Download as PDF, PPTX




















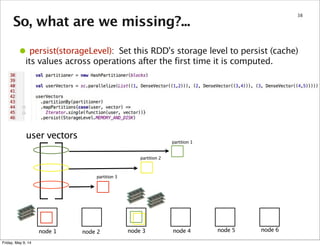
![So, what are we missing?...
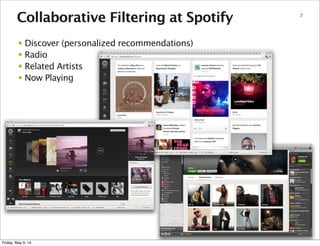
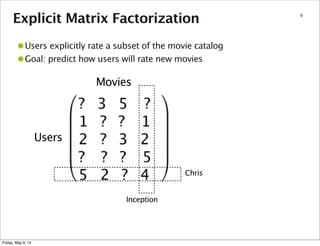
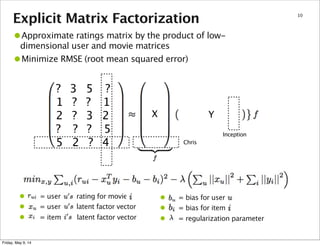
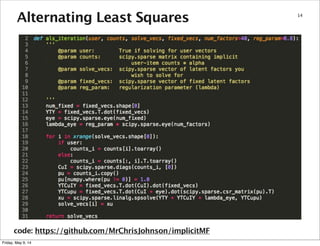
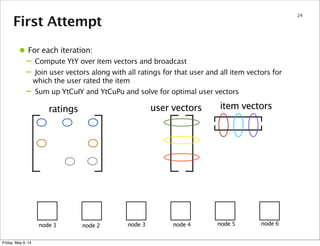
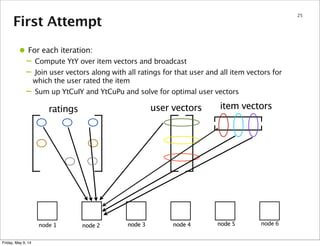
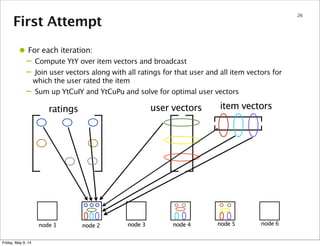
37
•mapPartitions(func): Similar to map, but runs separately on each
partition (block) of the RDD, so func must be of type Iterator[T] =>
Iterator[U] when running on an RDD of type T.
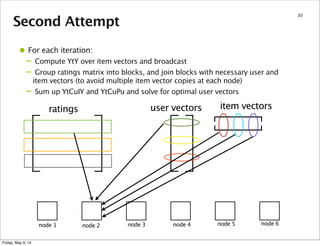
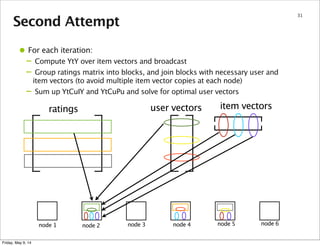
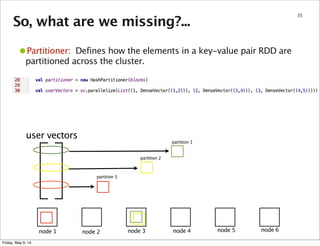
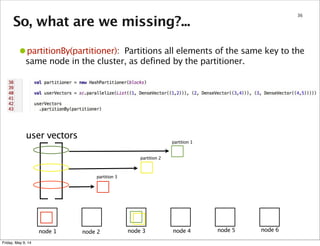
node 1 node 2 node 3 node 4 node 5 node 6
user vectors
partition 1
partition 2
partition 3
function()
function()
function()
Friday, May 9, 14](https://image.slidesharecdn.com/spark-meetup-140509143826-phpapp02/85/Collaborative-Filtering-with-Spark-37-320.jpg)
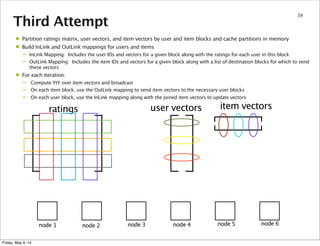
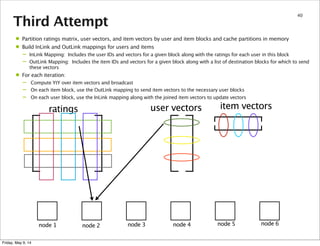
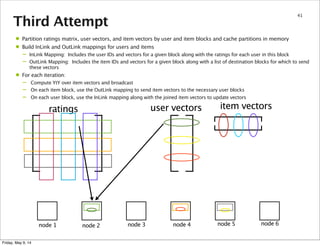
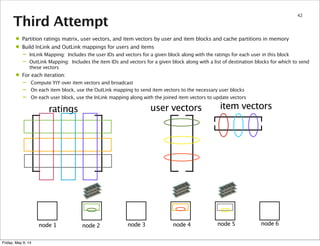
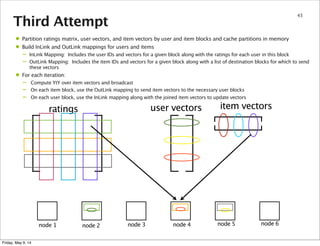
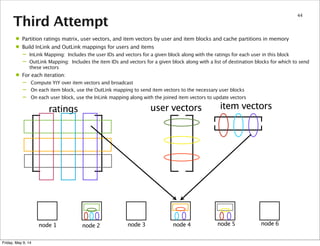













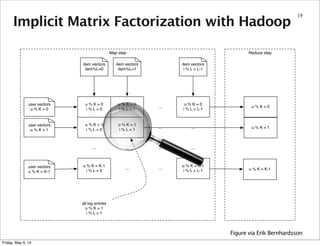
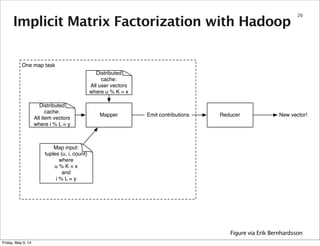
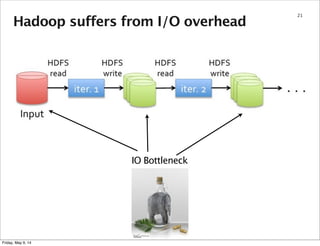
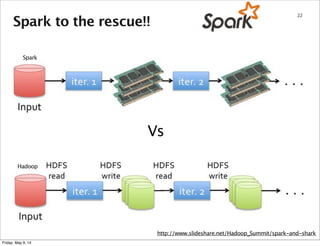
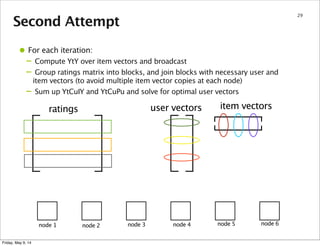
This document summarizes an approach for scaling implicit matrix factorization to large datasets using Apache Spark. It discusses three attempts at implementing alternating least squares for collaborative filtering in Spark. The first two attempts shuffle data across nodes on each iteration. The third attempt partitions and caches the user/item vectors, then builds mappings to join local blocks of data and update vectors within each partition, avoiding shuffles between iterations for more efficient distributed computation.


















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
