More Related Content

PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~ 
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築 
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用 
PDF

PDF

PPTX
Jubatus Casual Talks #2: 大量映像・画像のための異常値検知とクラス分類 
PPTX
前回のCasual Talkでいただいたご要望に対する進捗状況 
PPTX
Jubatus使ってみた 作ってみたJubatus What's hot

PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜 
PDF
PythonによるDeep Learningの実装 
PDF

PDF

PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習 
PDF
TensorFlowの使い方(in Japanese) 
PPTX
Jupyter NotebookとChainerで楽々Deep Learning 
PPTX
Pythonとdeep learningで手書き文字認識 
PDF
Python 機械学習プログラミング データ分析演習編 
PDF
Chainer の Trainer 解説と NStepLSTM について 
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages. 
PDF

PDF

PDF

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17 
PDF
Introduction to Chainer (LL Ring Recursive) 
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた" 
PDF
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi... 
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説 
PDF
Viewers also liked

PDF

PPTX

PDF

PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化 
PPTX
Jubatus: Jubakitでもっと楽をしよう 
PDF

PDF
Jubatus Python特徴抽出プラグイン 
PDF

ODP

PDF

PDF

PPTX

PDF

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用 Similar to 第1回 Jubatusハンズオン

PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF
Oracle Cloud Developers Meetup@東京 
PDF

PDF

PDF
PFI Christmas seminar 2009 
PDF
MapReduceによる大規模データを利用した機械学習 
PDF
Machine learning CI/CD with OSS 
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平 
PDF

PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太 
PPTX
機械学習 / Deep Learning 大全 (1) 機械学習基礎編 
PDF

PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法 
PPTX
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門 
PDF

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング 
PDF

PPTX
0610 TECH & BRIDGE MEETING 
PDF
More from JubatusOfficial

PDF

PPTX

PDF

PDF

PPTX

PDF

PDF
データ圧縮アルゴリズムを用いたマルウェア感染通信ログの判定 
PDF
Jubatusでuserとbrandのレコメンドを試してみた話 
PPTX

PPTX

PDF

PDF
第1回 Jubatusハンズオン
- 1.
- 2.
⾃自⼰己紹介
l 海野 裕也 (Yuya Unno)
l Twitter: @unnonouno
l 株式会社Preferred Infrastructure
l 専⾨門
l ⾃自然⾔言語処理理
l テキストマイニング
2
- 3.
今⽇日の⽬目標
Jubatusを使って機械学習に触れてみる
l 初めて機械学習を使ってみる⼈人も対象です
l 機械学習の初歩から説明します
l ⾼高校数学くらいの知識識があればOK
l 詳しい⼈人にとっては少し退屈かもしれません
3
- 4.
アジェンダ
l イントロダクション
l Jubatusを使ってみる
l 設定を変更更してみる
4
- 5.
l イントロダクション
l Jubatusを使ってみる
l 設定を変更更してみる
5
- 6.
JubatusはOSSの機械学習フレームワークです
l NTT SIC*とPreferred Infrastructureによる共同開発
l 2011年年10⽉月よりOSSで公開 http://jubat.us/
リアルタイム
ストリーム 分散並列列 深い解析
6
* NTT SIC: NTT研究所 サイバーコミュニケーション研究所 ソフトウェアイノベーションセンタ
- 7.
- 8.
複数の選択肢から1つ選ぶのが「多値分類問題」
l ⼊入⼒力力xに対する出⼒力力yを予想するのが多値分類問題
l 機械学習の⼀一番基本的な問題設定
l ⼊入出⼒力力の組みをたくさん教えこむ
スポーツ記事
文書
or
芸能記事
分類器
(classifier)
⼈人物画像
画像
or
動物画像
8
- 9.
l イントロダクション
l Jubatusを使ってみる
l 設定を変更更してみる
9
- 10.
Jubatusの分類器を起動しましょう
l jubaclassiferコマンドが分類器のサーバー
l -f で設定を指定して起動する
$ jubaclassifier
can't start standalone mode without
configpath specified
usage: jubaclassifier [options] ...
options:
... [略略]
$ jubaclassifier -f /opt/jubatus/share/
jubatus/example/config/classifier/pa1.json
10
- 11.
- 12.
Jubatusはサーバー・クライアントモデルで動きま
す
Jubatus
ユーザープログ (jubaclassifier)
ラム
Jubatusクライ
通信
アント
各種言語で実装
l Jubatusクライアント経由でサーバーと通信する
l 通信⽅方法などはクライアントライブラリが隠蔽している
l クライアントはC++/Ruby/Python/Javaで⽤用意
12
- 13.
サンプルを⽤用意したので実⾏行行してみましょう
https://github.com/jubatus/jubatus-example
l jubaclassifierを起動した状態でサンプルを実⾏行行
l 以下の様な結果が出れば成功
$ cd jubatus-example/gender/python
$ ./gender.py
female 0.473417669535
male 0.388551652431 ラベルごとのスコア
female 2.79595327377
male -2.36301612854
13
- 14.
線形分類は重み付き多数決のイメージ
男性
女性
入力の特徴
短髪
1.8
Tシャツ
0.3
スカート
3.2
(+
1.1 ⼥女女性だ!
l 特徴毎のスコアを加算して⼤大きい⽅方を採る
14
- 15.
学習するときは間違いを正す⽅方向に重みを調整
男性
女性
天の声=正解
入力の特徴
短髪
2.5 違います。男性
です
Tシャツ
0.8
スカート
2.8
(+
これらの特徴は男性
0.5
的なのかな?
l 判断が覆るように重みを調整する
l 学習アルゴリズム毎に重み調整の度度合いが異異なる
15
- 16.
サンプルを読んでみよう
l sample.pyの中は⼤大雑把には以下のとおり
#(前略略)
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
#(後略略)
16
- 17.
Jubatusはクライアントオブジェクト経由で使う
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
#(前略略)
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
#(後略略)
17
- 18.
正解のわかっているデータを使って学習(train)を⾏行行
う
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
client = jubatus.Classifier(host, port)
train_data = [
('male’, datum([('hair', 'short’), ...),
...
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
18
- 19.
学習したら未分類のデータを分類(classify)する
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [
datum([('hair', 'short'), ... ),
...
]
results = client.classify(name, test_data)
19
- 20.
単体のデータを表すdatumクラスの構造に注意
l ⽂文字列列情報と数値情報のリストを別々に指定する
l それぞれは、キーと値のペアのリストになっている
l 下のデータは、”hair”が”short”、“top”が”T shirt”、”height”が
1.81と読む
datum(
[('hair', 'short'), ('top', 'T shirt’),],
[('height', 1.81)]
)
20
- 21.
データを追加してみよう
l 学習⽤用のデータを増やすと⼀一般的に分類性能が良良くなる
l 無限に増やしても、全て当たるようになるわけではない
client = jubatus.Classifier(host, port)
train_data = [
('male’, datum([('hair', 'short’), ...),
...
# ここにデータを追加
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
21
- 22.
ラベルを追加してみよう
l ラベルを細かくすると分類も細かくできる
l 粒粒度度を細かくするとそれだけ正解率率率は落落ちるので注意
client = jubatus.Classifier(host, port)
train_data = [
('male (adult)’, datum([('hair',
'short’), ...),
...
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
22
- 23.
l イントロダクション
l Jubatusを使ってみる
l 設定を変更更してみる
23
- 24.
設定を⾒見見てみよう
特徴抽出の設定
{
"converter" : {
...
学習⽅方法のパラメータ
},
"parameter" : {
"regularization_weight" : 1.0
},
"method" : "PA1"
}
学習の⽅方法
24
- 25.
学習アルゴリズムを変えてみよう
{
"converter" : { ... },
"parameter" : { ... },
"method" : ”AROW"
}
l “method” は学習アルゴリズムを指定する
l “PA1” から ”AROW” に変えてみる
l 利利⽤用できるアルゴリズムはドキュメント参照
25
- 26.
パラメータを変えてみよう
{
"converter" : { ... },
"parameter" : {
"regularization_weight" : 10.0
},
"method" : "PA1"
}
l parameter はどのように学習するかの調整に使われる
l 学習で調整されるパラメータとは区別する意味で、ハイ
パーパラメータと呼ばれる
l よい値はデータやアプリケーションによって異異なる
26
- 27.
残りの設定は特徴抽出の設定です
{
"converter" : {
...
},
“parameter” : { ... },
"method" : "PA1"
}
l converter は⽣生のデータをどう扱うかの、特徴抽出に関
する設定
l 設定のしどころであり、学習がうまくいくかの重要な部
分
27
- 28.
タスク固有の問題と⼿手法を分離離している
特徴抽出
特徴分析
分野に依存しない 様々な⼿手法・理理論論を
特徴を捉えた抽象化されたデータ 適⽤用可能
⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) 分類/回帰:SVM, LogReg,
(1, 0.5, 0.1, -‐‑‒2, 3, …) PA, CW, ALOW, Naïve Bayes
(0, 1, 0, 1.5, 2, …) CNB, DT, RF, ANN, …
特徴ベクトル
画像 クラスタリング:K-‐‑‒means,
Spectral Clustering, MMC,
LSI, LDA, GM, …
⾏行行動履履歴 グラフィカルモデル 構造分析:HMM, MRF, CRF, …
センサ情報 28
- 29.
タスク固有の問題と⼿手法の分離離(続)
l 特徴抽出と特徴分析を分離離することが重要
l データの種類、ドメイン、利利⽤用⽬目的に依存せず、様々な
分析を利利⽤用可能なしくみを作ることができる
l 利利点
l システム開発・専⾨門家教育のコストを⼤大きく下げることができ
る
l 特徴抽出では各問題ドメインに専念念
l 特徴分析では各分析⼿手法に専念念
29
- 30.
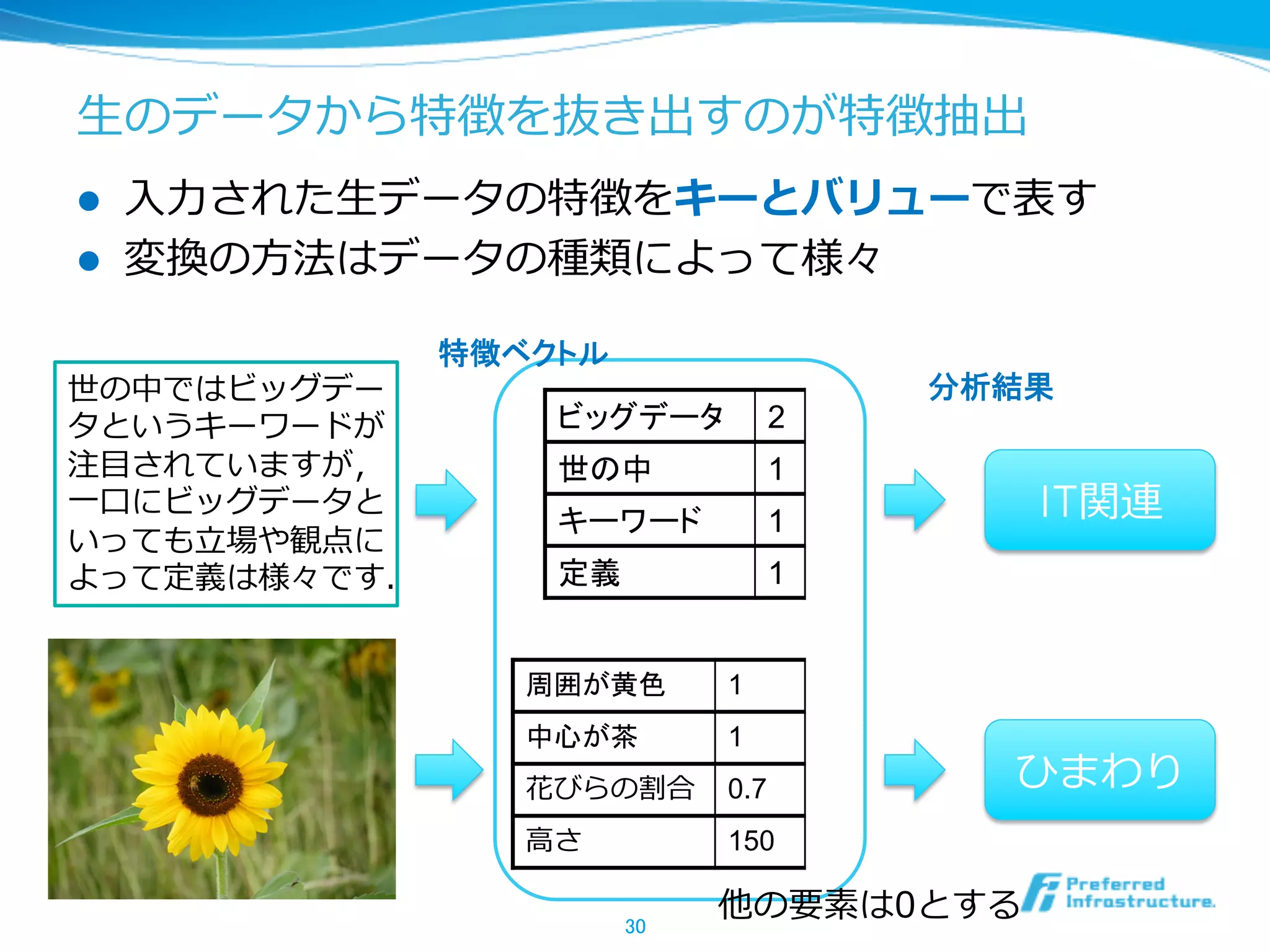
⽣生のデータから特徴を抜き出すのが特徴抽出
l ⼊入⼒力力された⽣生データの特徴をキーとバリューで表す
l 変換の⽅方法はデータの種類によって様々
特徴ベクトル
世の中ではビッグデー 分析結果
タというキーワードが ビッグデータ 2
注⽬目されていますが, 世の中 1
⼀一⼝口にビッグデータと
キーワード 1 IT関連
いっても⽴立立場や観点に
よって定義は様々です. 定義 1
周囲が黄色 1
中心が茶 1
花びらの割合 0.7 ひまわり
⾼高さ 150
30
他の要素は0とする
- 31.
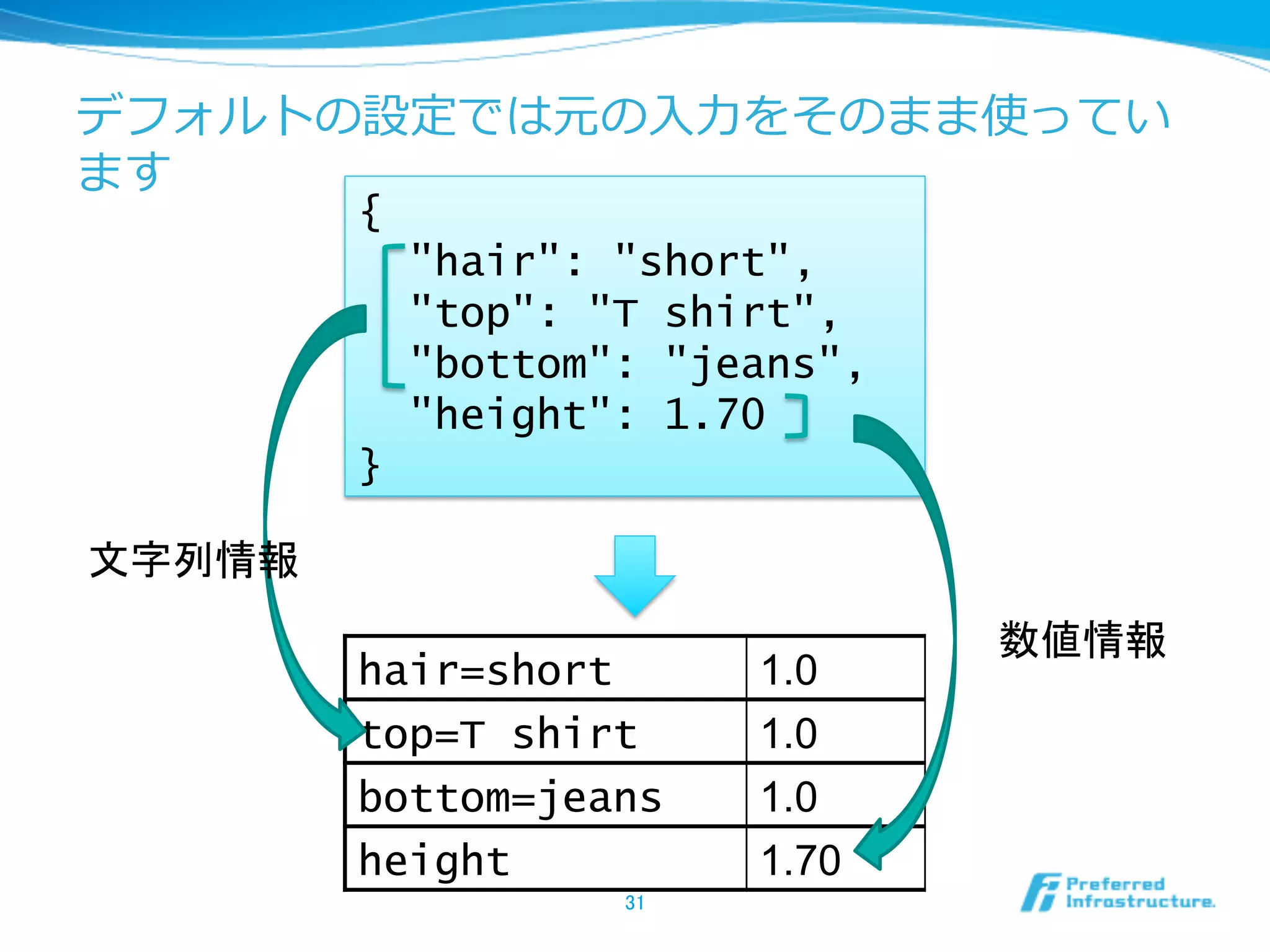
デフォルトの設定では元の⼊入⼒力力をそのまま使ってい
ます
{
"hair": "short",
"top": "T shirt",
"bottom": "jeans",
"height": 1.70
}
文字列情報
数値情報
hair=short 1.0
top=T shirt 1.0
bottom=jeans 1.0
height 1.70
31
- 32.
⽂文字列列に対する処理理
{
"hair": "short", l キーと値の組み合わ
"top": "T shirt", せで、1つの特徴に
"bottom": "jeans", なるようにする
"height": 1.70
}
l 値は1.0で固定
hair=short 1.0
top=T shirt 1.0
bottom=jeans 1.0
height 1.70
32
- 33.
- 34.
数値に対する処理理
{
"hair": "short", l キーと値をそのまま
"top": "T shirt", 特徴の値となるよう
"bottom": "jeans", にする
"height": 1.70
}
hair=short 1.0
top=T shirt 1.0
bottom=jeans 1.0
height 1.70
34
- 35.
- 36.
特徴の取り⽅方を⼯工夫することで分類精度度が変わりま
す
世の中ではビッグデータ… 1.0
世の中ではビッグデー
タというキーワードが
注⽬目されていますが, 世の中 1.0
⼀一⼝口にビッグデータと
いっても⽴立立場や観点に ビッグデータ 2.0
よって定義は様々です.
キーワード 1.0
⽴立立場 1.0
l 特徴の粒粒度度が細かすぎても粗すぎても学習はうまくいか
ない
36
- 37.
スペース区切切りで特徴をとってみましょう
...
"string_rules" :[
{ "key" : "*”,
"type" : “space",
"sample_weight" : "bin”,
"global_weight" : "bin" }
],
...
l スペース区切切りを使う場合はtypeにspaceを使う
l 他にも特徴の取り⽅方は設定で簡単に変えられるので、ド
キュメントを参照
37
- 38.
その他の情報源
l ドキュメント
l http://jubat.us/ja/
l 特徴抽出や設定周りもひと通り書いてある
l メーリングリスト
l http://groups.google.com/group/jubatus
l ソースとバグ報告
l https://github.com/jubatus/jubatus
38
- 39.
⾃自由に改変してみましょう
l jubatus-example以下に、⾊色々サンプルがあるので試し
てみる
l 分類以外のサンプルもあるが、記述⾔言語が限られている
l よく知られたデータセットを利利⽤用してみる
l http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets
l news20で検索索
l Enjoy!
39









![Jubatusの分類器を起動しましょう
l jubaclassiferコマンドが分類器のサーバー
l -f で設定を指定して起動する
$ jubaclassifier
can't start standalone mode without
configpath specified
usage: jubaclassifier [options] ...
options:
... [略略]
$ jubaclassifier -f /opt/jubatus/share/
jubatus/example/config/classifier/pa1.json
10](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-10-2048.jpg)





![サンプルを読んでみよう
l sample.pyの中は⼤大雑把には以下のとおり
#(前略略)
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
#(後略略)
16](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-16-2048.jpg)
![Jubatusはクライアントオブジェクト経由で使う
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
#(前略略)
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
#(後略略)
17](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-17-2048.jpg)
![正解のわかっているデータを使って学習(train)を⾏行行
う
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
client = jubatus.Classifier(host, port)
train_data = [
('male’, datum([('hair', 'short’), ...),
...
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
18](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-18-2048.jpg)
![学習したら未分類のデータを分類(classify)する
l 最初にクライアントオブジェクトを⽣生成する
l クライアントオブジェクト経由で操作する
client = jubatus.Classifier(host, port)
train_data = [ ... ]
client.train(name, train_data)
test_data = [
datum([('hair', 'short'), ... ),
...
]
results = client.classify(name, test_data)
19](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-19-2048.jpg)
![単体のデータを表すdatumクラスの構造に注意
l ⽂文字列列情報と数値情報のリストを別々に指定する
l それぞれは、キーと値のペアのリストになっている
l 下のデータは、”hair”が”short”、“top”が”T shirt”、”height”が
1.81と読む
datum(
[('hair', 'short'), ('top', 'T shirt’),],
[('height', 1.81)]
)
20](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-20-2048.jpg)
![データを追加してみよう
l 学習⽤用のデータを増やすと⼀一般的に分類性能が良良くなる
l 無限に増やしても、全て当たるようになるわけではない
client = jubatus.Classifier(host, port)
train_data = [
('male’, datum([('hair', 'short’), ...),
...
# ここにデータを追加
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
21](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-21-2048.jpg)
![ラベルを追加してみよう
l ラベルを細かくすると分類も細かくできる
l 粒粒度度を細かくするとそれだけ正解率率率は落落ちるので注意
client = jubatus.Classifier(host, port)
train_data = [
('male (adult)’, datum([('hair',
'short’), ...),
...
]
client.train(name, train_data)
test_data = [ ... ]
results = client.classify(name, test_data)
22](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-22-2048.jpg)








![string_rulesに⽂文字列列データの変換規則を書きます
...
"string_rules" : [
{ "key" : "*”,
"type" : "str",
"sample_weight" : "bin”,
"global_weight" : "bin" }
],
...
l key: * 全てのデータに対して、
l type: str 値をそのまま使う
l sample_weight, global_weight: 重み付けは1.0
33](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-33-2048.jpg)

![num_rulesに数値データの変換規則を書きます
...
”num_rules" : [
{ "key" : "*”,
"type" : ”num” }
],
...
l key: * 全てのデータに対して
l type: num 数値をそのまま使う
35](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-35-2048.jpg)

![スペース区切切りで特徴をとってみましょう
...
"string_rules" : [
{ "key" : "*”,
"type" : “space",
"sample_weight" : "bin”,
"global_weight" : "bin" }
],
...
l スペース区切切りを使う場合はtypeにspaceを使う
l 他にも特徴の取り⽅方は設定で簡単に変えられるので、ド
キュメントを参照
37](https://image.slidesharecdn.com/jubauts-handson-130219085541-phpapp02/75/1-Jubatus-37-2048.jpg)

