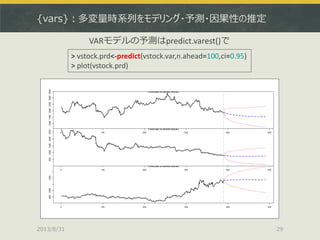
{fGarch}:「ばらつき」の時系列モデリング
2013/8/31 47
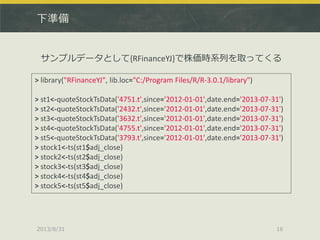
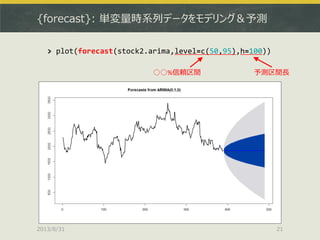
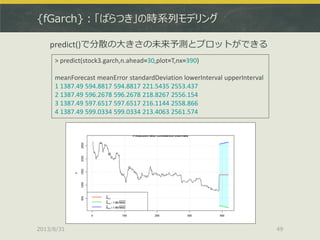
> stock3.garch<-garchFit(~garch(1,1),data=stock3,trace=F)
>plot(stock3.garch)
Make a plot selection (or 0 to exit):
1: Time Series
2: Conditional SD
3: Series with 2 Conditional SD Superimposed
4: ACF of Observations
5: ACF of Squared Observations
6: Cross Correlation
7: Residuals
8: Conditional SDs
9: Standardized Residuals
10: ACF of Standardized Residuals
11: ACF of Squared Standardized Residuals
12: Cross Correlation between r^2 and r
13: QQ-Plot of Standardized Residuals
Selection: 2
garchFit()でGARCHモデルを推定、plot()で詳細を可視化できる




















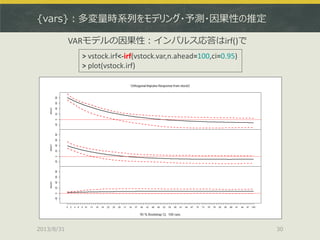




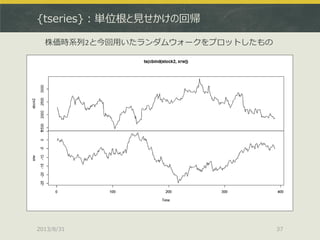



![{urca}:共和分関係のモデリング
2013/8/31 41
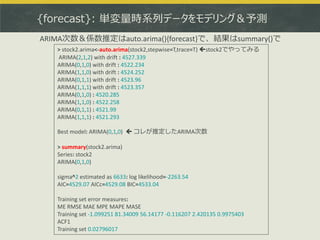
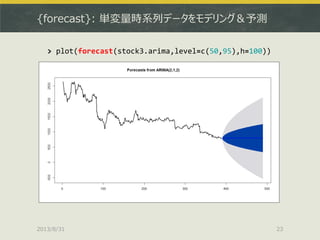
> data(finland)
> sjf <- finland
> sjf.vecm <- ca.jo(sjf, ecdet = "none", type="eigen", K=2, spec="longrun", season=4)
> summary(sjf.vecm)
######################
# Johansen-Procedure #
######################
Test type: maximal eigenvalue statistic (lambda max) , with linear trend
Eigenvalues (lambda):
[1] 0.30932660 0.22599561 0.07308056 0.02946699
Values of teststatistic and critical values of test:
test 10pct 5pct 1pct
r <= 3 | 3.11 6.50 8.18 11.65
r <= 2 | 7.89 12.91 14.90 19.19 ここは5%棄却域を割っている
r <= 1 | 26.64 18.90 21.07 25.75 ここは5%棄却域を超えている(つまりr = 2)
r = 0 | 38.49 24.78 27.14 32.14
(以下省略)
共和分関係の推定はca.jo()で、共和分ランクの確認はsummary()で](https://image.slidesharecdn.com/tokyor130831tjo-130831002426-phpapp02/85/R-CRAN-41-320.jpg)






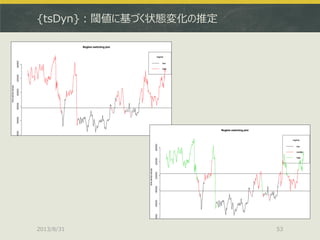
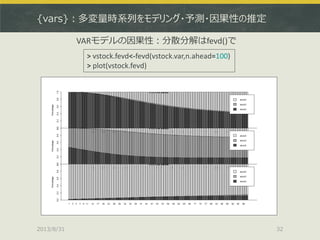
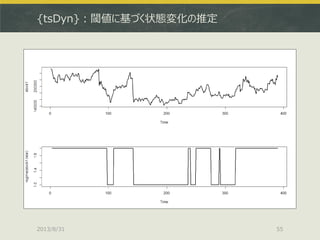
![{tsDyn}:閾値に基づく状態変化の推定
2013/8/31 54
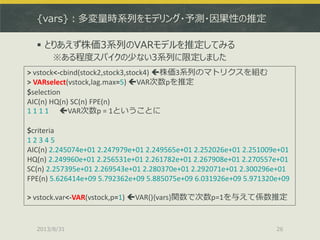
> stock1.lstar<-lstar(stock1,m=2) # AR次数は2
Using maximum autoregressive order for low regime: mL = 2
Using maximum autoregressive order for high regime: mH = 2
Using default threshold variable: thDelay=0
Performing grid search for starting values...
Starting values fixed: gamma = 100 , th = 178026 ; SSE = 16511207226
Grid search selected lower/upper bound gamma (was: 1 100 ]).
Might try to widen bound with arg: 'starting.control=list(gammaInt=c(1,200))'
Optimization algorithm converged
Problem: singular hessian
Optimized values fixed for regime 2 : gamma = 100 , th = 178026 ; SSE = 16511207226
> par(mfrow=c(2,1))
> plot(stock1)
> plot(regime(stock1.lstar)) # レジームをプロット
LSTARモデルの推定はlstar()で、まとめてAR次数を与える](https://image.slidesharecdn.com/tokyor130831tjo-130831002426-phpapp02/85/R-CRAN-54-320.jpg)



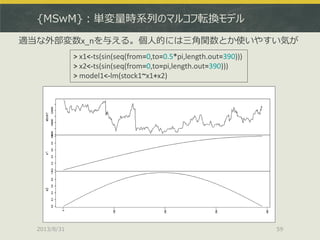
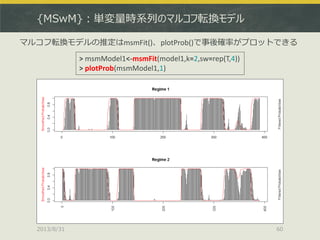
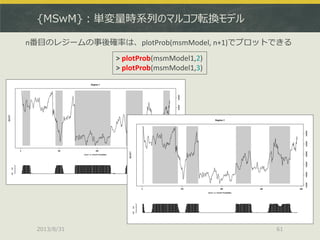



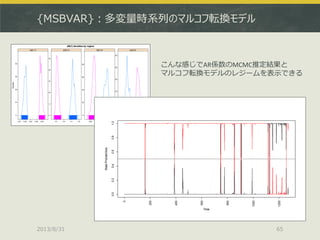
























![[DL輪読会]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=640&height=640&fit=bounds)








































