Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takashi J OZAKI
158,581 views
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
R初心者向け講座「Rによるやさしい統計学第20章『検定力分析によるサンプルサイズの決定』」20140222 TokyoR #36
Technology
◦
Read more
91
Save
Share
Embed
Embed presentation
1
/ 49
2
/ 49
3
/ 49
4
/ 49
5
/ 49
6
/ 49
7
/ 49
8
/ 49
9
/ 49
10
/ 49
11
/ 49
12
/ 49
13
/ 49
14
/ 49
15
/ 49
16
/ 49
17
/ 49
Most read
18
/ 49
19
/ 49
20
/ 49
21
/ 49
22
/ 49
23
/ 49
24
/ 49
25
/ 49
26
/ 49
27
/ 49
28
/ 49
Most read
29
/ 49
30
/ 49
31
/ 49
Most read
32
/ 49
33
/ 49
34
/ 49
35
/ 49
36
/ 49
37
/ 49
38
/ 49
39
/ 49
40
/ 49
41
/ 49
42
/ 49
43
/ 49
44
/ 49
45
/ 49
46
/ 49
47
/ 49
48
/ 49
49
/ 49
More Related Content
PDF
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
負の二項分布について
by
Hiroshi Shimizu
PDF
MICの解説
by
logics-of-blue
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
Rで階層ベイズモデル
by
Yohei Sato
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
階層ベイズによるワンToワンマーケティング入門
by
shima o
負の二項分布について
by
Hiroshi Shimizu
MICの解説
by
logics-of-blue
一般化線形混合モデル入門の入門
by
Yu Tamura
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
What's hot
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PPTX
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
PPTX
論文の書き方入門 2017
by
Hironori Washizaki
PDF
Surveyから始まる研究者への道 - Stand on the shoulders of giants -
by
諒介 荒木
PDF
最適輸送入門
by
joisino
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PPTX
分割時系列解析(ITS)の入門
by
Koichiro Gibo
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
2 3.GLMの基礎
by
logics-of-blue
PPTX
形状解析のための楕円フーリエ変換
by
Tsukasa Fukunaga
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
関数データ解析の概要とその方法
by
Hidetoshi Matsui
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
2 4.devianceと尤度比検定
by
logics-of-blue
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
論文の書き方入門 2017
by
Hironori Washizaki
Surveyから始まる研究者への道 - Stand on the shoulders of giants -
by
諒介 荒木
最適輸送入門
by
joisino
研究効率化Tips Ver.2
by
cvpaper. challenge
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
Stanでガウス過程
by
Hiroshi Shimizu
分割時系列解析(ITS)の入門
by
Koichiro Gibo
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
階層モデルの分散パラメータの事前分布について
by
hoxo_m
Stanコードの書き方 中級編
by
Hiroshi Shimizu
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
2 3.GLMの基礎
by
logics-of-blue
形状解析のための楕円フーリエ変換
by
Tsukasa Fukunaga
機械学習モデルのハイパパラメータ最適化
by
gree_tech
Viewers also liked
PDF
有意性と効果量について しっかり考えてみよう
by
Ken Urano
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PDF
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
PDF
Rによるやさしい統計学 第16章 : 因子分析
by
Hidekazu Tanaka
PDF
明日から読めるメタ・アナリシス
by
Yasuyuki Okumura
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
有意性と効果量について しっかり考えてみよう
by
Ken Urano
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
Rによるやさしい統計学 第16章 : 因子分析
by
Hidekazu Tanaka
明日から読めるメタ・アナリシス
by
Yasuyuki Okumura
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
Stan超初心者入門
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
Similar to Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
PDF
20170225_Sample size determination
by
Takanori Hiroe
PPTX
20150827_simplesize
by
Takanori Hiroe
PPTX
統計的検定と例数設計の基礎
by
Senshu University
PDF
Regression2
by
Yuta Tomomatsu
PPTX
生物系研究者のための統計講座
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
PPTX
Darm3(samplesize)
by
Yoshitake Takebayashi
PDF
Rm20140702 11key
by
youwatari
PDF
Eureka agora tech talk 20170829
by
Shinnosuke Ohkubo
PDF
検定力分析とベイズファクターデザイン分析によるサンプルサイズ設計【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
Chapter.13: Goals, Power and Sample Size "Doing Bayesian Data Analysis: A Tu...
by
Hajime Sasaki
PDF
第6章 2つの平均値を比較する - TokyoR #28
by
horihorio
PDF
Rm20130626 10key
by
youwatari
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
第5回スキル養成講座 講義スライド
by
keiodig
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PPTX
R言語による簡便な有意差の検出と信頼区間の構成
by
Toshiyuki Shimono
PPT
K090 仮説検定
by
t2tarumi
PPTX
Rで学ぶデータサイエンス第1章(判別能力の評価)
by
Daisuke Yoneoka
20170225_Sample size determination
by
Takanori Hiroe
20150827_simplesize
by
Takanori Hiroe
統計的検定と例数設計の基礎
by
Senshu University
Regression2
by
Yuta Tomomatsu
生物系研究者のための統計講座
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
Darm3(samplesize)
by
Yoshitake Takebayashi
Rm20140702 11key
by
youwatari
Eureka agora tech talk 20170829
by
Shinnosuke Ohkubo
検定力分析とベイズファクターデザイン分析によるサンプルサイズ設計【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
Chapter.13: Goals, Power and Sample Size "Doing Bayesian Data Analysis: A Tu...
by
Hajime Sasaki
第6章 2つの平均値を比較する - TokyoR #28
by
horihorio
Rm20130626 10key
by
youwatari
「統計的学習理論」第1章
by
Kota Matsui
第5回スキル養成講座 講義スライド
by
keiodig
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
R言語による簡便な有意差の検出と信頼区間の構成
by
Toshiyuki Shimono
K090 仮説検定
by
t2tarumi
Rで学ぶデータサイエンス第1章(判別能力の評価)
by
Daisuke Yoneoka
More from Takashi J OZAKI
PDF
直感的な単変量モデルでは予測できない「ワインの味」を多変量モデルで予測する
by
Takashi J OZAKI
PDF
Taste of Wine vs. Data Science
by
Takashi J OZAKI
PDF
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
PDF
Tech Lab Paak講演会 20150601
by
Takashi J OZAKI
PDF
なぜ統計学がビジネスの 意思決定において大事なのか?
by
Takashi J OZAKI
PDF
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
by
Takashi J OZAKI
PDF
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
PDF
Jc 20141003 tjo
by
Takashi J OZAKI
PDF
データ分析というお仕事のこれまでとこれから(HCMPL2014)
by
Takashi J OZAKI
PDF
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
by
Takashi J OZAKI
PDF
Visualization of Supervised Learning with {arules} + {arulesViz}
by
Takashi J OZAKI
PDF
ビジネスの現場のデータ分析における理想と現実
by
Takashi J OZAKI
PDF
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
by
Takashi J OZAKI
PDF
Rで計量時系列分析~CRANパッケージ総ざらい~
by
Takashi J OZAKI
PDF
最新業界事情から見るデータサイエンティストの「実像」
by
Takashi J OZAKI
PPTX
21世紀で最もセクシーな職業!?「データサイエンティスト」の実像に迫る
by
Takashi J OZAKI
PPTX
Simple perceptron by TJO
by
Takashi J OZAKI
直感的な単変量モデルでは予測できない「ワインの味」を多変量モデルで予測する
by
Takashi J OZAKI
Taste of Wine vs. Data Science
by
Takashi J OZAKI
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
Tech Lab Paak講演会 20150601
by
Takashi J OZAKI
なぜ統計学がビジネスの 意思決定において大事なのか?
by
Takashi J OZAKI
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
by
Takashi J OZAKI
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
Jc 20141003 tjo
by
Takashi J OZAKI
データ分析というお仕事のこれまでとこれから(HCMPL2014)
by
Takashi J OZAKI
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
by
Takashi J OZAKI
Visualization of Supervised Learning with {arules} + {arulesViz}
by
Takashi J OZAKI
ビジネスの現場のデータ分析における理想と現実
by
Takashi J OZAKI
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
by
Takashi J OZAKI
Rで計量時系列分析~CRANパッケージ総ざらい~
by
Takashi J OZAKI
最新業界事情から見るデータサイエンティストの「実像」
by
Takashi J OZAKI
21世紀で最もセクシーな職業!?「データサイエンティスト」の実像に迫る
by
Takashi J OZAKI
Simple perceptron by TJO
by
Takashi J OZAKI
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
1.
Rによるやさしい統計学 第20章「検定力分析によるサンプル サイズの決定」 株式会社リクルートコミュニケーションズ データサイエンティスト 尾崎 隆
(Takashi J. OZAKI, Ph. D.) 2014/2/20 1
2.
一応、自己紹介を… このブログの中の人です 2014/2/20 2
3.
注意点 肝心の僕が『Rによるやさしい統計学』2月になるまで読んだこと ありませんでした 今回の講師も
@yokkuns から 「TJOさんサンプルサイズのブログ記事 書いてたってことは詳しいと思うのでお願い していいですよね?」 と頼まれて、一度断ったものの2回目に頼まれてさすがに断れな かったのでお引き受けした次第 よって内容は結構適当ですごめんなさい 2014/2/20 3
4.
今回の課題図書 2014/2/20 4
5.
今回の課題図書 今日話すのは こちらの方 2014/2/20 こちらはより 深く学びたい 人向け 5
6.
今回のレクチャーの前提 多重比較の問題と 第一種の過誤については 既に皆さん分かっているものとして 話を進めますので 忘れてる方は今のうちに復習を! 2014/2/20 6
7.
「検定力」(検出力)とは何か? 2014/2/20 7
8.
端的に言えば 1.対立仮説が真である時に 2.帰無仮説が棄却される確率 = P([帰無仮説を棄却] |
[対立仮説が真]) 2014/2/20 8
9.
マトリクスでいうとココ 帰無仮説が 正しい 対立仮説が 正しい 帰無仮説を 採択する ① ② 帰無仮説を 棄却する ③ ④ 2014/2/20 9
10.
こいつらが困りもの 帰無仮説が 正しい 対立仮説が 正しい 帰無仮説を 採択する ① ② 帰無仮説を 棄却する ③ ④ 2014/2/20 10
11.
こいつらが困りもの 帰無仮説が 正しい 対立仮説が 正しい 帰無仮説を 採択する ① 第二種の過誤 帰無仮説を 棄却する 第一種の過誤 ③ ④ ② 第一種の過誤も第二種の過誤も、本来正しいはずの仮説に 従わない偏った標本をうっかり掴まされたことで陥る 2014/2/20 11
12.
こいつらが困りもの 帰無仮説が 正しい 対立仮説が 正しい 帰無仮説を 採択する ① 第二種の過誤 帰無仮説を 棄却する 第一種の過誤 ③ ④ 2014/2/20 ② 12
13.
これが欲しい 帰無仮説が 正しい 対立仮説が 正しい 帰無仮説を 採択する ① 第二種の過誤 帰無仮説を 棄却する 第一種の過誤 ③ ④ ② 検定力=1 – P(第二種の過誤) 2014/2/20 13
14.
では、検定力とはどうやって決まる? 1.有意水準 2.対立仮説のもとでの母集団に おける効果の大きさ (効果量 effect size) 3.サンプルサイズ 2014/2/20 14
15.
では、検定力とはどうやって決まる? 1.有意水準 2.対立仮説のもとでの母集団に おける効果の大きさ (効果量 effect size) 3.サンプルサイズ 3つのバランスによって検定力は決まる 2つを固定することで残り1つの最適値を決めることもできる 2014/2/20 15
16.
では、検定力とはどうやって決まる? 1.有意水準 2.対立仮説のもとでの母集団に おける効果の大きさ 検定力 (効果量 effect
size) 分析 3.サンプルサイズ 3つのバランスによって検定力は決まる 2つを固定することで残り1つの最適値を決めることもできる 2014/2/20 16
17.
なぜ検定力分析が必要なのか? 2014/2/20 17
18.
検定力の大小で、検定の結果は変わってしまう 事後分析 既に結果の出た検定に対して「検定力が ○○だったから△△だった」というように原因 究明するためのもの
事前分析 (特に)「○○ぐらい検定力が欲しいので サンプルサイズを◇◇ぐらいにしたい」という ように、これから行う検定を最適化するため のもの 2014/2/20 18
19.
検定力を求めるシミュレーション 2014/2/20 19
20.
モンテカルロ法の要領でやってみる 検定力とは 対立仮説が正しい時に有意な結果が得られる確率
でも、あるサンプルサイズのデータの検定力を知るにはどうしたら 良い? 1回こっきり検定しても何も分からない そこで、シミュレーションしてみよう 意図的に、対立仮説が当てはまり、なおかつサンプルサイズの決 まった母集団を2つ用意する そこから標本をn回無作為に抽出して、毎回t検定する そのうち何回有意(ここではp < 0.05)だったかを見れば、検 定力の近似値が求まる! 2014/2/20 20
21.
とりあえずベタっとやってみる > tval<-numeric(length=10000) # t値を格納する変数 >
count_sig<-0 # 有意な結果を返す検定の総回数 > for (i in 1:10000) { # 10000回のモンテカルロシミュレーション + # 母集団を以下の通りサンプルサイズn = 10で2つ定める + group1<-rnorm(n=10,mean=0,sd=1) # 平均0、標準偏差1 + group2<-rnorm(n=10,mean=0.5,sd=1) # 平均0.5、標準偏差1 + res<-t.test(group1,group2,var.equal=T) # 結果を一時格納 + tval[i]<-res[[1]] # t値そのものを格納する + count_sig<-count_sig+ifelse(res[[3]]<0.05,1,0) # 有意ならカウント +} > count_sig/10000 # 最終的に有意だった割合=検定力は? [1] 0.1849 # サンプルサイズ10の時の検定力は0.185ぐらい 2014/2/20 21
22.
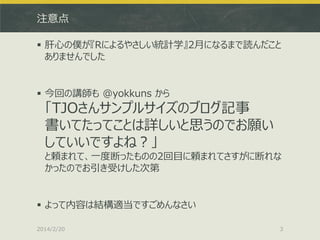
そこでt値の分布を見てみる > hist(tval,breaks=100,freq=F) #
ヒストグラムを描く。縦軸はDensityに t分布っぽく見えるかも? 2014/2/20 22
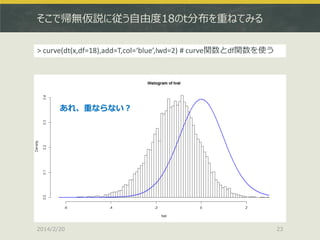
23.
そこで帰無仮説に従う自由度18のt分布を重ねてみる > curve(dt(x,df=18),add=T,col=‘blue’,lwd=2) #
curve関数とdf関数を使う あれ、重ならない? 2014/2/20 23
24.
実は… こいつは非心t分布なのです 2014/2/20 24
25.
一旦こいつから棄却域を出してみる > qt(0.025,df=18) #
下側5%棄却域 [1] -2.100922 > qt(0.025,df=18,lower.tail=F) # 上側5%棄却域 [1] 2.100922 > length(tval[abs(tval)>qt(0.025,df=18,lower.tail=F)]) # 棄却域の値を出す [1] 1849 > count_sig [1] 1849 # 上の値と一致してますね! 2014/2/20 25
26.
ところで、非心t分布のパラメータの求め方 独立な2群のt検定では、検定統計量の標本分布の非心度δ は 1
2 1 1 n1 n2 なので、それぞれ代入すると非心度は 0.0 0.5 0.5 1.118 1 1 1 1.0 10 10 5 ※この辺の詳細は『サンプルサイズの決め方』参照のこと 2014/2/20 26
27.
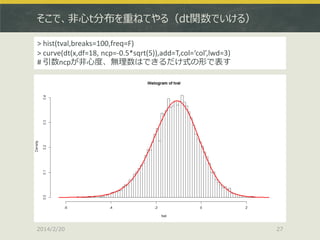
そこで、非心t分布を重ねてやる(dt関数でいける) > hist(tval,breaks=100,freq=F) > curve(dt(x,df=18,
ncp=-0.5*sqrt(5)),add=T,col=‘col’,lwd=3) # 引数ncpが非心度、無理数はできるだけ式の形で表す 2014/2/20 27
28.
詳細について学びたければ改めてこちらを 非心t分布に拠った サンプルサイズの計算方法が これでもかというくらい 解説されています。。。 ※今回はその話はざっくり 割愛します 2014/2/20 28
29.
Rで検定力分析を行う関数 (標準パッケージ) 2014/2/20 29
30.
そもそもRのfor文はトロいので… モンテカルロ法なんて 毎回やりたくない(泣) Rの関数で片付けちゃいましょう 2014/2/20 30
31.
とりあえず{stats}まわりではこの辺 power.t.test t検定の検定力分析 power.anova.test ANOVAの検定力分析 power.prop.test 比率の検定の検定力分析 2014/2/20 31
32.
先ほどの例をそのままやってみる(t検定の場合) > power.t.test(n=10,delta=0.5,sd=1,sig.level=0.05,power=NULL,strict=T) # n:
サンプルサイズ, delta: 平均値の差, sd: 標準偏差 # sig.level: 有意水準, power: 検定力, strict: Trueだと厳密な両側検定 # 知りたい値をNULLにして空けておく Two-sample t test power calculation n = 10 delta = 0.5 sd = 1 sig.level = 0.05 power = 0.1850957 # ←モンテカルロ法の結果とほぼ同じ! alternative = two.sided NOTE: n is number in *each* group 2014/2/20 32
33.
先ほどの例をそのままやってみる(t検定の場合) > power.t.test(n=10,delta=0.5,sd=1,sig.level=0.05,power=NULL,strict=F) # 両側検定の厳密性の指定を外してみた Two-sample
t test power calculation n = 10 delta = 0.5 sd = 1 sig.level = 0.05 power = 0.1838375 # ←ちょっとずれた。。。 alternative = two.sided NOTE: n is number in *each* group 2014/2/20 33
34.
でもむしろ知りたいのはサンプルサイズだよね? どうせならサンプルサイズを 決めたいんだけど… 検定力を決め打ちにすればおk 2014/2/20 34
35.
先ほどの例で検定力を0.8にしてみる(t検定の場合) > power.t.test(n=NULL,delta=0.5,sd=1,sig.level=0.05,power=0.8,strict=T) Two-sample t
test power calculation n = 63.76561 # ←n = 64以上が良いという結論になった delta = 0.5 sd = 1 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group 2014/2/20 35
36.
Rで検定力分析を行う関数 ({pwr}パッケージ) 2014/2/20 36
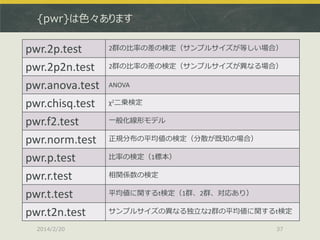
37.
{pwr}は色々あります pwr.2p.test pwr.2p2n.test pwr.anova.test pwr.chisq.test pwr.f2.test pwr.norm.test pwr.p.test pwr.r.test pwr.t.test pwr.t2n.test 2014/2/20 2群の比率の差の検定(サンプルサイズが等しい場合) 2群の比率の差の検定(サンプルサイズが異なる場合) ANOVA χ2二乗検定 一般化線形モデル 正規分布の平均値の検定(分散が既知の場合) 比率の検定(1標本) 相関係数の検定 平均値に関するt検定(1群、2群、対応あり) サンプルサイズの異なる独立な2群の平均値に関するt検定 37
38.
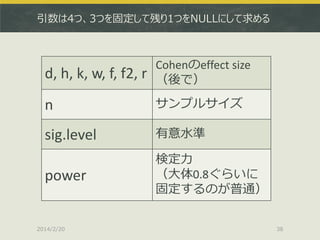
引数は4つ、3つを固定して残り1つをNULLにして求める d, h, k,
w, f, f2, r Cohenのeffect size (後で) n サンプルサイズ sig.level 有意水準 power 検定力 (大体0.8ぐらいに 固定するのが普通) 2014/2/20 38
39.
Effect size(効果量)とは? 端的に言えば「検定が有意な時にどれほどの効果が あるのか」を表すインデックス
例えば以下の2ケースを比べてみると: 鉛筆工場の製造ライン2つの鉛筆を比べたら、 p < 0.05で長さの平均値の差が0.1mm Effect sizeは小さい(意味のない有意差) ある睡眠薬による睡眠時間の延長量を比べたら、 p < 0.05で差が2時間 Effect sizeは大きい(普通のヒトの睡眠時 間を考えたら2時間増は意味がある) 2014/2/20 39
40.
Effect sizeは検定力と併せて検討すべし 一般に、サンプルサイズを大きくしようとすればするほどコストがかかる
Effect sizeが大きければサンプルサイズが小さくても有意になりやすいが、 その逆もまた然り 母集団にある程度のeffect sizeがあると仮定するなら、「確率0.8程度 の確かさ(=検定力)で有意な結果が得られたらハッピー」と期待して サンプルサイズを小さめに決めるという手もある 実際のeffect sizeが小さかったらその分有意になりづらいのでOK 例えば、effect sizeが小さいうちは有意にならなくてもよくて、effect sizeが大きければ有意になるようにしたければ、そのようにサンプルサイズ を小さめに決めれば良い テキストの「新しく開発されたダイエット食品」の例 要は「何と何のトレードオフなら取れるか」でしかない 2014/2/20 40
41.
Cohen’s dなど「Cohenのeffect size」とは? Jacob
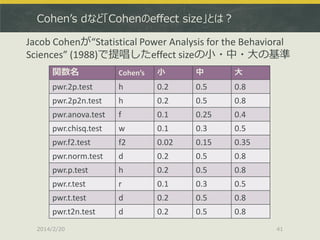
Cohenが“Statistical Power Analysis for the Behavioral Sciences” (1988)で提唱したeffect sizeの小・中・大の基準 関数名 Cohen’s 小 中 大 pwr.2p.test h 0.2 0.5 0.8 pwr.2p2n.test h 0.2 0.5 0.8 pwr.anova.test f 0.1 0.25 0.4 pwr.chisq.test w 0.1 0.3 0.5 pwr.f2.test f2 0.02 0.15 0.35 pwr.norm.test d 0.2 0.5 0.8 pwr.p.test h 0.2 0.5 0.8 pwr.r.test r 0.1 0.3 0.5 pwr.t.test d 0.2 0.5 0.8 pwr.t2n.test d 0.2 0.5 0.8 2014/2/20 41
42.
t検定のサンプルサイズを求める > pwr.t.test(n=NULL,d=0.5,sig.level=0.05,power=0.8) # Cohen’s
d = 0.5(中)で固定 Two-sample t test power calculation n = 63.76561 # n = 64が必要ということ d = 0.5 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group 2014/2/20 42
43.
t検定のサンプルサイズを求める > pwr.t.test(n=NULL,d=0.8,sig.level=0.05,power=0.8) # Cohen’s
d = 0.8(大)に上げてみた Two-sample t test power calculation n = 25.52457 # n = 26と、小さいサンプルサイズに d = 0.8 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group 2014/2/20 43
44.
cohen.ES関数でeffect sizeを呼び出す 実はcohen.ES関数で、Cohenが提唱した小・中・大 それぞれのeffect sizeの値を呼び出すことができる >
cohen.ES(test=“t”,size=“medium”) # t検定の「中」 Conventional effect size from Cohen (1982) test = t size = medium effect.size = 0.5 > cohen.ES(test=“anov”,size=“large”) # ANOVAの「大」 Conventional effect size from Cohen (1982) test = anov size = large effect.size = 0.4 2014/2/20 44
45.
ややこしい例(1): ANOVA > pwr.anova.test(n=NULL,f=0.25,k=5,sig.level=0.05,power=0.8) Balanced
one-way analysis of variance power calculation k = 5 # 群の数 n = 39.1534 # 群ごとのサンプルサイズ f = 0.25 sig.level = 0.05 power = 0.8 NOTE: n is number in each group 2014/2/20 45
46.
ややこしい例(2): 一般化線形モデル > pwr.f2.test(u=4,v=NULL,f2=0.35,sig.level=0.05,power=0.8) #
一般化線形モデルについては与える引数が独特 # u: 説明変数側の自由度, v: 目的変数側の自由度 Multiple regression power calculation u = 4 # 「説明変数の自由度を」4に固定 v = 34.14884 # 「目的変数の自由度が」35以上 f2 = 0.35 sig.level = 0.05 power = 0.8 2014/2/20 46
47.
おまけ:直接effect sizeを Rで求める方法(dのみ) 2014/2/20 47
48.
Stack Overflowに出ていたやり方(2群のt検定) > set.seed(45)
# 単に再現性を出すため > x <- rnorm(10, 10, 1) > y <- rnorm(10, 5, 5) > > cohens_d <- function(x, y) { + lx <- length(x)- 1 + ly <- length(y)- 1 + md <- abs(mean(x) - mean(y)) # 平均値の差 + csd <- lx * var(x) + ly * var(y) + csd <- csd/(lx + ly) + csd <- sqrt(csd) # Common error varianceはこれで出せる + + cd <- md/csd # これでCohen’s dが求まる +} > res <- cohens_d(x, y) > res [1] 0.5199662 # 0.5はCohen’s dとしては結構デカい方 2014/2/20 48
49.
今回語り尽くせなかったところは… ブログで補足記事を書くかも?(期待しないでください) 2014/2/20 49






![端的に言えば
1.対立仮説が真である時に
2.帰無仮説が棄却される確率
= P([帰無仮説を棄却] | [対立仮説が真])
2014/2/20
8](https://image.slidesharecdn.com/tokyor140222tjo-140222013533-phpapp02/85/R-20-8-320.jpg)












![とりあえずベタっとやってみる
> tval<-numeric(length=10000)
# t値を格納する変数
> count_sig<-0
# 有意な結果を返す検定の総回数
> for (i in 1:10000) { # 10000回のモンテカルロシミュレーション
+ # 母集団を以下の通りサンプルサイズn = 10で2つ定める
+ group1<-rnorm(n=10,mean=0,sd=1) # 平均0、標準偏差1
+ group2<-rnorm(n=10,mean=0.5,sd=1) # 平均0.5、標準偏差1
+ res<-t.test(group1,group2,var.equal=T) # 結果を一時格納
+ tval[i]<-res[[1]] # t値そのものを格納する
+ count_sig<-count_sig+ifelse(res[[3]]<0.05,1,0) # 有意ならカウント
+}
> count_sig/10000 # 最終的に有意だった割合=検定力は?
[1] 0.1849 # サンプルサイズ10の時の検定力は0.185ぐらい
2014/2/20
21](https://image.slidesharecdn.com/tokyor140222tjo-140222013533-phpapp02/85/R-20-21-320.jpg)

![一旦こいつから棄却域を出してみる
> qt(0.025,df=18) # 下側5%棄却域
[1] -2.100922
> qt(0.025,df=18,lower.tail=F) # 上側5%棄却域
[1] 2.100922
> length(tval[abs(tval)>qt(0.025,df=18,lower.tail=F)]) # 棄却域の値を出す
[1] 1849
> count_sig
[1] 1849 # 上の値と一致してますね!
2014/2/20
25](https://image.slidesharecdn.com/tokyor140222tjo-140222013533-phpapp02/85/R-20-25-320.jpg)


















![Stack Overflowに出ていたやり方(2群のt検定)
> set.seed(45) # 単に再現性を出すため
> x <- rnorm(10, 10, 1)
> y <- rnorm(10, 5, 5)
>
> cohens_d <- function(x, y) {
+ lx <- length(x)- 1
+ ly <- length(y)- 1
+ md <- abs(mean(x) - mean(y)) # 平均値の差
+ csd <- lx * var(x) + ly * var(y)
+ csd <- csd/(lx + ly)
+ csd <- sqrt(csd) # Common error varianceはこれで出せる
+
+ cd <- md/csd # これでCohen’s dが求まる
+}
> res <- cohens_d(x, y)
> res
[1] 0.5199662 # 0.5はCohen’s dとしては結構デカい方
2014/2/20
48](https://image.slidesharecdn.com/tokyor140222tjo-140222013533-phpapp02/85/R-20-48-320.jpg)