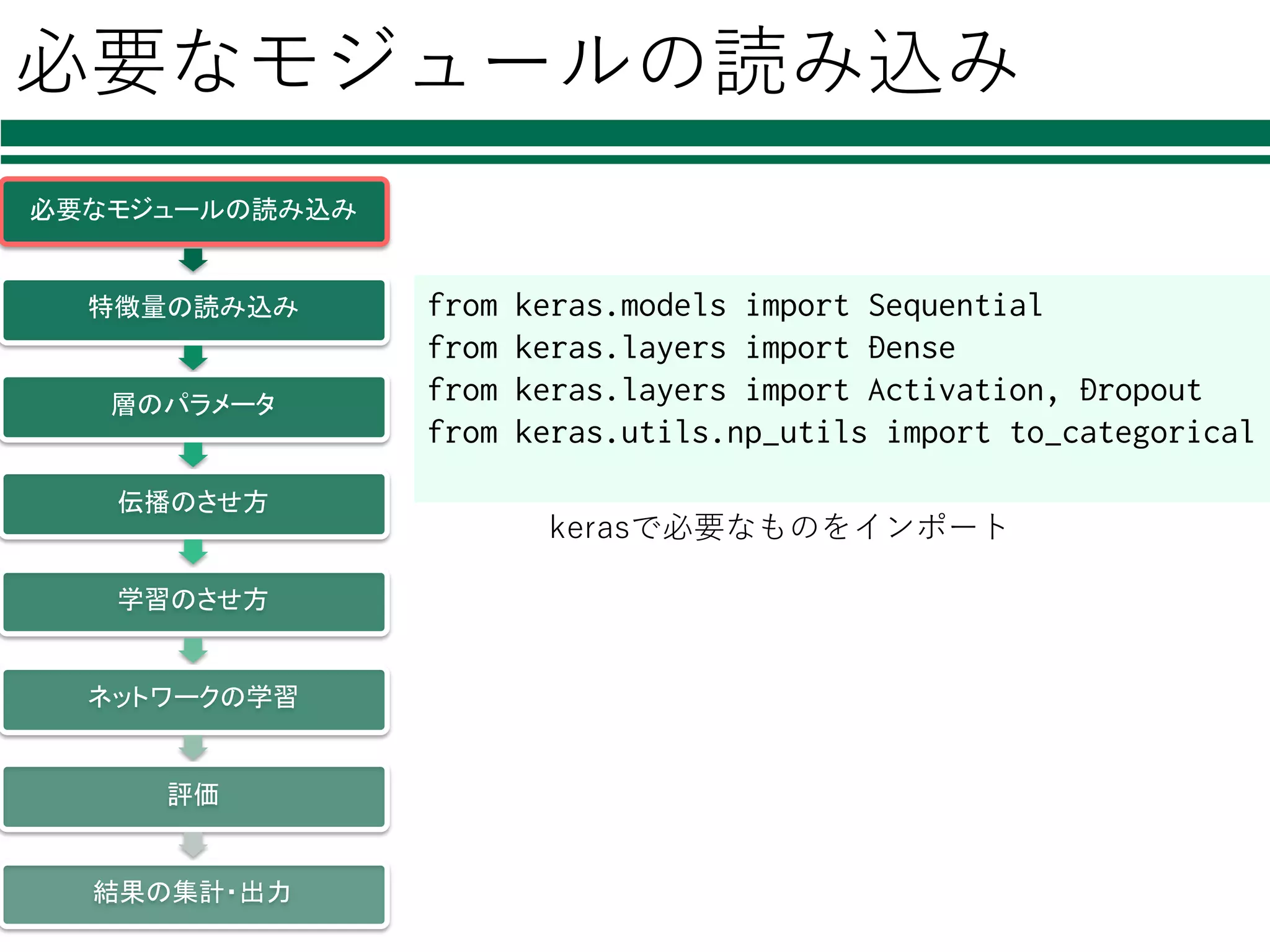
必要なモジュールの読み込み 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 from keras.models import
Sequential from keras.layers import Dense from keras.layers import Activation, Dropout from keras.utils.np_utils import to_categorical kerasで必要なものをインポート
63.
ネットワーク構築 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 kerasではネットワーク構築は⼀気にやる model = Sequential() model.add(Dense(200,
input_dim=784)) model.add(Activation("relu")) model.add(Dropout(0.5)) model.add(Dense(100)) model.add(Activation("relu")) model.add(Dropout(0.5)) model.add(Dense(10)) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) ⼀番最初の層の ⼊⼒次元数は指定する 誤差関数,最適化法, 途中の評価⽅法を指定
64.
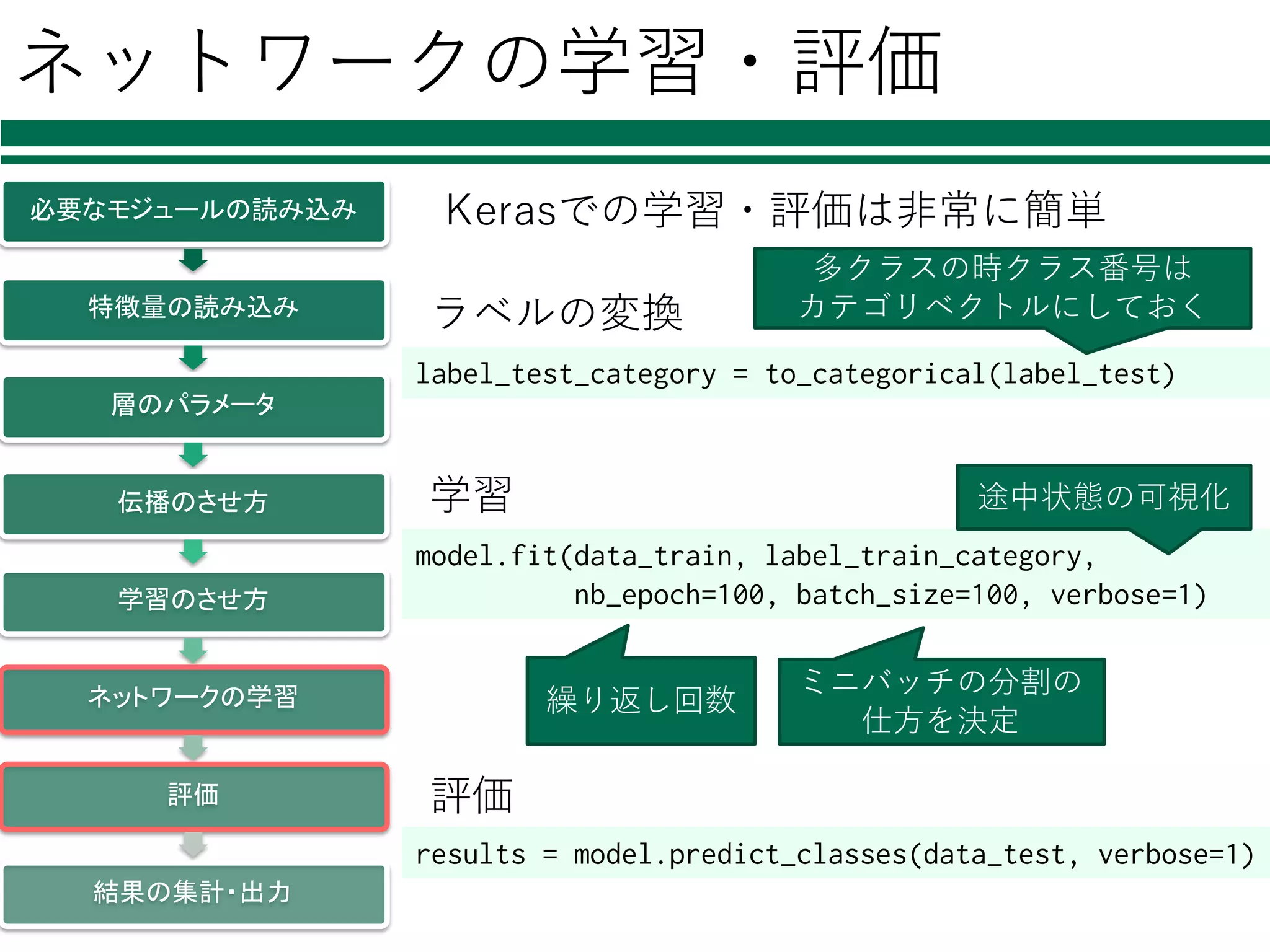
ネットワークの学習・評価 model.fit(data_train, label_train_category, nb_epoch=100, batch_size=100,
verbose=1) ミニバッチの分割の 仕⽅を決定 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 Kerasでの学習・評価は⾮常に簡単 results = model.predict_classes(data_test, verbose=1) 学習 評価 繰り返し回数 途中状態の可視化 label_test_category = to_categorical(label_test) ラベルの変換 多クラスの時クラス番号は カテゴリベクトルにしておく
65.
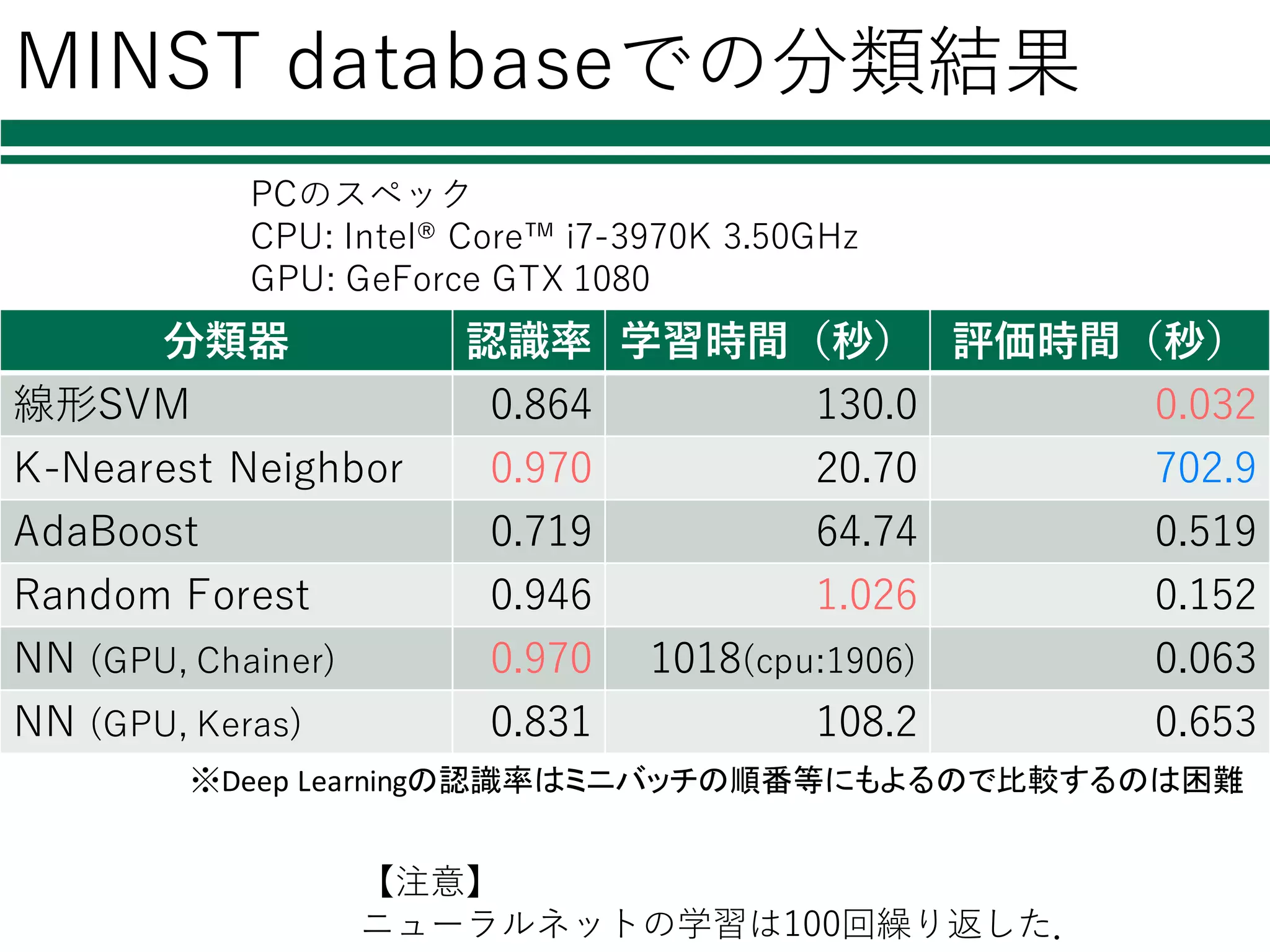
MINST databaseでの分類結果 分類器 認識率
学習時間(秒) 評価時間(秒) 線形SVM 0.864 130.0 0.032 K-Nearest Neighbor 0.970 20.70 702.9 AdaBoost 0.719 64.74 0.519 Random Forest 0.946 1.026 0.152 NN (GPU, Chainer) 0.970 1018(cpu:1906) 0.063 NN (GPU, Keras) 0.831 108.2 0.653 【注意】 ニューラルネットの学習は100回繰り返した. PCのスペック CPU: Intel® Core™ i7-3970K 3.50GHz GPU: GeForce GTX 1080 ※Deep Learningの認識率はミニバッチの順番等にもよるので比較するのは困難
66.
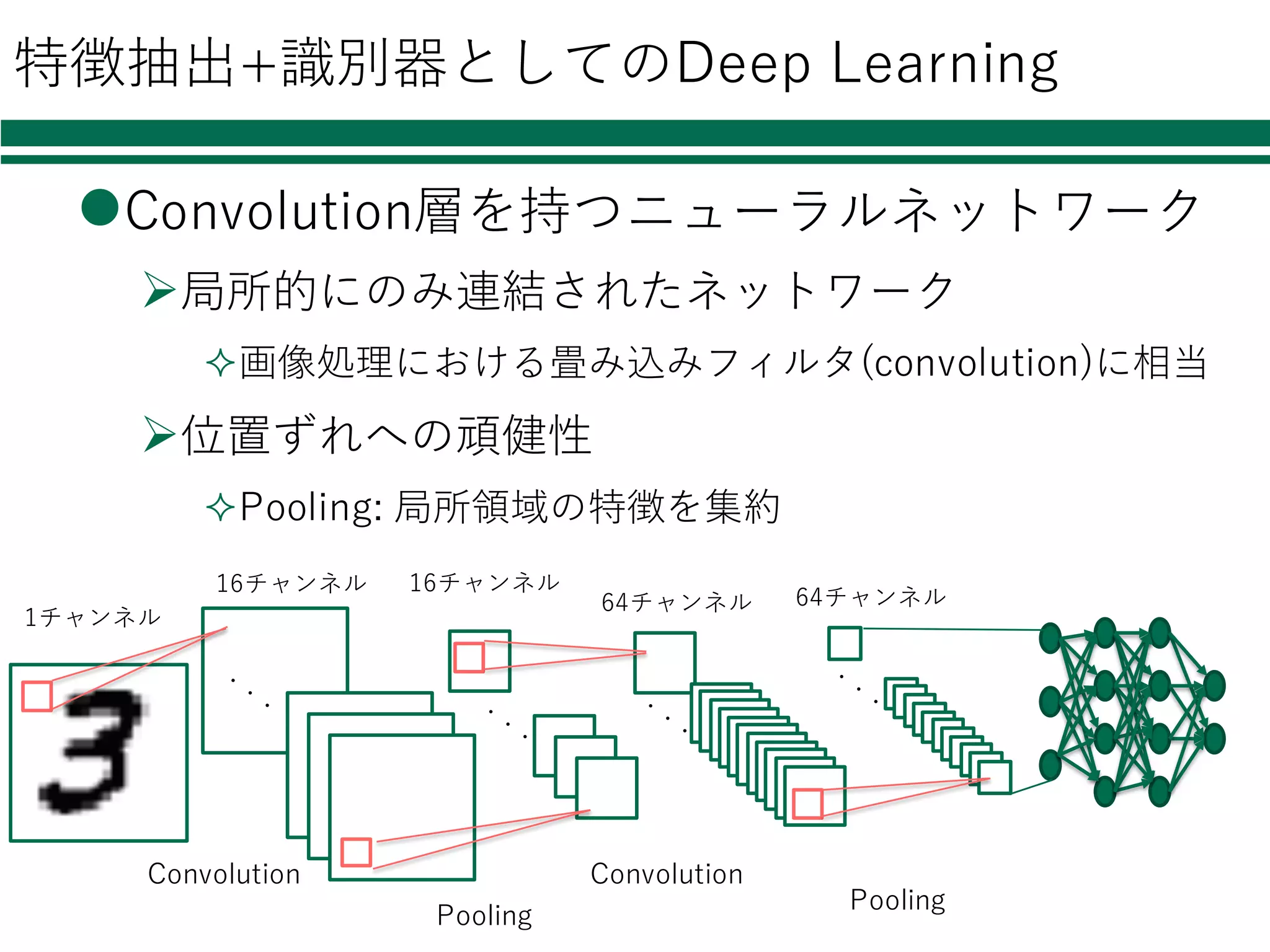
特徴抽出+識別器としてのDeep Learning lConvolution層を持つニューラルネットワーク Ø局所的にのみ連結されたネットワーク ²画像処理における畳み込みフィルタ(convolution)に相当 Ø位置ずれへの頑健性 ²Pooling: 局所領域の特徴を集約 16チャンネル 1チャンネル Convolution Pooling 64チャンネル 16チャンネル Convolution Pooling 64チャンネル
67.
CNNを使う時の処理⼿順 必要なモジュールの読み込み 画像の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 前 述 の DeepLearning の 処 理 の ⼿ 順 CNN を 使 う 場 合 の 処 理 の ⼿ 順 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力
68.
画像の読み込み 必要なモジュールの読み込み 画像の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 def conv_feat_2_image(feats): data =
np.ndarray((len(feats), 1, 28, 28), dtype=np.float32) for i, f in enumerate(feats): data[i]=f.reshape(28,28) return data train_images = conv_feat_2_image(train_features) test_images = conv_feat_2_image(test_features) 学習データ,評価データを画像列に変換する 画像列に変換する関数 CNNへの⼊⼒は2次元画像 [特徴量] [特徴量] … [特徴量] 画像 画像画像画像 枚数xチャンネル数 x⾼さx幅 枚数x次元数
69.
CHAINERでの実装
70.
層のパラメータ 必要なモジュールの読み込み 画像の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 class MyNetwork(Chain): def __init__(self): super(MyNetwork,
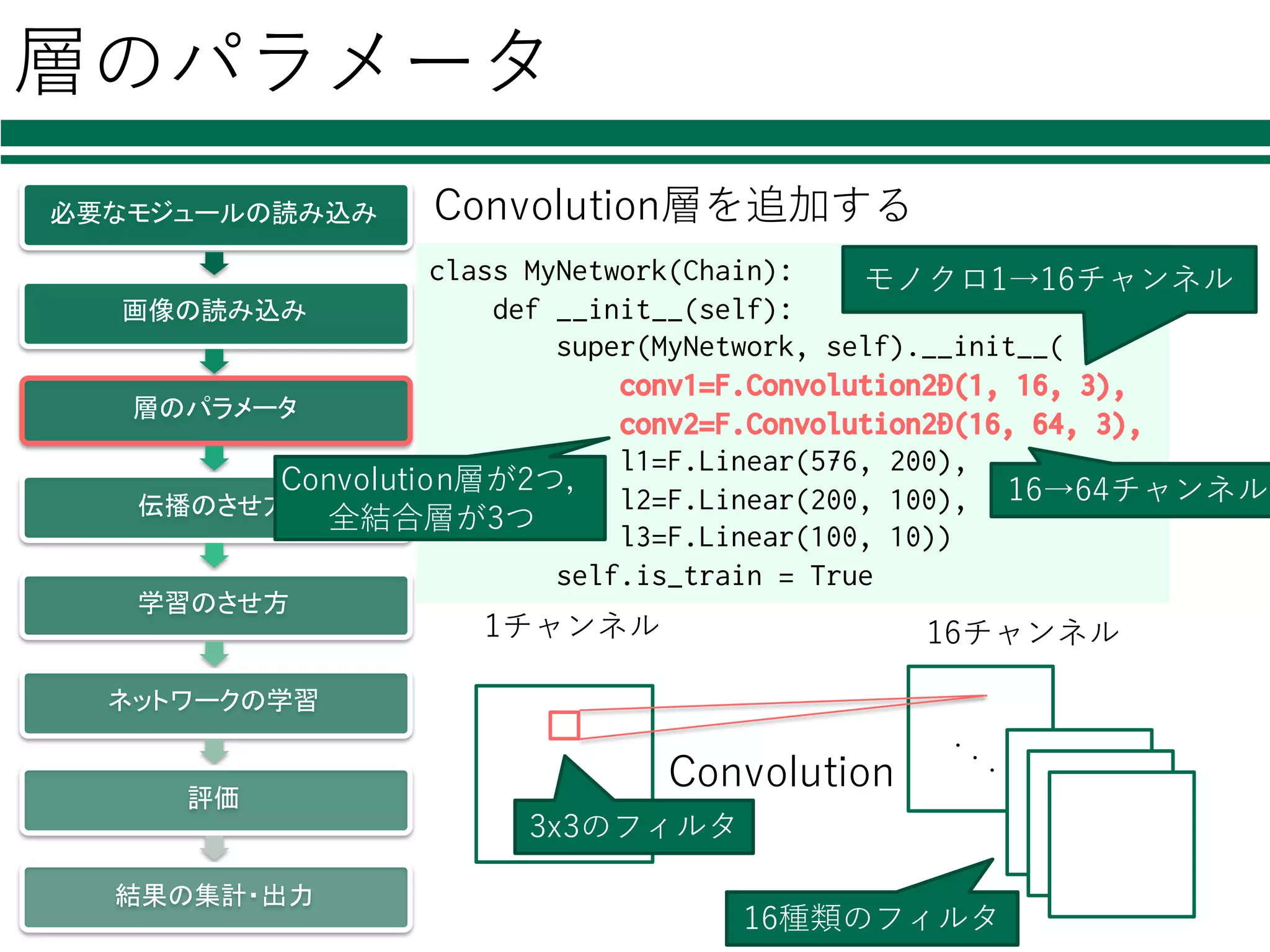
self).__init__( conv1=F.Convolution2D(1, 16, 3), conv2=F.Convolution2D(16, 64, 3), l1=F.Linear(576, 200), l2=F.Linear(200, 100), l3=F.Linear(100, 10)) self.is_train = True Convolution層が2つ, 全結合層が3つ モノクロ1→16チャンネル 16→64チャンネル 16チャンネル1チャンネル Convolution 3x3のフィルタ 16種類のフィルタ Convolution層を追加する
71.
伝播のさせ⽅ 必要なモジュールの読み込み 画像の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 Pooling層を追加する def __call__(self, x): h1
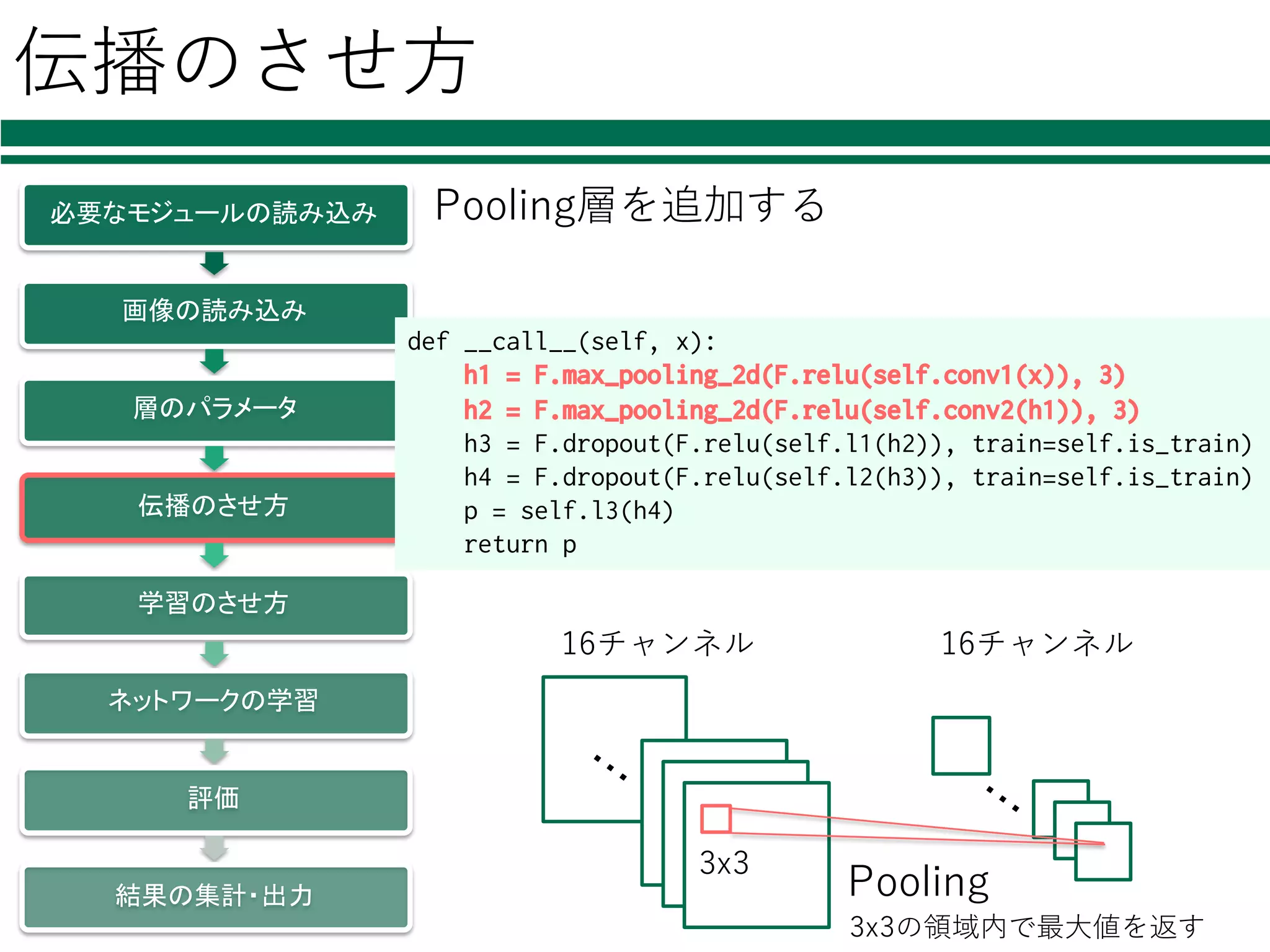
= F.max_pooling_2d(F.relu(self.conv1(x)), 3) h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), 3) h3 = F.dropout(F.relu(self.l1(h2)), train=self.is_train) h4 = F.dropout(F.relu(self.l2(h3)), train=self.is_train) p = self.l3(h4) return p 16チャンネル 16チャンネル Pooling 3x3 3x3の領域内で最⼤値を返す
72.
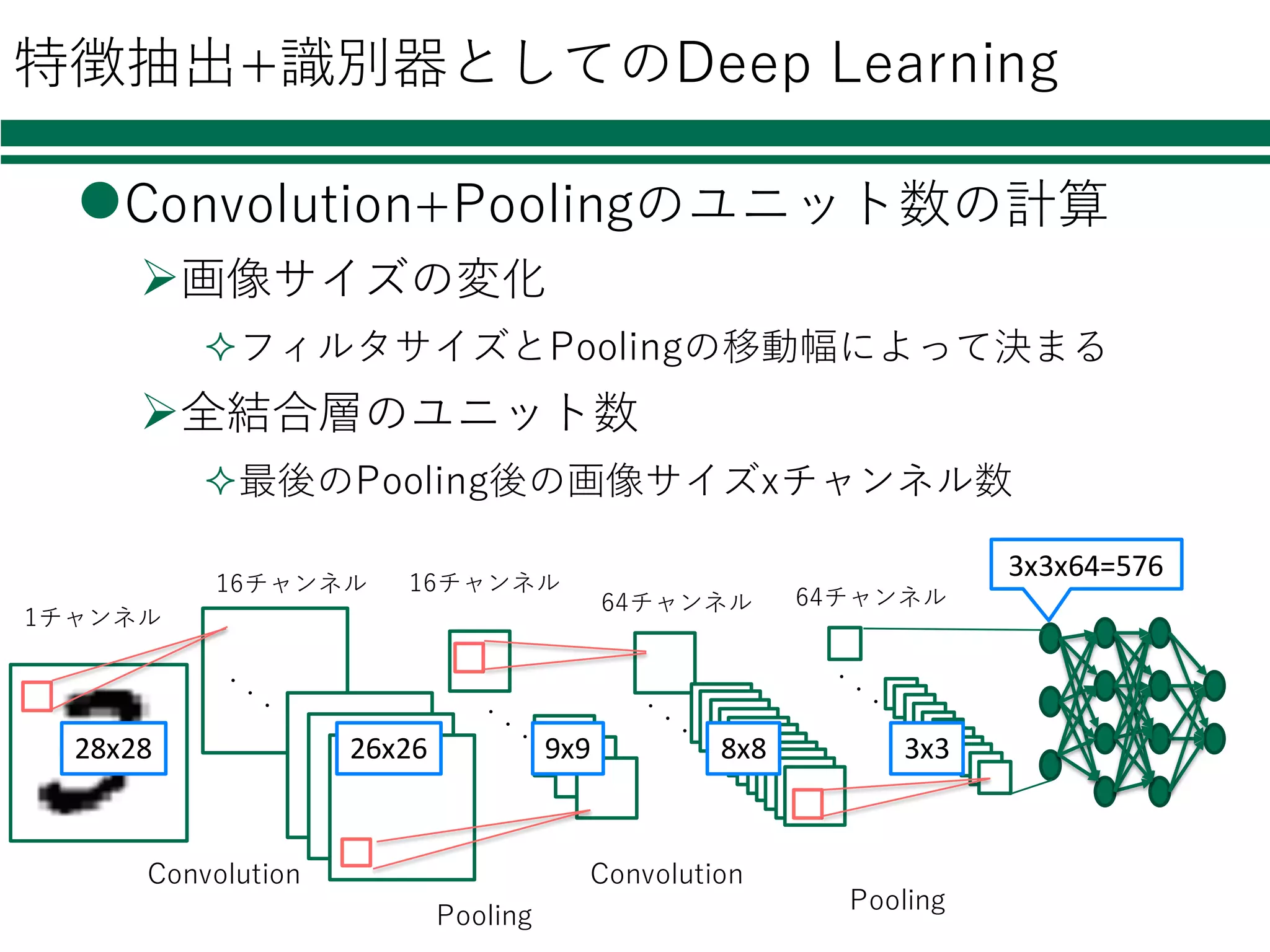
特徴抽出+識別器としてのDeep Learning lConvolution+Poolingのユニット数の計算 Ø画像サイズの変化 ²フィルタサイズとPoolingの移動幅によって決まる Ø全結合層のユニット数 ²最後のPooling後の画像サイズxチャンネル数 16チャンネル 1チャンネル Convolution Pooling 64チャンネル 16チャンネル Convolution Pooling 64チャンネル 28x28 26x26
9x9 8x8 3x3 3x3x64=576
73.
KERASでの実装
74.
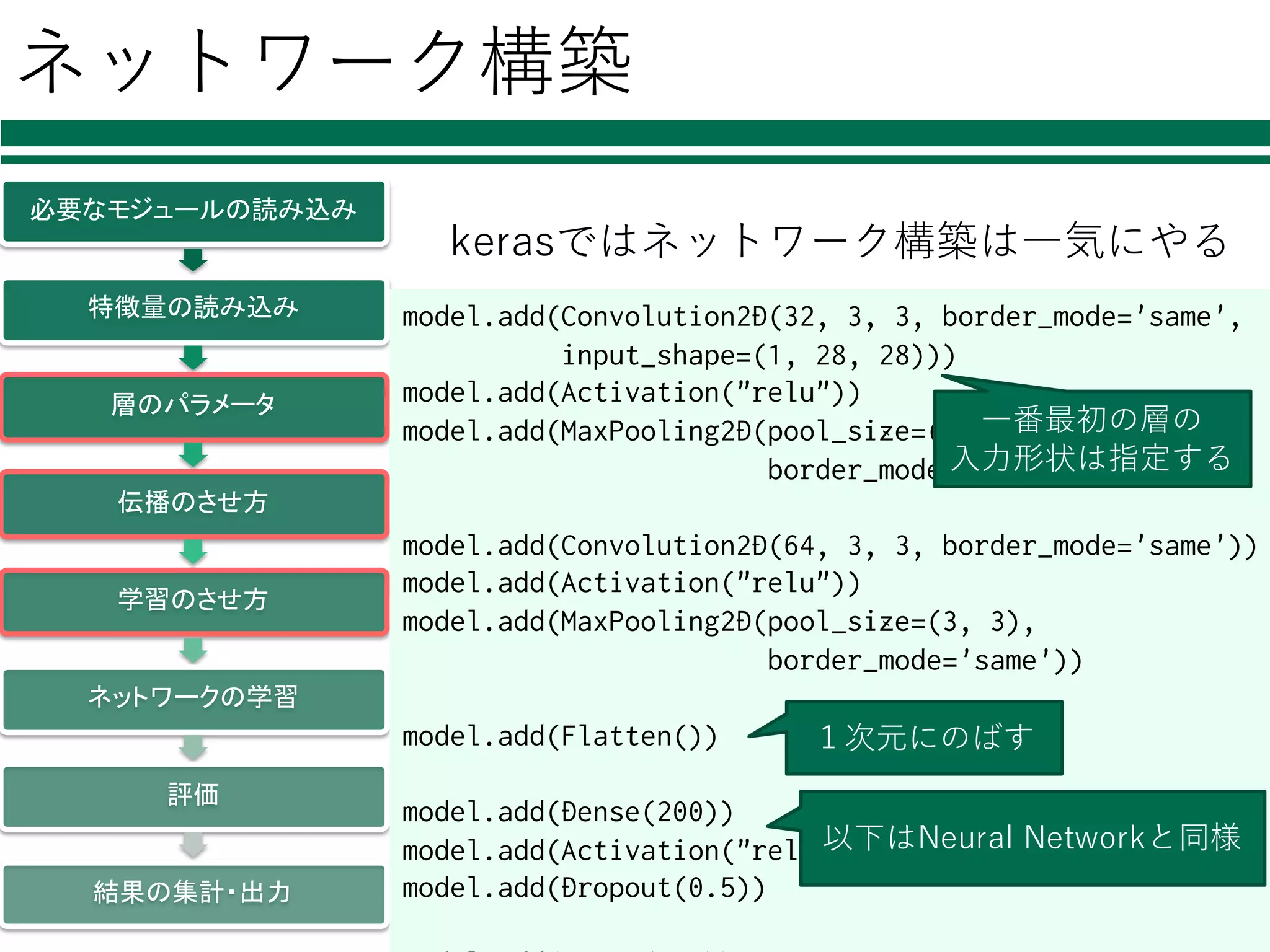
ネットワーク構築 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 kerasではネットワーク構築は⼀気にやる model.add(Convolution2D(32, 3, 3,
border_mode='same', input_shape=(1, 28, 28))) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(3, 3), border_mode='same')) model.add(Convolution2D(64, 3, 3, border_mode='same')) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(3, 3), border_mode='same')) model.add(Flatten()) model.add(Dense(200)) model.add(Activation("relu")) model.add(Dropout(0.5)) ⼀番最初の層の ⼊⼒形状は指定する 以下はNeural Networkと同様 1次元にのばす
75.
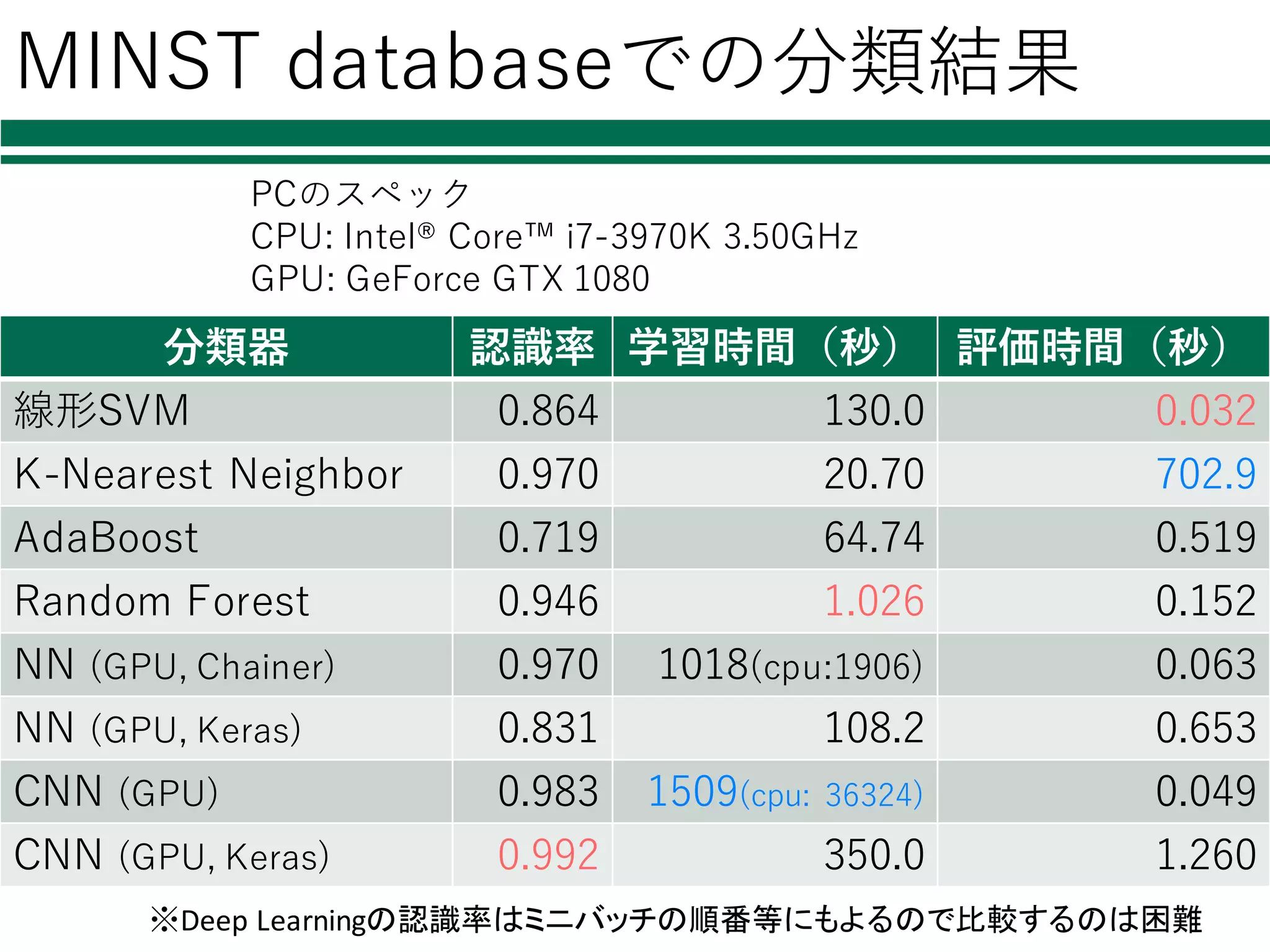
MINST databaseでの分類結果 分類器 認識率
学習時間(秒) 評価時間(秒) 線形SVM 0.864 130.0 0.032 K-Nearest Neighbor 0.970 20.70 702.9 AdaBoost 0.719 64.74 0.519 Random Forest 0.946 1.026 0.152 NN (GPU, Chainer) 0.970 1018(cpu:1906) 0.063 NN (GPU, Keras) 0.831 108.2 0.653 CNN (GPU) 0.983 1509(cpu: 36324) 0.049 CNN (GPU, Keras) 0.992 350.0 1.260 PCのスペック CPU: Intel® Core™ i7-3970K 3.50GHz GPU: GeForce GTX 1080 ※Deep Learningの認識率はミニバッチの順番等にもよるので比較するのは困難
76.
学習済みモデルの利⽤ lいちからネットワークを学習させるのは困難 Ø別データセットで学習させたものを流⽤ ²ネットワークの出⼒を"付け替えて"追加学習 Ømodel zooでは多数の学習済みモデルが公開 ²https://github.com/BVLC/caffe/wiki/Model-Zoo ²様々なモデル – AlexNet,
GoogLeNet, VGG, etc. ²様々なデータセット – ImageNet, Places205, etc.
77.
学習済みモデルの読み込みと利⽤ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 model = caffe.CaffeFunction("pretrained.caffemodel") model.to_gpu() ChainerはCaffeでの学習済みモデルを 容易に読み込むことが出来る 読み込んだモデルは,関数として利⽤可 result = model(inputs={"data": x}, outputs=["fc8"], train=False) 入力を,どの層に 入れるか どの層から出力を とるか この場合,result[0]に fc8
の出⼒を得る そのまま出⼒すれば,元のネットワークの出⼒が出来る
78.
学習済みモデルの読み込みと利⽤ 必要なモジュールの読み込み 特徴量の読み込み 層のパラメータ 伝播のさせ方 学習のさせ方 ネットワークの学習 評価 結果の集計・出力 caffeのモデルを関数の⼀部として利⽤ class BinClassNet(Chain): def __init__(self, caffemodel): super(BinClassNet, self).__init__( base = caffemodel, hlayer = L.Linear(4096, 2000), olayer
= L.Linear(2000, 2)) self.train = True def __call__(self, x): h1 = self.base(inputs={"data": x}, outputs=["fc7"], train=self.train) h2 = F.relu(self.hlayer(h1[0])) h3 = self.olayer(h2) return h3 7層目から出力
79.
参考⽂献・Webページ l今回のサンプルコード Øhttps://github.com/yasutomo57jp/deeplearning_sa mples lSSII2016の時の講演のサンプルコード Ø https://github.com/yasutomo57jp/ssii2016_tutorial l電⼦情報通信学会総合⼤会 2016
企画セッション 「パターン認識・メディア理解」 必須ソフトウェアライブラリ ⼿とり⾜とりガイド Øhttp://www.slideshare.net/yasutomo57jp/pythonde ep-learning-60544586 62
80.
Pythonを勉強するための資料集 l Python Scientific
Lecture Notes Ø ⽇本語訳: http://turbare.net/transl/scipy-lecture-notes/index.html Ø ⾮常におすすめ Ø numpy/scipyから画像処理,3D可視化まで幅広く学べる l @shima__shimaさん Ø 機械学習の Python との出会い ² numpyと簡単な機械学習への利⽤ l @payashimさん Ø PyConJP 2014での「OpenCVのpythonインターフェース⼊⾨」の資料 ² Pythonユーザ向けの,OpenCVを使った画像処理解説
81.
まとめ lPythonで機械学習 ØScikit-learnで様々な分類器を切り替えて利⽤ lDeep Learningツールの紹介 ØChainer ²⽐較的分かりやすい記述⽅法 ²caffeの学習済みモデルを読み込める ØKeras ²記述⽅法が直感的 ²学習⼿順が容易 – 最近はChainerも学習⼿順を簡単に書けるようになっています
Download













![特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
minst.targetmnist.data
特徴量とラベルの表現形式
学習⽤正解ラベル学習⽤特徴量
numpyのndarray(多次元配列)形式
1⾏が1つの特徴量.それに対応するラベル.
(サンプル数, 特徴量)の⾏列](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-22-2048.jpg)
![特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
data_train, data_test, label_train, label_test = ¥
train_test_split(data, mnist.target, test_size=0.2)
特徴量と正解ラベルを
学習データと評価データへ分割
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
mnist.data mnist.target
data_test label_testdata_train label_train
学習データ 評価データ
2割を評価用
にする](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-23-2048.jpg)









![ネットワークの学習 1/2
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
x_batch = data_train[perm[i:i+batchsize]]
t_batch = label_train[perm[i:i+batchsize]]
optimizer.zero_grads()
x = Variable(x_batch)
t = Variable(t_batch)
loss = model(x, t)
accuracy = model.accuracy
loss.backward()
optimizer.update()
ミニバッチごとの誤差逆伝播法による学習
ミニバッチ
型を変換
ネットワークを通して
誤差を評価
誤差の逆伝播
パラメータの更新](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-53-2048.jpg)





![ネットワーク構築
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
kerasではネットワーク構築は⼀気にやる
model = Sequential()
model.add(Dense(200, input_dim=784))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(100))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
⼀番最初の層の
⼊⼒次元数は指定する
誤差関数,最適化法,
途中の評価⽅法を指定](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-63-2048.jpg)

![画像の読み込み
必要なモジュールの読み込み
画像の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
def conv_feat_2_image(feats):
data = np.ndarray((len(feats), 1, 28, 28),
dtype=np.float32)
for i, f in enumerate(feats):
data[i]=f.reshape(28,28)
return data
train_images = conv_feat_2_image(train_features)
test_images = conv_feat_2_image(test_features)
学習データ,評価データを画像列に変換する
画像列に変換する関数
CNNへの⼊⼒は2次元画像
[特徴量]
[特徴量]
…
[特徴量]
画像
画像画像画像
枚数xチャンネル数
x⾼さx幅
枚数x次元数](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-68-2048.jpg)



![学習済みモデルの読み込みと利⽤
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
model = caffe.CaffeFunction("pretrained.caffemodel")
model.to_gpu()
ChainerはCaffeでの学習済みモデルを
容易に読み込むことが出来る
読み込んだモデルは,関数として利⽤可
result = model(inputs={"data": x}, outputs=["fc8"], train=False)
入力を,どの層に
入れるか
どの層から出力を
とるか
この場合,result[0]に fc8 の出⼒を得る
そのまま出⼒すれば,元のネットワークの出⼒が出来る](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-77-2048.jpg)
![学習済みモデルの読み込みと利⽤
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
caffeのモデルを関数の⼀部として利⽤
class BinClassNet(Chain):
def __init__(self, caffemodel):
super(BinClassNet, self).__init__(
base = caffemodel,
hlayer = L.Linear(4096, 2000),
olayer = L.Linear(2000, 2))
self.train = True
def __call__(self, x):
h1 = self.base(inputs={"data": x}, outputs=["fc7"],
train=self.train)
h2 = F.relu(self.hlayer(h1[0]))
h3 = self.olayer(h2)
return h3
7層目から出力](https://image.slidesharecdn.com/ieeeitssnagoya-160722034813/75/Python-Deep-Learning-78-2048.jpg)





















![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...](https://cdn.slidesharecdn.com/ss_thumbnails/wakasugi-180824003300-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)










![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)









