Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kazuaki Tanida
PDF, PPTX
3,242 views
画像認識で物を見分ける
Pythonで動かして学ぶ機械学習入門 第二回 Jupyter Notebooks: https://goo.gl/U7bglf
Engineering
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
論文紹介:A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, a...
by
Toru Tamaki
PDF
PCL
by
Masafumi Noda
PDF
深層学習とベイズ統計
by
Yuta Kashino
PDF
Introduction to YOLO detection model
by
WEBFARMER. ltd.
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
【DL輪読会】GAN-Supervised Dense Visual Alignment (CVPR 2022)
by
Deep Learning JP
PPTX
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
PPTX
深層強化学習による自動運転車両の経路探索に関する研究
by
harmonylab
論文紹介:A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, a...
by
Toru Tamaki
PCL
by
Masafumi Noda
深層学習とベイズ統計
by
Yuta Kashino
Introduction to YOLO detection model
by
WEBFARMER. ltd.
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
【DL輪読会】GAN-Supervised Dense Visual Alignment (CVPR 2022)
by
Deep Learning JP
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
深層強化学習による自動運転車両の経路探索に関する研究
by
harmonylab
What's hot
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
by
HironoriKanazawa
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
PDF
ディープラーニングでラーメン二郎(全店舗)を識別してみた
by
knjcode
PDF
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
PDF
LiDARとSensor Fusion
by
Satoshi Tanaka
PDF
自然言語処理のためのDeep Learning
by
Yuta Kikuchi
PDF
G2o
by
Fujimoto Keisuke
PDF
SSII2020 [O3-01] Extreme 3D センシング
by
SSII
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
PPTX
LSD-SLAM:Large Scale Direct Monocular SLAM
by
EndoYuuki
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PPTX
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
PPTX
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PDF
Inverse Reward Design の紹介
by
Chihiro Kusunoki
PPTX
[DL輪読会]SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving
by
Deep Learning JP
PDF
コンピュータビジョン分野メジャー国際会議 Award までの道のり
by
cvpaper. challenge
ODP
PRML勉強会 #4 @筑波大学 発表スライド
by
Satoshi Yoshikawa
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
物体検出の歴史(R-CNNからSSD・YOLOまで)
by
HironoriKanazawa
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
ディープラーニングでラーメン二郎(全店舗)を識別してみた
by
knjcode
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
LiDARとSensor Fusion
by
Satoshi Tanaka
自然言語処理のためのDeep Learning
by
Yuta Kikuchi
G2o
by
Fujimoto Keisuke
SSII2020 [O3-01] Extreme 3D センシング
by
SSII
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
LSD-SLAM:Large Scale Direct Monocular SLAM
by
EndoYuuki
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
Inverse Reward Design の紹介
by
Chihiro Kusunoki
[DL輪読会]SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving
by
Deep Learning JP
コンピュータビジョン分野メジャー国際会議 Award までの道のり
by
cvpaper. challenge
PRML勉強会 #4 @筑波大学 発表スライド
by
Satoshi Yoshikawa
[DL輪読会]Objects as Points
by
Deep Learning JP
Similar to 画像認識で物を見分ける
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
PDF
Opencv object detection_takmin
by
Takuya Minagawa
PDF
画像処理でのPythonの利用
by
Yasutomo Kawanishi
PPTX
[機械学習]文章のクラス分類
by
Tetsuya Hasegawa
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PPTX
深層学習を用いたバス乗客画像の属性推定 に関する研究
by
harmonylab
PPTX
2015年12月PRMU研究会 対応点探索のための特徴量表現
by
Mitsuru Ambai
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
PDF
大規模画像認識とその周辺
by
n_hidekey
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
CVPR 2011 ImageNet Challenge 文献紹介
by
Narihira Takuya
PDF
コンピュータビジョン7章資料_20140830読書会
by
Nao Oec
PDF
ICCV2011 report
by
Hironobu Fujiyoshi
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
PPTX
R -> Python
by
Kazufumi Ohkawa
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
20110904cvsaisentan(shirasy) 3 4_3
by
Yoichi Shirasawa
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
Opencv object detection_takmin
by
Takuya Minagawa
画像処理でのPythonの利用
by
Yasutomo Kawanishi
[機械学習]文章のクラス分類
by
Tetsuya Hasegawa
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
深層学習を用いたバス乗客画像の属性推定 に関する研究
by
harmonylab
2015年12月PRMU研究会 対応点探索のための特徴量表現
by
Mitsuru Ambai
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
大規模画像認識とその周辺
by
n_hidekey
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
CVPR 2011 ImageNet Challenge 文献紹介
by
Narihira Takuya
コンピュータビジョン7章資料_20140830読書会
by
Nao Oec
ICCV2011 report
by
Hironobu Fujiyoshi
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
R -> Python
by
Kazufumi Ohkawa
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
20110904cvsaisentan(shirasy) 3 4_3
by
Yoichi Shirasawa
画像認識で物を見分ける
1.
画像認識で物を見分ける Pythonで動かして学ぶ機械学習入門 第二回 谷田和章
2.
自己紹介 ● 谷田和章 (たにだかずあき) ○
GitHub: slaypni ● ソフトウェアエンジニア (フリーランス&白ヤギコーポレーション ) ○ 機械学習, 自然言語処理 ○ Web, iOS, Android ● カメリオの機械学習アルゴリズムの開発
3.
今日やること (その1) 手書き数字識別OCRを作る 分類器 推定: 0 推定:
2 推定: 7 推定: 5 これ
4.
今日やること (その2) 写真中の建物を分類する 分類器 notredame louvre eiffel
5.
機械学習を適用する流れ ● やりたいこと: (未知)データのラベルを推定 ●
事前に必要なもの: データと正解ラベル 実験の手順 (概要) 1. データを特徴ベクトルに変換 2. データを学習用とテスト用に分ける 3. 分類器を学習させる 4. テストデータのラベルを推定 5. 推定値と正解から結果を評価 OCRを作りながら各手順を見ていきます
6.
事前に必要なもの: データと正解ラベル ● sklearn.datasetsパッケージ 機械学習を試すのに使えるトイデータ ●
labels変数 正解数字の配列 ● images変数 数字画像の配列 digits = datasets.load_digits() labels = digits['target'] images = digits['images'] images.shape (1797, 8, 8) 1797個の8x8ピクセルのモノクロ画像
7.
1. データを特徴ベクトルに変換 ● X変数 特徴ベクトルの配列 (各行が特徴ベクトルの行列
) n_samples = len(images) X = images.reshape((n_samples, -1)) ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・1797 64 特徴ベクトルの各次元は 元画像の各ピクセルに対応
8.
2. データを学習用とテスト用に分ける ● train_indices変数 学習用データの添字の配列 ●
test_indices変数 テスト用データの添字の配列 train_indices = np.arange(n_samples)[:n_samples//2] test_indices = np.arange(n_samples)[n_samples//2:] 全データ (1797) 学習用 テスト用
9.
3. 分類器を学習させる ● sklearn.svm.SVCクラス SVM(サポートベクトルマシン
)分類器 ● clf変数 SVM分類器のインスタンス ● clf.fit() 学習データと正解ラベルで学習する clf = svm.SVC() clf.fit(X[train_indices], labels[train_indices]) ・・・coef_[9] 分類器 clf 64 ・・・coef_[1] ・・・coef_[0] ・・・ clf.fit()で値をセット
10.
4. テストデータのラベルを推定 ● clf.predict() データのラベルを推定する ●
y_pred変数 推定ラベルの配列 y_pred = clf.predict(X[test_indices]) coef_[9] 分類器 clf 64 coef_[1] coef_[0] x 64 9: 0.76 1: 0.03 0: 0.08 確率 ・・・ ・・・ 特徴ベクトル 9 推定 k(x, clf.coef_) argmax(proba)
11.
5. 推定値と正解から結果を評価 (1/2) ●
sklearn.metrics.confusion_matrix() 混同行列をテキストで返す ● 混同行列 行: 正解ラベル 列: 推定ラベル それぞれ分類された数 print( metrics.confusion_matrix( labels[test_indices], y_pred ) ) [[38 0 0 0 0 50 0 0 0 0] [ 0 50 0 0 0 41 0 0 0 0] [ 0 0 29 0 0 57 0 0 0 0] [ 0 0 0 54 0 37 0 0 0 0] [ 0 0 0 0 27 65 0 0 0 0] [ 0 0 0 0 0 91 0 0 0 0] [ 0 0 0 0 0 58 33 0 0 0] [ 0 0 0 0 0 64 0 25 0 0] [ 0 0 0 0 0 87 0 0 1 0] [ 0 0 0 0 0 84 0 0 0 8]] 正解ラベル = “2” 推定ラベル: “2”: 29個 “5”: 57個
12.
5. 推定値と正解から結果を評価 (2/2) ●
sklearn.metrics.classification_report() 分類性能の主要な指標をテキストで返す ● support 正解ラベル数 ● f1-score recallとprecisionの調和平均。 0から1の値をとる。 とりあえず、これが1に近いほど良い。 ● recall 実際に正であるデータのうち 正と推定されたものの割合。 ● precision 正と推定したデータのうち 実際に正であるものの割合。 print( metrics.classification_report( labels[test_indices], y_pred ) ) precision recall f1-score support 0 1.00 0.43 0.60 88 1 1.00 0.55 0.71 91 2 1.00 0.34 0.50 86 3 1.00 0.59 0.74 91 4 1.00 0.29 0.45 92 5 0.14 1.00 0.25 91 6 1.00 0.36 0.53 91 7 1.00 0.28 0.44 89 8 1.00 0.01 0.02 88 9 1.00 0.09 0.16 92 avg / total 0.91 0.40 0.44 899
13.
分類性能を改善 実験の手順 (再掲) 1. データを特徴ベクトルに変換 2.
データを学習用とテスト用に分ける 3. 分類器を学習させる 4. テストデータのラベルを推定 5. 推定値と正解から結果を評価 変更を考える点 ● 特徴ベクトル (1) ● 使用する分類器 (3) ● 分類器のハイパーパラメータ (3) 今回はこれを変えてみる
14.
グリッドサーチでハイパーパラメータを調整 ● ハイパーパラメータ 分類器の挙動に影響する値。 分類器のコンストラクタに引数として 渡すか、set_params()関数で設定可能。 ● グリッドサーチ 候補値のなかから最適なハイパーパラメータを探索する手法。 ●
sklearn.grid_search.GridSearchCV() fit()で学習する前にグリッドサーチを行う分類器を返す。 引数には、ラップする分類器と候補ハイパーパラメータをとる。 params = { 'gamma': [10 ** i for i in range(-3, 4)] } clf = grid_search.GridSearchCV(svm.SVC(), params) clf.fit(X[train_indices], labels[train_indices]) “gamma”の最適値は大抵1e-3から1e3のあいだ
15.
結果を評価 (1/2) ● 対角成分の値が大きくなっている →
正しく分類できている print( metrics.confusion_matrix( labels[test_indices], y_pred ) ) [[87 0 0 0 1 0 0 0 0 0] [ 0 88 1 0 0 0 0 0 1 1] [ 0 0 85 1 0 0 0 0 0 0] [ 0 0 0 79 0 3 0 4 5 0] [ 0 0 0 0 88 0 0 0 0 4] [ 0 0 0 0 0 88 1 0 0 2] [ 0 1 0 0 0 0 90 0 0 0] [ 0 0 0 0 0 1 0 88 0 0] [ 0 0 0 0 0 0 0 0 88 0] [ 0 0 0 1 0 1 0 0 0 90]]
16.
結果を評価 (2/2) ● f1-scoreが大きくなっている ●
precisionとrecallも共に向上 print( metrics.classification_report( labels[test_indices], y_pred ) ) precision recall f1-score support 0 1.00 0.99 0.99 88 1 0.99 0.97 0.98 91 2 0.99 0.99 0.99 86 3 0.98 0.87 0.92 91 4 0.99 0.96 0.97 92 5 0.95 0.97 0.96 91 6 0.99 0.99 0.99 91 7 0.96 0.99 0.97 89 8 0.94 1.00 0.97 88 9 0.93 0.98 0.95 92 avg / total 0.97 0.97 0.97 899
17.
より難しい問題に分類器を適用 写真中の建物を分類 ● 手書き数字に比べて写真の分類は難しい ○ 構図や日当たりなど同じ対象物でも絵が大きく異なる ●
先ほどの方法をそのまま使っても分類性能が良くない ○ 特徴ベクトルを変えてみる 特徴ベクトルの作りかたを見ていきます 変更を考える点 (再掲) ● 特徴ベクトル ● 使用する分類器 ● 分類器のハイパーパラメータ
18.
使用するデータ ● The Paris
Dataset ○ パリの観光名所の写真、約 6400枚 ○ ラベルは全11種類 ● iter_data() ラベルと画像を返すイテレータ (内容は.ipynbファイルを参照) for (label, data) in islice(iter_data(), 4): plt.imshow(data) plt.title('{} {}'.format(label, data.shape)) plt.axis('off') 684x1024ピクセルのフルカラー画像
19.
特徴ベクトルの種類 ● 各ピクセル値そのまま ○ 先ほどの手書き数字分類で使った方法 ○
良い点: シンプル ○ 悪い点: 風景写真などでは精度が低い ● Bag of Visual Words (BoVW) ○ 今回の写真分類で使う方法 ○ 良い点: 風景写真などでも特徴が表現できる ○ 良い点: 特徴ベクトルの次元数が小さくできる ○ 悪い点: 作るのに時間がかかる 変換 画像 特徴ベクトル
20.
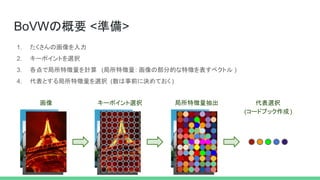
代表選択 (コードブック作成) BoVWの概要 <準備> 1. たくさんの画像を入力 2.
キーポイントを選択 3. 各点で局所特徴量を計算 (局所特徴量: 画像の部分的な特徴を表すベクトル ) 4. 代表とする局所特徴量を選択 (数は事前に決めておく ) キーポイント選択 局所特徴量抽出画像
21.
BoVWの概要 <特徴抽出> 1. 画像を入力 2.
キーポイントを選択 3. 各点で局所特徴量を計算 4. <準備>で選んだ代表特徴量のヒストグラム作成 (最も似てる局所特徴量をカウント ) 5. 特徴ベクトルを出力 (各次元が代表特徴量の頻度 ) キーポイント選択 局所特徴量抽出 ヒストグラム (特徴ベクトル) 画像
22.
HOGによる局所特徴量抽出 HOG (Histograms of
Oriented Gradients) ● 局所特徴量抽出の手法 ● 事前のキーポイント選択は不要 (アルゴリズム内に含まれる) セル毎の勾配を計算画像 局所特徴量(の集合) ・・・
23.
画像から局所特徴量を抽出 ● get_descriptors() 画像を引数に受けとり、 HOG局所特徴量(ベクトル) の配列を返す。 ● skimage.feature.hog() HOG局所特徴量を連結した 一次元の配列を返す。 ●
skimageパッケージ scikit-learnで画像処理を 行うときに便利な機能を提供 def get_descriptors(data): orientations = 9 pixels_per_cell = (8, 8) cells_per_block = (3, 3) feature_vector = hog(rgb2gray(data), orientations, pixels_per_cell, cells_per_block) n_dim = np.multiply(*cells_per_block) * orientations return feature_vector.reshape(-1, n_dim)
24.
コードブックを作成 ● data_descriptors変数 HOG局所特徴量(の配列)の配列。 先ほどのget_descriptors()で作成。 ● sklearn.cluster.MiniBatchKMeansクラス K-means
(ミニバッチ高速版) ● kmeans変数 コードブック codebook_size = 1000 descriptors = np.vstack( data_descriptors[train_indices] ) indices = np.random.choice( np.arange(len(descriptors)), size=500000, replace=False ) kmeans = MiniBatchKMeans( n_clusters=codebook_size, batch_size=1000, n_init=10, random_state=0 ) kmeans.fit( descriptors[indices].astype(float) ) 代表ベクトルの数 学習に使う局所特徴量の数 K-meansでコードブックを作成
25.
K-means クラスタリング手法のひとつ ● 学習 たくさんのベクトルから K個の代表点を抽出 ● 分類 与えられたベクトルを
K個のなかの ひとつのクラスタに分類する 今回はコードブックとして利用
26.
特徴ベクトルを作る ● get_features() HOG局所特徴量(の配列)を引数に受けとり、 画像の特徴ベクトルを返す def get_feature(descriptors): feature
= np.zeros(codebook_size) indices = kmeans.predict( descriptors.astype(float) ) for index in indices: feature[index] += 1 return feature / np.sum(feature) 局所特徴量に最も似た代表ベクトルの添字を取得 代表ベクトルのヒストグラムを計算 各次元の合計値が1になるように正規化
27.
分類性能を評価 (1/2) X =
np.array([get_feature(descriptors) for descriptors in data_descriptors]) clf = SVC() clf.fit( X[train_indices], labels[train_indices] ) y_pred = clf.predict(X[test_indices]) print(metrics.classification_report( labels[test_indices], y_pred )) print(metrics.confusion_matrix( labels[test_indices], y_pred )) [[ 0 59 0 0 0 0 0 0 0 0 0] [ 0 145 0 0 0 0 0 0 0 0 0] [ 0 99 0 0 0 0 0 0 0 0 0] [ 0 76 0 0 0 0 0 0 0 0 0] [ 0 119 0 0 0 0 0 0 0 0 0] [ 0 36 0 0 0 0 0 0 0 0 0] [ 0 60 0 0 0 0 0 0 0 0 0] [ 0 63 0 0 0 0 0 0 0 0 0] [ 0 26 0 0 0 0 0 0 0 0 0] [ 0 75 0 0 0 0 0 0 0 0 0] [ 0 141 0 0 0 0 0 0 0 0 0]] precision recall f1-score support defense 0.00 0.00 0.00 59 eiffel 0.16 1.00 0.28 145 invalides 0.00 0.00 0.00 99 louvre 0.00 0.00 0.00 76 moulinrouge 0.00 0.00 0.00 119 museedorsay 0.00 0.00 0.00 36 notredame 0.00 0.00 0.00 60 pantheon 0.00 0.00 0.00 63 pompidou 0.00 0.00 0.00 26 sacrecoeur 0.00 0.00 0.00 75 triomphe 0.00 0.00 0.00 141 avg / total 0.03 0.16 0.04 899
28.
分類性能を評価 (2/2) params =
{ 'gamma': [10 ** i for i in range(-3, 4)] } clf = grid_search.GridSearchCV( SVC(), params ) clf.fit( X[train_indices], labels[train_indices] ) y_pred = clf.predict(X[test_indices]) [[ 35 7 0 3 1 0 0 1 0 0 12] [ 1 117 1 1 2 0 0 3 0 3 17] [ 1 38 38 2 1 0 0 1 0 10 8] [ 1 15 3 48 1 0 1 0 0 2 5] [ 0 10 3 0 101 0 1 0 0 3 1] [ 0 2 0 0 1 29 0 1 0 2 1] [ 0 5 3 3 0 0 34 1 0 11 3] [ 1 7 3 0 1 0 0 44 0 2 5] [ 0 4 2 0 0 0 0 0 17 0 3] [ 0 14 9 1 2 0 0 2 0 44 3] [ 0 14 3 1 0 0 1 1 0 2 119]] precision recall f1-score support defense 0.90 0.59 0.71 59 eiffel 0.50 0.81 0.62 145 invalides 0.58 0.38 0.46 99 louvre 0.81 0.63 0.71 76 moulinrouge 0.92 0.85 0.88 119 museedorsay 1.00 0.81 0.89 36 notredame 0.92 0.57 0.70 60 pantheon 0.81 0.70 0.75 63 pompidou 1.00 0.65 0.79 26 sacrecoeur 0.56 0.59 0.57 75 triomphe 0.67 0.84 0.75 141 avg / total 0.73 0.70 0.70 899
29.
分類結果
30.
(再掲) BoVWの概要 1. 画像を入力 2.
キーポイントを選択 3. 各点で局所特徴量を計算 4. <準備>で選んだ代表特徴量のヒストグラム作成 (最も似てる局所特徴量をカウント ) 5. 特徴ベクトルを出力 (各次元が代表特徴量の頻度 ) キーポイント選択 局所特徴量抽出 ヒストグラム (特徴ベクトル) 画像
31.
(再掲) 機械学習を適用する流れ ● やりたいこと:
(未知)データのラベルを推定 ● 事前に必要なもの: データと正解ラベル 実験の手順 (概要) 1. データを特徴ベクトルに変換 2. データを学習用とテスト用に分ける 3. 分類器を学習させる 4. テストデータのラベルを推定 5. 推定値と正解から結果を評価
Download





![事前に必要なもの: データと正解ラベル
● sklearn.datasetsパッケージ
機械学習を試すのに使えるトイデータ
● labels変数
正解数字の配列
● images変数
数字画像の配列
digits = datasets.load_digits()
labels = digits['target']
images = digits['images']
images.shape
(1797, 8, 8)
1797個の8x8ピクセルのモノクロ画像](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-6-320.jpg)

![2. データを学習用とテスト用に分ける
● train_indices変数
学習用データの添字の配列
● test_indices変数
テスト用データの添字の配列
train_indices = np.arange(n_samples)[:n_samples//2]
test_indices = np.arange(n_samples)[n_samples//2:]
全データ
(1797)
学習用
テスト用](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-8-320.jpg)
![3. 分類器を学習させる
● sklearn.svm.SVCクラス
SVM(サポートベクトルマシン )分類器
● clf変数
SVM分類器のインスタンス
● clf.fit()
学習データと正解ラベルで学習する
clf = svm.SVC()
clf.fit(X[train_indices], labels[train_indices])
・・・coef_[9]
分類器
clf
64
・・・coef_[1]
・・・coef_[0]
・・・ clf.fit()で値をセット](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-9-320.jpg)
![4. テストデータのラベルを推定
● clf.predict()
データのラベルを推定する
● y_pred変数
推定ラベルの配列
y_pred = clf.predict(X[test_indices])
coef_[9]
分類器 clf
64
coef_[1]
coef_[0]
x
64
9: 0.76
1: 0.03
0: 0.08
確率
・・・ ・・・
特徴ベクトル
9
推定
k(x, clf.coef_) argmax(proba)](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-10-320.jpg)
![5. 推定値と正解から結果を評価 (1/2)
● sklearn.metrics.confusion_matrix()
混同行列をテキストで返す
● 混同行列
行: 正解ラベル
列: 推定ラベル
それぞれ分類された数
print(
metrics.confusion_matrix(
labels[test_indices], y_pred
)
)
[[38 0 0 0 0 50 0 0 0 0]
[ 0 50 0 0 0 41 0 0 0 0]
[ 0 0 29 0 0 57 0 0 0 0]
[ 0 0 0 54 0 37 0 0 0 0]
[ 0 0 0 0 27 65 0 0 0 0]
[ 0 0 0 0 0 91 0 0 0 0]
[ 0 0 0 0 0 58 33 0 0 0]
[ 0 0 0 0 0 64 0 25 0 0]
[ 0 0 0 0 0 87 0 0 1 0]
[ 0 0 0 0 0 84 0 0 0 8]]
正解ラベル = “2”
推定ラベル:
“2”: 29個
“5”: 57個](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-11-320.jpg)
![5. 推定値と正解から結果を評価 (2/2)
● sklearn.metrics.classification_report()
分類性能の主要な指標をテキストで返す
● support
正解ラベル数
● f1-score
recallとprecisionの調和平均。
0から1の値をとる。
とりあえず、これが1に近いほど良い。
● recall
実際に正であるデータのうち
正と推定されたものの割合。
● precision
正と推定したデータのうち
実際に正であるものの割合。
print(
metrics.classification_report(
labels[test_indices], y_pred
)
)
precision recall f1-score support
0 1.00 0.43 0.60 88
1 1.00 0.55 0.71 91
2 1.00 0.34 0.50 86
3 1.00 0.59 0.74 91
4 1.00 0.29 0.45 92
5 0.14 1.00 0.25 91
6 1.00 0.36 0.53 91
7 1.00 0.28 0.44 89
8 1.00 0.01 0.02 88
9 1.00 0.09 0.16 92
avg / total 0.91 0.40 0.44 899](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-12-320.jpg)

![グリッドサーチでハイパーパラメータを調整
● ハイパーパラメータ
分類器の挙動に影響する値。
分類器のコンストラクタに引数として
渡すか、set_params()関数で設定可能。
● グリッドサーチ
候補値のなかから最適なハイパーパラメータを探索する手法。
● sklearn.grid_search.GridSearchCV()
fit()で学習する前にグリッドサーチを行う分類器を返す。
引数には、ラップする分類器と候補ハイパーパラメータをとる。
params = {
'gamma': [10 ** i for i in range(-3, 4)]
}
clf = grid_search.GridSearchCV(svm.SVC(), params)
clf.fit(X[train_indices], labels[train_indices])
“gamma”の最適値は大抵1e-3から1e3のあいだ](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-14-320.jpg)
![結果を評価 (1/2)
● 対角成分の値が大きくなっている
→ 正しく分類できている
print(
metrics.confusion_matrix(
labels[test_indices], y_pred
)
)
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-15-320.jpg)
![結果を評価 (2/2)
● f1-scoreが大きくなっている
● precisionとrecallも共に向上
print(
metrics.classification_report(
labels[test_indices], y_pred
)
)
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
avg / total 0.97 0.97 0.97 899](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-16-320.jpg)






![コードブックを作成
● data_descriptors変数
HOG局所特徴量(の配列)の配列。
先ほどのget_descriptors()で作成。
● sklearn.cluster.MiniBatchKMeansクラス
K-means (ミニバッチ高速版)
● kmeans変数
コードブック
codebook_size = 1000
descriptors = np.vstack(
data_descriptors[train_indices]
)
indices = np.random.choice(
np.arange(len(descriptors)),
size=500000,
replace=False
)
kmeans = MiniBatchKMeans(
n_clusters=codebook_size,
batch_size=1000,
n_init=10,
random_state=0
)
kmeans.fit(
descriptors[indices].astype(float)
)
代表ベクトルの数
学習に使う局所特徴量の数
K-meansでコードブックを作成](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-24-320.jpg)

![特徴ベクトルを作る
● get_features()
HOG局所特徴量(の配列)を引数に受けとり、
画像の特徴ベクトルを返す
def get_feature(descriptors):
feature = np.zeros(codebook_size)
indices = kmeans.predict(
descriptors.astype(float)
)
for index in indices:
feature[index] += 1
return feature / np.sum(feature)
局所特徴量に最も似た代表ベクトルの添字を取得
代表ベクトルのヒストグラムを計算
各次元の合計値が1になるように正規化](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-26-320.jpg)
![分類性能を評価 (1/2)
X = np.array([get_feature(descriptors)
for descriptors
in data_descriptors])
clf = SVC()
clf.fit(
X[train_indices],
labels[train_indices]
)
y_pred = clf.predict(X[test_indices])
print(metrics.classification_report(
labels[test_indices], y_pred
))
print(metrics.confusion_matrix(
labels[test_indices], y_pred
))
[[ 0 59 0 0 0 0 0 0 0 0 0]
[ 0 145 0 0 0 0 0 0 0 0 0]
[ 0 99 0 0 0 0 0 0 0 0 0]
[ 0 76 0 0 0 0 0 0 0 0 0]
[ 0 119 0 0 0 0 0 0 0 0 0]
[ 0 36 0 0 0 0 0 0 0 0 0]
[ 0 60 0 0 0 0 0 0 0 0 0]
[ 0 63 0 0 0 0 0 0 0 0 0]
[ 0 26 0 0 0 0 0 0 0 0 0]
[ 0 75 0 0 0 0 0 0 0 0 0]
[ 0 141 0 0 0 0 0 0 0 0 0]]
precision recall f1-score support
defense 0.00 0.00 0.00 59
eiffel 0.16 1.00 0.28 145
invalides 0.00 0.00 0.00 99
louvre 0.00 0.00 0.00 76
moulinrouge 0.00 0.00 0.00 119
museedorsay 0.00 0.00 0.00 36
notredame 0.00 0.00 0.00 60
pantheon 0.00 0.00 0.00 63
pompidou 0.00 0.00 0.00 26
sacrecoeur 0.00 0.00 0.00 75
triomphe 0.00 0.00 0.00 141
avg / total 0.03 0.16 0.04 899](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-27-320.jpg)
![分類性能を評価 (2/2)
params = {
'gamma': [10 ** i
for i in range(-3, 4)]
}
clf = grid_search.GridSearchCV(
SVC(),
params
)
clf.fit(
X[train_indices],
labels[train_indices]
)
y_pred = clf.predict(X[test_indices])
[[ 35 7 0 3 1 0 0 1 0 0 12]
[ 1 117 1 1 2 0 0 3 0 3 17]
[ 1 38 38 2 1 0 0 1 0 10 8]
[ 1 15 3 48 1 0 1 0 0 2 5]
[ 0 10 3 0 101 0 1 0 0 3 1]
[ 0 2 0 0 1 29 0 1 0 2 1]
[ 0 5 3 3 0 0 34 1 0 11 3]
[ 1 7 3 0 1 0 0 44 0 2 5]
[ 0 4 2 0 0 0 0 0 17 0 3]
[ 0 14 9 1 2 0 0 2 0 44 3]
[ 0 14 3 1 0 0 1 1 0 2 119]]
precision recall f1-score support
defense 0.90 0.59 0.71 59
eiffel 0.50 0.81 0.62 145
invalides 0.58 0.38 0.46 99
louvre 0.81 0.63 0.71 76
moulinrouge 0.92 0.85 0.88 119
museedorsay 1.00 0.81 0.89 36
notredame 0.92 0.57 0.70 60
pantheon 0.81 0.70 0.75 63
pompidou 1.00 0.65 0.79 26
sacrecoeur 0.56 0.59 0.57 75
triomphe 0.67 0.84 0.75 141
avg / total 0.73 0.70 0.70 899](https://image.slidesharecdn.com/mlbookimageprocessing-160930061057/85/slide-28-320.jpg)




















![SSII2020 [O3-01] Extreme 3D センシング](https://cdn.slidesharecdn.com/ss_thumbnails/200612-ssii-extreme3dsensing-print3-200608114658-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving](https://cdn.slidesharecdn.com/ss_thumbnails/surfelgan-200710035231-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)



![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)















