Deep learningもくもくハッカソンの結果まとめスライドです。 実際の数字については今後使うかもしれないので削ってますがご了承ください。 発表者はDeep learning初心者なので色々間違ってるかもです。

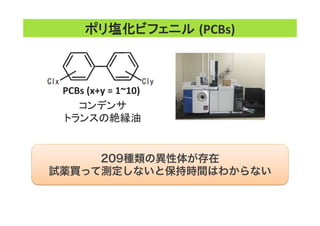



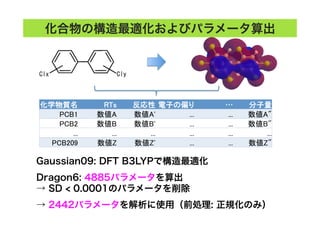
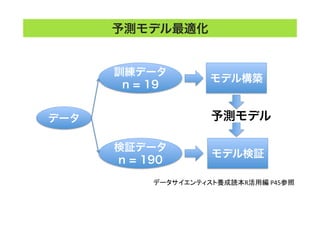












![[CB16] House of Einherjar :GLIBC上の新たなヒープ活用テクニック by 松隈大樹](https://cdn.slidesharecdn.com/ss_thumbnails/cb16matsukumaja-161109043944-thumbnail.jpg?width=640&height=640&fit=bounds)















































