Master (Driver) に負荷を掛けない
• RDD のcollect メソッドは,RDD をScala のコレクションに変換
• 巨大なデータを集約しようとするとDriver が動いているマシ
ンのメモリに乗り切らない
• データを確認したいときは,take() やtakeSample()
• 同様の理由で,countByKey(), countByValue(), collectAsMap()
でも気をつける
19
Don't copy all elements of a large RDD to the driver!!
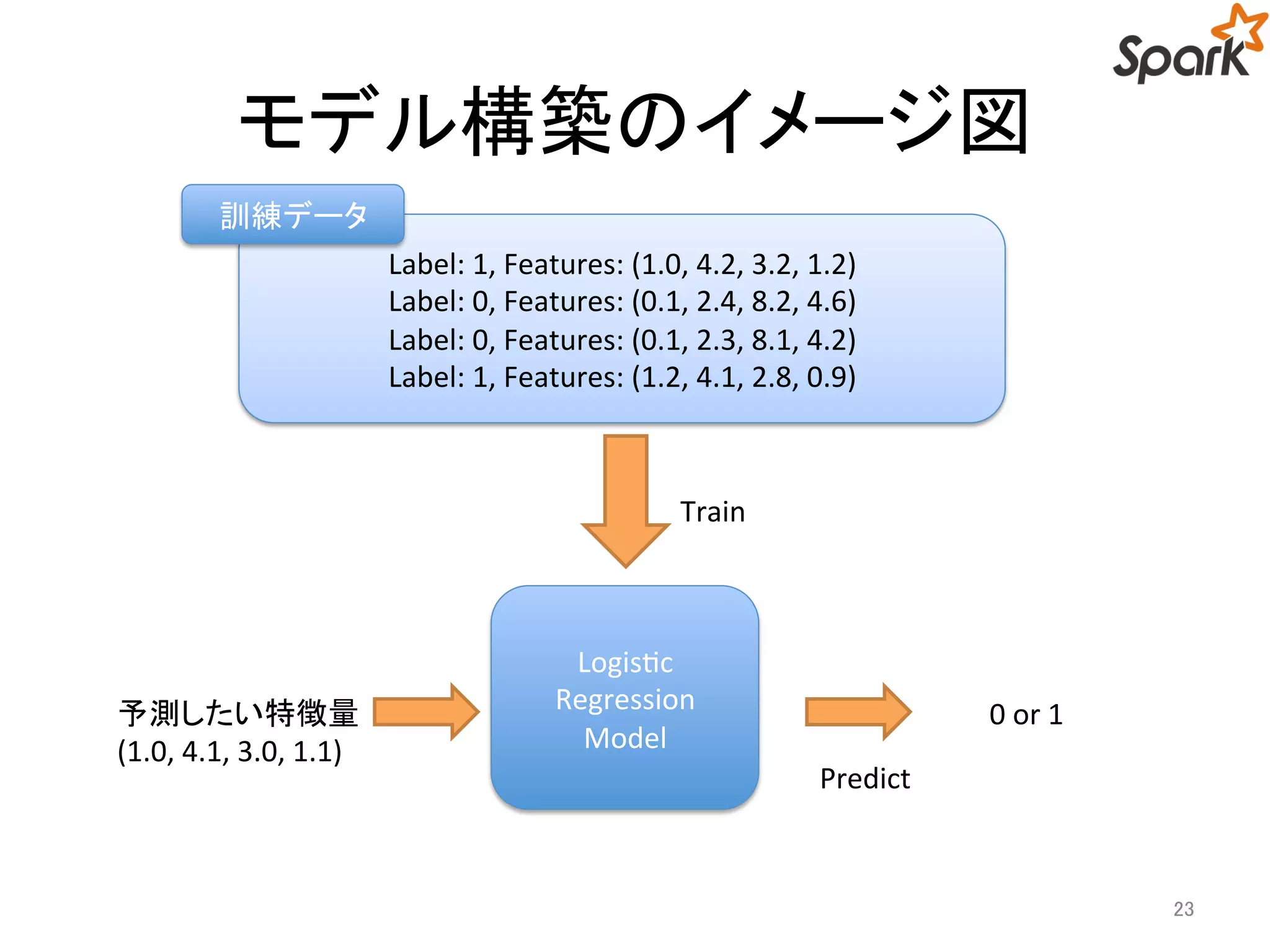
二項分類器の評価方法
• Sparkは二項分類器を評価するためのクラスがある
– BinaryClassificationMetrics
• BinaryClassificationMetrics で算出できる値
– Area Under the ROC curve
• 最大値:1のときがモデルとして最も良い
• 最悪値は0.5 のときで,ランダムな判別を行ったときと同じ
– Area Under the Precision-Recall curve
24
25.
実験概要
25
S3
CSV
7.5GB
Spark Cluster on EC2
3.2GB
parse
duplicate
X30
105.2GB
Test
73.2GB
Train
32GB
2/3
1/3
Evaluation
Logistic
Regression
Model
K-分割交差検証(K = 3)
利用したデータ
• 利用元
– Baldi, P., P. Sadowski, and D. Whiteson. “Searching for Exotic Particles in High-energy
Physics with Deep Learning.” Nature Communications 5 (July 2, 2014)
– http://archive.ics.uci.edu/ml/datasets/HIGGS
• 二項分類のデータ
• データサイズ:7.5GB
• レコード数:11000000
• Number of Attributes:28
• Sample Data:(指数表現されている…)
27
28.
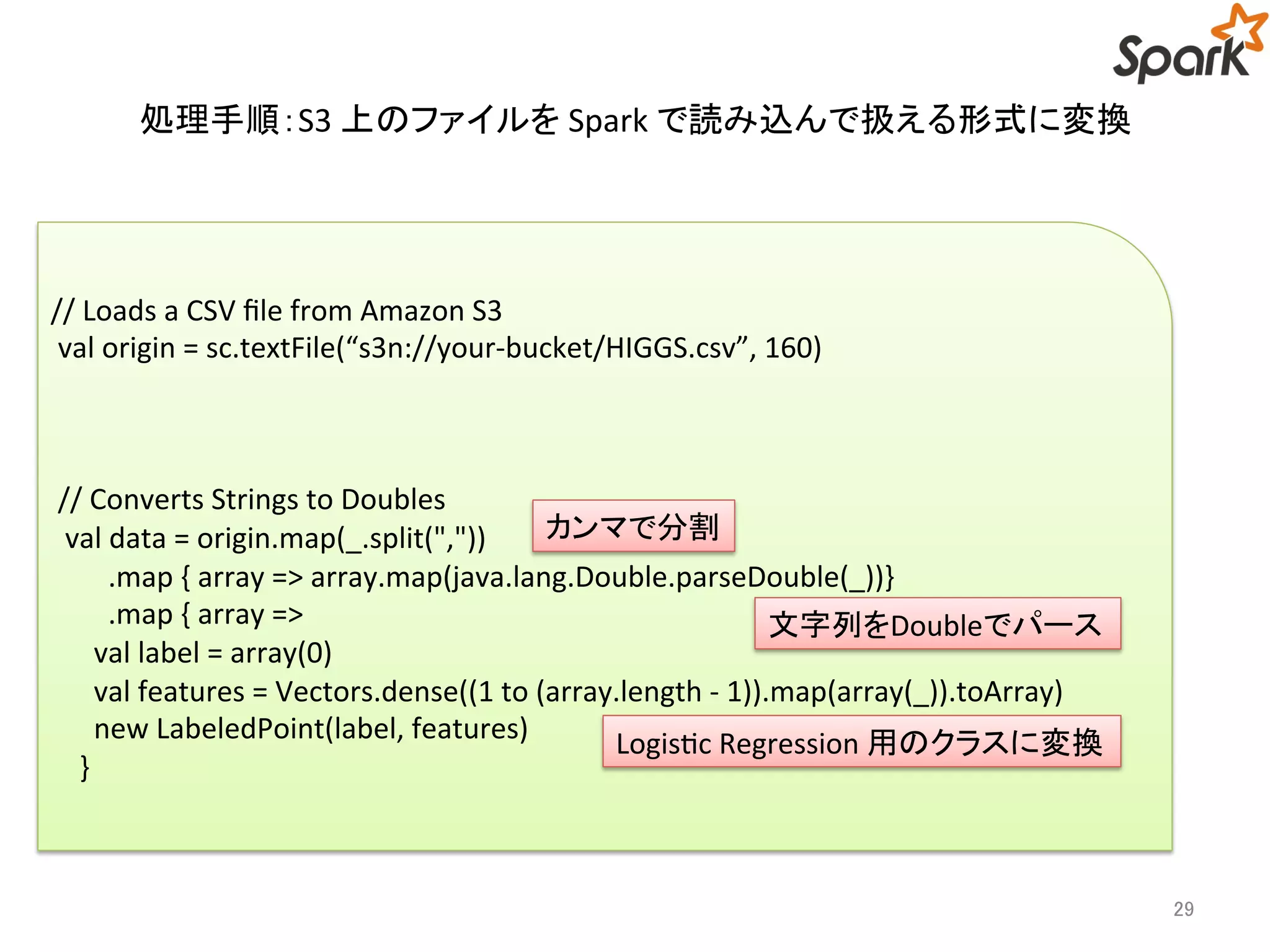
処理手順の概要
1. S3上のファイルをSpark で読み込んで扱える形式に変換
2. デモ用にレコード数を30倍に増やす
3. (K-分割交差検証で)Logistic Regression のモデルを構築
4. 訓練したモデルにテストデータを当てはめて正解率とArea
Under the ROC curve を算出
28
29.
処理手順:S3 上のファイルをSpark で読み込んで扱える形式に変換
29
// Loads a CSV file from Amazon S3
val origin = sc.textFile(“s3n://your-bucket/HIGGS.csv”, 160)
// Converts Strings to Doubles
val data = origin.map(_.split(","))
カンマで分割
.map { array => array.map(java.lang.Double.parseDouble(_))}
.map { array =>
val label = array(0)
val features = Vectors.dense((1 to (array.length - 1)).map(array(_)).toArray)
new LabeledPoint(label, features)
}
文字列をDoubleでパース
Logistic Regression 用のクラスに変換
30.
処理手順:デモ用にレコード数を30倍に増やす
• flatMap()を利用することでデータ量をコントロール
できる
– (Scala) List(0,1,2).flatMap(n => List(n,'A'+n))
– List(0, 65, 1, 66, 2, 67)
全く同じデータにならないように1% ランダム誤差を加える
30
data.flatMap { point =>
(1 to 30).map { i =>
val newFeatures = point.features.toArray.map(x => x + (0.01 * math.random * x))
new LabeledPoint(point.label, Vectors.dense(newFeatures))
}
}
31.
処理手順:K-分割交差検証(K = 3)でLogisticRegression のモデルを構築
(予測ラベル,正解ラベル)のタプルのRDD を作成
31
// Attaches index number to each record
val indexed = data.zipWithIndex().map { case (lp, idx) => (lp, idx % 3)}
// Extracts the training data
val fit = indexed.filter { case (lp, idx) => idx % 3== 0}.map { case (lp, idx) => lp}
// Extracts the test data
val test= indexed.filter {case (lp, idx) => idx % 3!= 0}.map {case (lp, idx) => lp}
// Trains a model
val model = LogisticRegressionWithSGD.train(fit, subIterations = 100)
// Predicts the test data
val predicted = test.map { point =>
val predictedLabel = model.predict(point.features)
(predictedLabel, point.label)
}
32.
処理手順:訓練したモデルにテストデータを当てはめて正解率とAUC を算出
32
// Calculates a accuracy ratio
val correct = predicted.filter { case (p, l) => p == l}.count / predict.count.toDouble
println(s"Correct Ratio: ${correct}")
// Calculates a Area Under the Curve
val metric = new BinaryClassificationMetrics(predicted)
println(s"AUC: ${metric.areaUnderROC()}")
2値分類器を評価するためのクラス






![Cacheとは?
• クラスタ横断でメモリ上に処理データをキャッシュす
ることができる
• 繰り返し「再利用される」データに活用すると効率的
に処理できる
• 11000000 レコードのデータのカウント(160 cores)
– キャッシュなし:7.48 [sec]
– キャッシュあり:0.40 [sec]
10
Spark はCache の活用次第でパフォーマンスが
大幅に変化するので注意!](https://image.slidesharecdn.com/2014-11-20sparkmllibeventslideshare-141120043231-conversion-gate02/75/2014-11-20-Machine-Learning-with-Apache-Spark-10-2048.jpg)








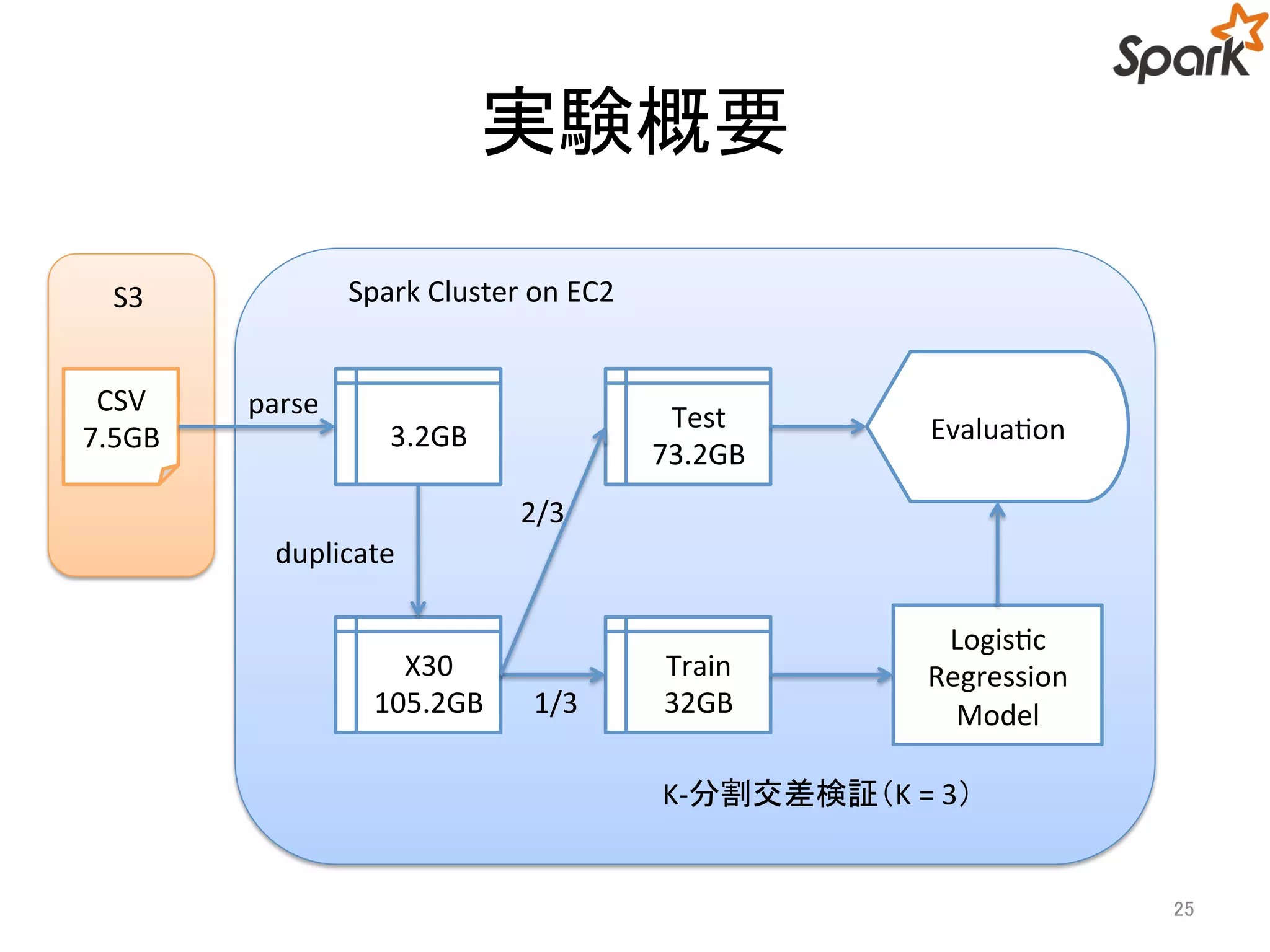






![実験に用いた条件と結果
• 実験に用いたデータ
– 全体:330,000,000 レコード(105.2GB)
– 1回の訓練データ:110000000 レコード(32 GB)
– 1回のテストデータ:220000000 レコード(73.2GB)
• 実験に利用したパラメータ
– numIterations: 100
• 処理時間
– 平均訓練時間:75.9[sec]
– 平均テスト時間:10^-4[sec]
• 評価
それほど良い結果が得
– 平均正解率:0.61
– 平均Area Under the ROC curve: 0.60
33
られなかったが…
処理速い!](https://image.slidesharecdn.com/2014-11-20sparkmllibeventslideshare-141120043231-conversion-gate02/75/2014-11-20-Machine-Learning-with-Apache-Spark-33-2048.jpg)


![Spark 1.2 MLlib で注目のissue
• [SPARK-3530] Pipeline and Parameters
– scikit-learn の`fit`, `predict` のような一貫性API に向けた取り組み
– 各アルゴリズムの対応は1.3 以降のマイルストーンになると思われる
– [SPARK-1856] Standardize MLlib interfaces が1.3 のマイルストーン
• [SPARK-1545] Add Random Forest algorithm to Mllib
– Decision Tree に,ようやくRandom Forest が追加
– 通常のDecision Tree はRandom Forest のnumTree = 1 で実装
• [SPARK-3486] Add PySpark support for Word2Vec
– 1.1 系のSpark のWord2Vec はスケールしにくいし,機能として不十
分
– 1.2 系以降で処理の改善と機能拡充が期待
36](https://image.slidesharecdn.com/2014-11-20sparkmllibeventslideshare-141120043231-conversion-gate02/75/2014-11-20-Machine-Learning-with-Apache-Spark-36-2048.jpg)
![[SPARK-3530] Pipeline and Parameters
• 簡単にデータの処理フローを定義できる
– ノーマライズ
– 主成分分析による次元圧縮
– LogisticRegression
37](https://image.slidesharecdn.com/2014-11-20sparkmllibeventslideshare-141120043231-conversion-gate02/75/2014-11-20-Machine-Learning-with-Apache-Spark-37-2048.jpg)


















































![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)




























