




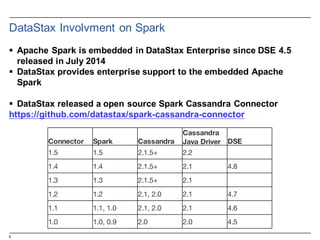




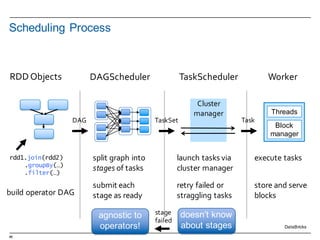
![14
Resilient Distributed Datasets: Properties
§ Immutable
§ Two types of operations
– Transformations ~ DDL (Create View V2 as…)
• val rddNumbers = sc.parallelize(1 to 10): Numbers from 1 to 10
• val rddNumbers2 = rddNumbers.map (x => x+1): Numbers from 2 to 11
• The LINEAGE on how to obtain rddNumbers2 from rddNumber is recorded
• It’s a Directed Acyclic Graph (DAG)
• No actual data processing does take place è Lazy evaluations
– Actions ~ DML (Select * From V2…)
• rddNumbers2.collect(): Array [2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
• Performs transformations and action
• Returns a value (or write to a file)
§ Fault tolerance
– If data in memory is lost it will be recreated from lineage
§ Caching, persistence (memory, spilling, disk) and check-pointing](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-14-320.jpg)
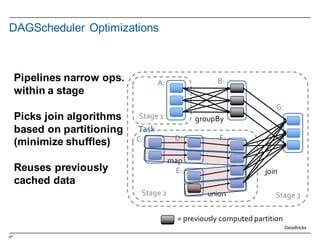
![15
RDD Transformations
§ Transformations are lazy evaluations
§ Returns a transformed RDD
§ Pair RDD (K,V) functions for MapReduce style transformations
Transformation Meaning
map(func) Return a new dataset formed by passing each element of the source through a function func.
filter(func) Return a new dataset formed by selecting those elements of the source on which func returns
true.
flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items. So func should
return a Seq rather than a single item
Full documentation at http://spark.apache.org/docs/1.4.1/api/scala/index.html#org.apache.spark.rdd.PairRDDFunctions
join(otherDataset,
[numTasks])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all
pairs of elements for each key.
reduceByKey(func) When called on a dataset of (K, V) pairs, returns a dataset of (K,V) pairs where the values for
each key are aggregated using the given reduce function func
sortByKey([ascendin
g],[numTasks])
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K,V)
pairs sorted by keys in ascending or descending order.
combineByKey[C}(cr
eateCombiner,
mergeValue,
mergeCombiners))
Generic function to combine the elements for each key using a custom set of aggregation
functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C.
createCombiner: (V) ⇒ C, mergeValue: (C, V) ⇒ C, mergeCombiners: (C, C) ⇒ C)
Full documentation at http://spark.apache.org/docs/1.4.1/api/scala/index.html#org.apache.spark.rdd.RDD](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-15-320.jpg)

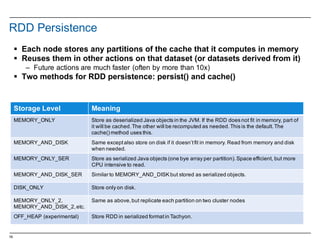









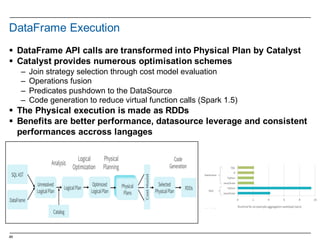
![28
Functional methods on collections
Method on Seq[T] Explanation
map(f: T => U): Seq[U] Each element is result of f
flatMap(f: T => Seq[U]): Seq[U] One to many map
filter(f: T => Boolean): Seq[T] Keep elements passing f
exists(f: T => Boolean): Boolean True if one element passes f
forall(f: T => Boolean): Boolean True if all elements pass
reduce(f: (T, T) => T): T Merge elements using f
groupBy(f: T => K): Map[K, List[T]] Group elements by f
sortBy(f: T => K): Seq[T] Sort elements
…..
There are a lot of methods on Scala collections, just google Scala Seq or http://www.scala-lang.org/api/2.
10.4/index.html#scala.collection.Seq
Scala Crash Course, Holden Karau, DataBricks](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-28-320.jpg)



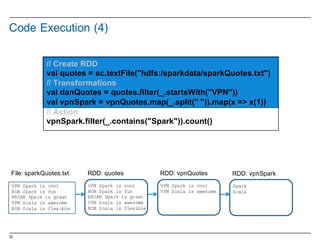
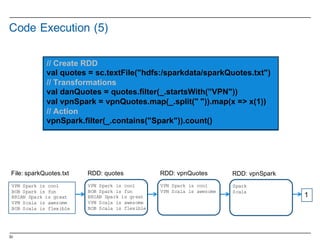









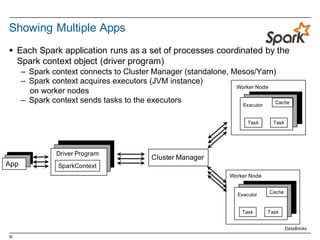
![48
RDD Direct Acyclic Graph (DAG)
§ View the lineage
§ Could be issued in a continuous line
scala> vpnSpark.toDebugString
res1: String =
(2) MappedRDD[4] at map at <console>:16
| MappedRDD[3] at map at <console>:16
| FilteredRDD[2] at filter at <console>:14
| hdfs:/sparkdata/sparkQuotes.txt MappedRDD[1] at textFile at <console>:12
| hdfs:/sparkdata/sparkQuotes.txt HadoopRDD[0] at textFile at <console>:12
val vpnSpark = sc.textFile("hdfs:/sparkdata/sparkQuotes.txt").
filter(_.startsWith(”VPN")).
map(_.split(" ")).
map(x => x(1)).
.filter(_.contains("Spark"))
vpnSpark.count()](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-48-320.jpg)







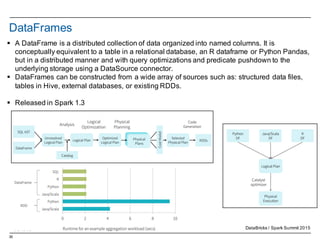
![58
Spark Properties
§ Set application properties via the SparkConf object
val conf = new SparkConf()
.setMaster("local")
.setAppName("CountingSheep")
.set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
§ Dynamically setting Spark properties
– SparkContext with an empty conf
val sc = new SparkContext(new SparkConf())
– Supply the configuration values during runtime
./bin/spark-submit --name "My app" --master local[4] --conf
spark.shuffle.spill=false --conf "spark.executor.extraJavaOptions=-
XX:+PrintGCDetails -XX:+PrintGCTimeStamps" myApp.jar
– conf/spark-defaults.conf](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-58-320.jpg)



![64
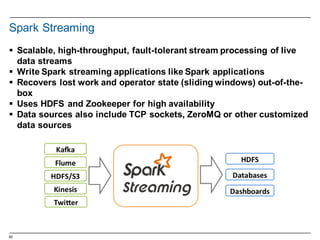
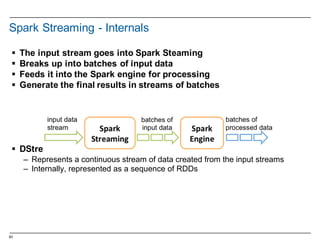
Spark Streaming - Getting Started
§ Count the number of words coming in from the TCP socket
§ Import the Spark Streaming classes
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
§ Create the StreamingContext object
val conf =
new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
§ Create a DStream
val lines = ssc.socketTextStream("localhost", 9999)
§ Split the lines into words
val words = lines.flatMap(_.split(" "))
§ Count the words
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
§ Print to the console
wordCounts.print()](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-64-320.jpg)



![71
$ dse spark
...
Spark context available as sc.
HiveSQLContext available as hc.
CassandraSQLContext available as csc.
scala> sc.cassandraTable("test", "kv")
res5: com.datastax.spark.connector.rdd.CassandraRDD
[com.datastax.spark.connector.CassandraRow] =
CassandraRDD[2] at RDD at CassandraRDD.scala:48
scala> sc.cassandraTable("test", "kv").collect
res6: Array[com.datastax.spark.connector.CassandraRow] =
Array(CassandraRow{k: 1, v: foo})
cqlsh> select *
from test.kv;
k | v
-‐-‐-‐+-‐-‐-‐-‐-‐
1 | foo
(1 rows)
DSE Spark Interactive Shell](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-71-320.jpg)


.select("user_name", "message")
.where("user_name = ?", "ewa")
row
representation keyspace table
server side
column and row
selection](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-73-320.jpg)

.toArray
//Array(Vehicle(KF334L, Ford Mondeo,
Petrol, 2009),
// Vehicle(MT8787, Hyundai x35,
Diesel, 2011)
à
• Mapping rows to Scala Case Classes
• CQL underscore case column mapped to Scala camel case property
• Custom mapping functions (see docs)](https://image.slidesharecdn.com/sparkdseenablementin4hoursvp201601252350-160126143807/85/Apache-Spark-and-DataStax-Enablement-75-320.jpg)



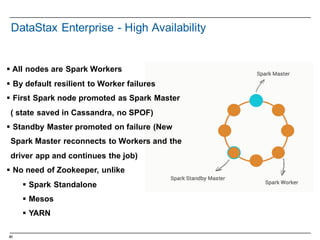
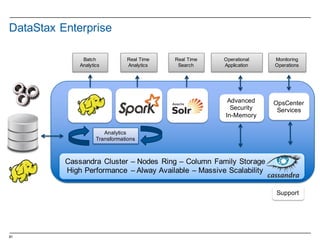



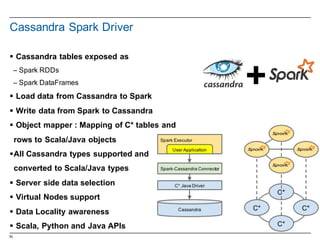
The document introduces Apache Spark as a fast, flexible cluster computing system for large-scale data processing, providing APIs for various programming languages. It highlights the integration of Spark with Datastax Enterprise and details the functionalities of Resilient Distributed Datasets (RDDs), including their creation, manipulation, and persistence. Additionally, the document covers a brief history of Spark and its market adoption, as well as providing insights into the Scala programming language used within Spark.























































































