reporting guideline
Mueller, R.O., & Hancock, G. R. (2008). Structural
Equation Modeling. In G. R., Hancock & R. O. Mueller
(Eds.), The Reviewer’s Guide to Quantitative Methods in
the Social Sciences. (pp. 281-288) New York: Routledge.
ガイドの編者!!
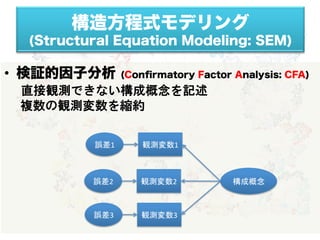
7.
項目
テーマ
セクション
1
仮説モデル•競合モデルの構築
I
2
パス図の呈示
I
3
潜在変数の定義
I
(M)
4
観測変数の定義
M
5
潜在変数に対する観測変数の数
M
6
統制変数の扱い
M
7
サンプリング法•サンプル数
M
8
欠損データ•外れ値の処理
M,
(R)
9
統計ソフトの情報•推定法の明示
M,
(R)
I = introduction, M = method, R = results, D = discussion
ガイドの項目概要
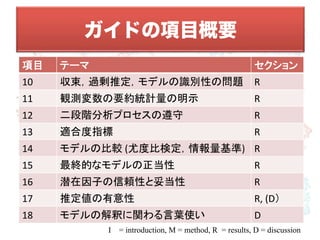
8.
項目
テーマ
セクション
10
収束,過剰推定,モデルの識別性の問題
R
11
観測変数の要約統計量の明示
R
12
二段階分析プロセスの遵守
R
13
適合度指標
R
14
モデルの比較
(尤度比検定,情報量基準)
R
15
最終的なモデルの正当性
R
16
潜在因子の信頼性と妥当性
R
17
推定値の有意性
R,
(D)
18
モデルの解釈に関わる言葉使い
D
I = introduction, M = method, R = results, D = discussion
ガイドの項目概要
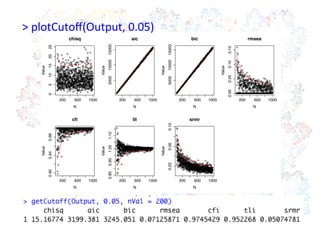
200 600 1000
0510152025
chisq
N
Value
200600 1000
50001000015000
aic
N
Value
200 600 1000
50001000015000
bic
N
Value
200 600 1000
0.000.050.100.15
rmsea
N
Value
200 600 1000
0.900.940.98
cfi
N
Value
200 600 1000
0.800.901.001.10
tli
N
Value
200 600 1000
0.020.060.10
srmr
N
Value
>
plotCutoff(Output,
0.05)
31.
>
Cpow
<-‐
getPower(Output)
>
findPower(Cpow,
”N”,
0.80)
>
plotPower(Output,
powerParam=c("f1=~y1",
"f1~~f2"))
200 400 600 800
0.00.20.40.60.81.0
f1=~y1
N
Power
200 400 600 800
0.00.20.40.60.81.0
f1~~f2
N
Power
32.
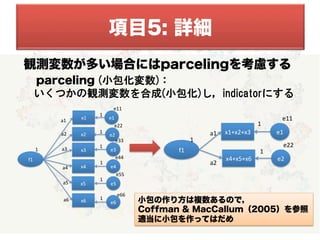
• 欠損値や外れ値の処理の仕方が述べられている
> 処理方法と欠損割合を報告する
>推奨される欠損値処理
a)
完全情報最尤推定法
(Mplus•Lavaanはデフォルト)
b)
多重代入法
(詳細は第3回DARM資料を参照)
※平均値代入
or
リスト(ペア)ワイズ削除はだめ
> はずれ値の処理
単変量: 通常zscoreの±3
多変量: mahalanobisの距離(D2)で判定
⇒ D2<.001を削除
•
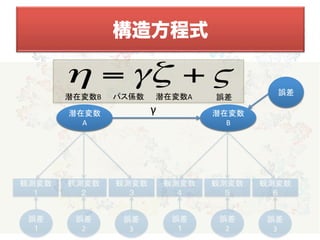
項目8: 詳細
a) 収束の問題:デフォルトの反復回数で収束しない
対処⇒反復回数を増やす
b) ヘイウッドケース: 誤差分散が0 or 負の値をとる
対処①
:誤差分散が負の値をとる変数を分析から除外する
対処②
誤差分散を0に固定
対処③
ADF推定法を用いる
c) not positive definite
(相関行列に1以上の値が含まれる)
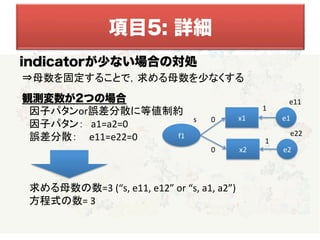
項目10: 詳細
収束,過剰推定,モデルの識別性に関
わる問題が報告され,議論されている
37.
行列内に1以上の値が含まれる
問題の原因となる行列
①
標本共分散
(相関)行列
②
情報行列
③
推定のための重み行列
④
モデルから構成される共分散行列
⑤
母数行列
(←問題なし)
Task
1.000
Rela,ons
.937
1.000
Management
.908
.906
1.000
Auribute
.985
1.010
.951
1.000
not positive definite





























































![心理学者のためのJASP入門(操作編)[説明文をよんでください]](https://cdn.slidesharecdn.com/ss_thumbnails/test-180307053956-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)














































