Download as PDF, PPTX




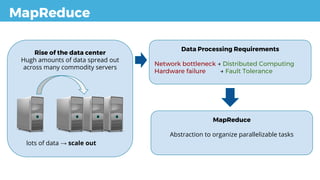
![MapReduce
Input Split Map [combine]
Suffle &
Sort
Reduce Output
AA BB AA
AA CC DD
AA EE DD
BB FF AA
AA BB AA
AA CC DD
AA EE DD
BB FF AA
(AA, 1)
(BB, 1)
(AA, 1)
(AA, 1)
(CC, 1)
(DD, 1)
(AA, 1)
(EE, 1)
(DD, 1)
(BB, 1)
(FF, 1)
(AA, 1)
(AA, 2)
(BB, 1)
(AA, 1)
(CC, 1)
(DD, 1)
(AA, 1)
(EE, 1)
(DD, 1)
(BB, 1)
(FF, 1)
(AA, 1)
(AA, 2)
(AA, 1)
(AA, 1)
(AA, 1)
(BB, 1)
(BB, 1)
(CC, 1)
(DD, 1)
(DD, 1)
(EE, 1)
(FF, 1)
(AA, 5)
(BB, 2)
(CC, 1)
(DD, 2)
(EE, 1)
(FF, 1)
AA, 5
BB, 2
CC, 1
DD, 2
EE, 1
FF, 1](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-7-320.jpg)
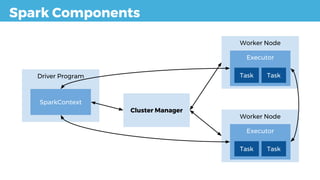




![RDD
Resilient Distributed Datasets
● Collection of objects that is distributed across
nodes in a cluster
● Data Operations are performed on RDD
● Once created, RDD are immutable
● RDD can be persisted in memory or on disk
● Fault Tolerant
numbers = RDD[1,2,3,4,5,6,7,8,9,10]
Worker Node
Executor
[1,5,6,9]
Worker Node
Executor
[2,7,8]
Worker Node
Executor
[3,4,10]](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-13-320.jpg)

![RDD
Internally, each RDD is characterized by five main properties
A list of partitions
A function for
computing each split
A list of dependencies
on other RDDs
A Partitioner for key-value RDDs
A list of preferred locations to
compute each split on
Method Location Input Output
getPartitions()
compute()
getDependencies()
Driver
Driver
Worker
-
Partition
-
[Partition]
Iterable
[Dependency]
Optionally](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-15-320.jpg)
![RDD
Creating RDDs
Text File
Collection
Database
val textFile = sc.textFile("README.md")
val input = sc.parallelize(List(1, 2, 3, 4))
val casRdd = sc.newAPIHadoopRDD(
job.getConfiguration(),
classOf[ColumnFamilyInputFormat],
classOf[ByteBuffer],
classOf[SortedMap[ByteBuffer, IColumn]])
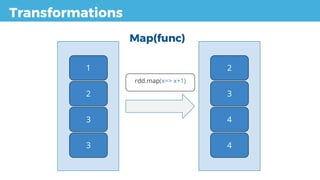
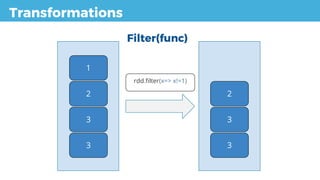
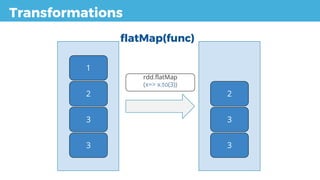
Transformation val input = rddFather.map(value => value.toString )
File / set of files
(Local/Distributed)
Memory
Another RDD
Spark load and
write data with
database](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-16-320.jpg)




![Actions
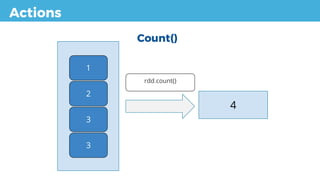
count() Returns the number of elements in the dataset
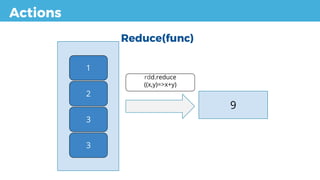
reduce(func) Aggregate the elements of the dataset using a function func
(which takes two arguments and returns one). The function
should be commutative and associative so that it can be
computed correctly in parallel
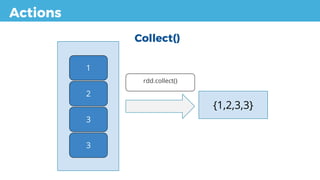
collect() Return all the elements of the dataset as an array at the driver
program. This is usually useful after a filter or other operation
that returns a sufficiently small subset of the data
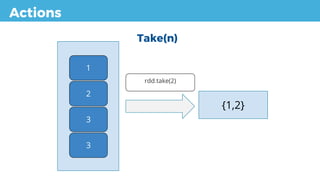
take(n) Returns an array with first n elements
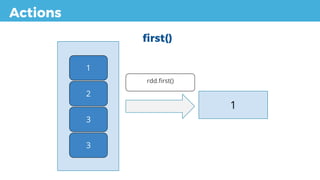
first() Returns the first element of the dataset
takeOrdered
(n,[ordering])
Returns first n elements of RDD using natural order or custom
operator
Commonly Used Actions](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-28-320.jpg)
![Actions
takeOrdered(n,[ordering])
{3,3}
1
2
3
3
rdd.takeOrdered(2)
(myOrdering)](https://image.slidesharecdn.com/introductiontoapachespark-170202121140/85/Introduction-to-Apache-Spark-34-320.jpg)




The document provides an introduction to Apache Spark, highlighting its capabilities as a fast, in-memory cluster computing platform that supports multiple programming languages and various deployment options. It covers the concept of resilient distributed datasets (RDDs) and their operations, including transformations and actions, which are essential for processing large-scale data. Additionally, the document outlines Spark's architecture, components like the cluster manager and driver program, and ends with a workshop for practical application of the concepts discussed.
































































































