Recommended
PDF
PDF
データベース屋がHyperledger Fabricを検証してみた
PPTX
PDF
PDF
Deconstruction of Serverless and blockchain
PPTX
PPTX
デジタルハリウッド大学院 ブロックチェーン研究会第三回 2016年8月25日
PPTX
PDF
PDF
PPTX
JavaScriptで加速度・回転情報を取得してみた
PPTX
PDF
PDF
PPTX
DOC
PPTX
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
PDF
直感的な単変量モデルでは予測できない「ワインの味」を多変量モデルで予測する
PDF
Visualization of Supervised Learning with {arules} + {arulesViz}
PDF
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
PDF
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
PDF
PDF
Granger因果による�時系列データの因果推定(因果フェス2015)
PDF
最新業界事情から見るデータサイエンティストの「実像」
PPTX
PDF
データ分析というお仕事のこれまでとこれから(HCMPL2014)
PDF
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
PDF
Taste of Wine vs. Data Science
PPTX
21世紀で最もセクシーな職業!?「データサイエンティスト」の実像に迫る
More Related Content
PDF
PDF
データベース屋がHyperledger Fabricを検証してみた
PPTX
PDF
PDF
Deconstruction of Serverless and blockchain
PPTX
PPTX
デジタルハリウッド大学院 ブロックチェーン研究会第三回 2016年8月25日
PPTX
What's hot
PDF
PDF
PPTX
JavaScriptで加速度・回転情報を取得してみた
PPTX
PDF
PDF
PPTX
DOC
PPTX
Viewers also liked
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
PDF
直感的な単変量モデルでは予測できない「ワインの味」を多変量モデルで予測する
PDF
Visualization of Supervised Learning with {arules} + {arulesViz}
PDF
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
PDF
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
PDF
PDF
Granger因果による�時系列データの因果推定(因果フェス2015)
PDF
最新業界事情から見るデータサイエンティストの「実像」
PPTX
PDF
データ分析というお仕事のこれまでとこれから(HCMPL2014)
PDF
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
PDF
Taste of Wine vs. Data Science
PPTX
21世紀で最もセクシーな職業!?「データサイエンティスト」の実像に迫る
PDF
数式を綺麗にプログラミングするコツ #spro2013
PDF
PDF
WI2研究会(公開用) “データ分析でよく使う前処理の整理と対処”
PDF
なぜ統計学がビジネスの 意思決定において大事なのか?
PDF
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
PDF
時系列解析の使い方 - TokyoWebMining #17
PDF
Tech Lab Paak講演会 20150601
Jc 20141003 tjo 1. 2. A Hazard Based Approach to User Return Time Prediction
Kapoor, Sun, Srivastrava, and Ye,
Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining,
pp. 1719-1728, 2014
http://dl.acm.org/citation.cfm?id=2623348 3. 4. 5. 6. 7. 11. 手法
•要するにCoxの比例ハザードモデル
–Censored dataの扱いの話もRecurrent observationsの話も全部そこで扱われている
–Statusとかの変数を入れる話も出てくる
–※ならESLとか引用すればいいのに
•一応式を挙げておく
–ちなみに打ち切り状態とかも説明変数(共変量) に入れられるセミパラメトリックモデル 12. 13. 変数設定
•目的変数
–時間(days) or クラス(Last.fmデータセットでは7日以内orそ れ以上、大規模データセットでは30日以内orそれ以上)
•説明変数(共変量)
–Typical visitation patternsに関連するもの
•Active weeks, Density of Visitation, Visit number, Previous gap, Time weighted average return time
–User satisfaction / engagementに関連するもの
•Duration, % Distinct Songs, % Distinct Artists, % Skips, Explicit feedback indicators (ratings, comments, complaints etc.)
–その他外部要因に関連するもの
•週末、休日、Last.fmのキャンペーン・プロモ etc. 14. 評価
•他手法でもやってみた
–単純平均(これがベンチマーク)、線形回帰モデル、回帰 木、線形SVM、ニューラルネット
•この辺はRではなくWekaで実施
–SVRはデータが重過ぎて回らなかったので断念
•評価軸は以下の通り
–Weighted RMSE
–Weighted Precision
–Weighted Recall
•LOA (Length of Absence)を変化させた時の各評価指標
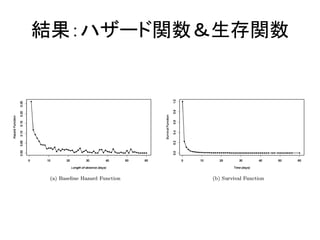
–これがハザードモデルの場合は影響が大きいので 15. 結果:計算負荷
•Return time予測モデル(のCV)
–Coxのハザードモデル:8分
–NN:16分
–回帰木:4分
–線形回帰:26秒
–単純平均:20秒
•Return timeのクラス分類(のCV)
–Coxのハザードモデル:8分
–NN:15分
–SVM:24分
–ランダムフォレスト:6分
•全てXeon CPU X5650 / 2.67GHz, 24GHzで計算 16. 17. 18. 19. 20. 21. 22. 23. 24. 感想
•こんなんで(Industrial & Govtとはいえ)KDDに 採択されるんか。。。
•でもreturn timeってソシャゲでも結構面倒な 話だったので意外と使えるネタな気がする
•というか「時間長」の概念はもっと積極的に 使ってもいいのかもしれない