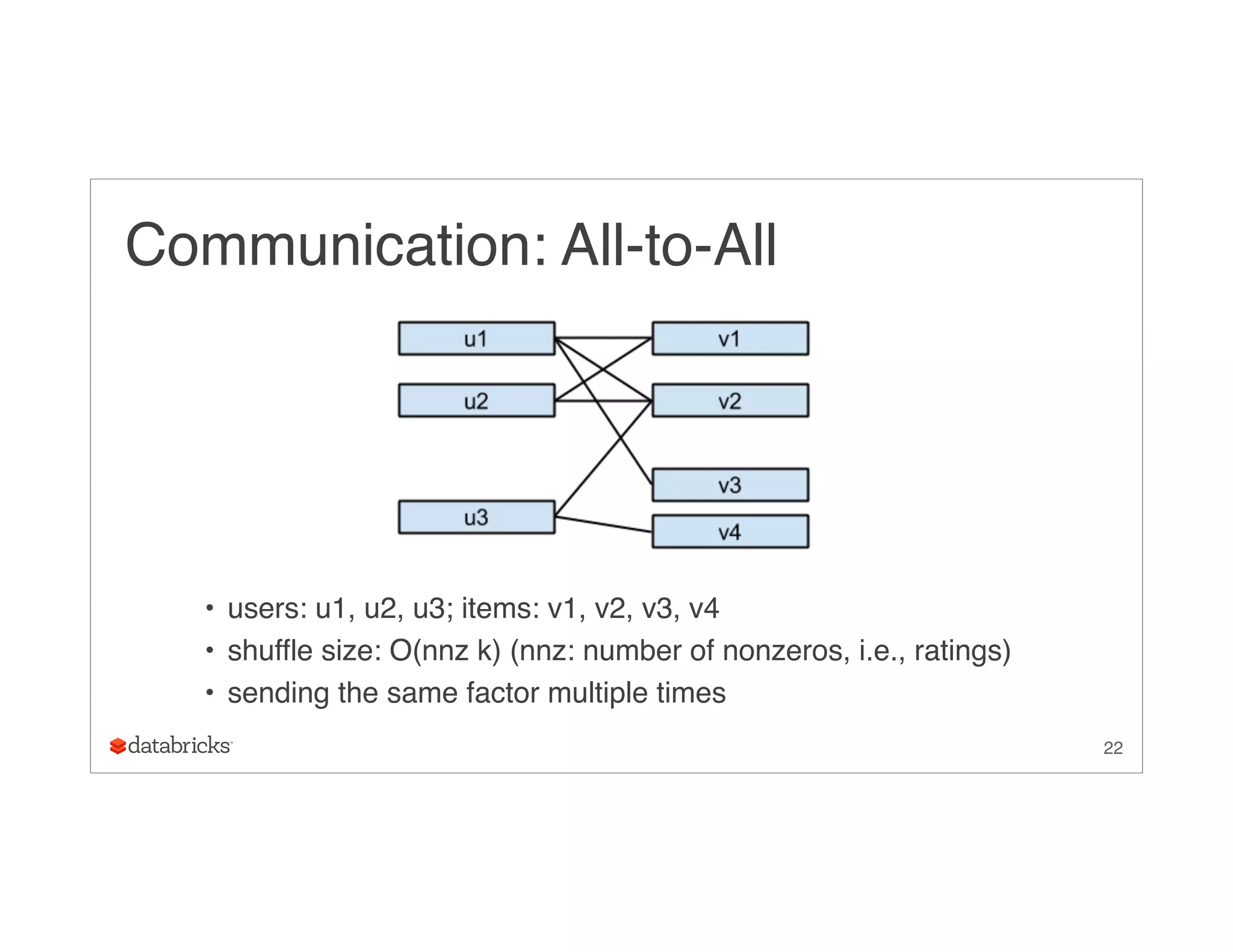
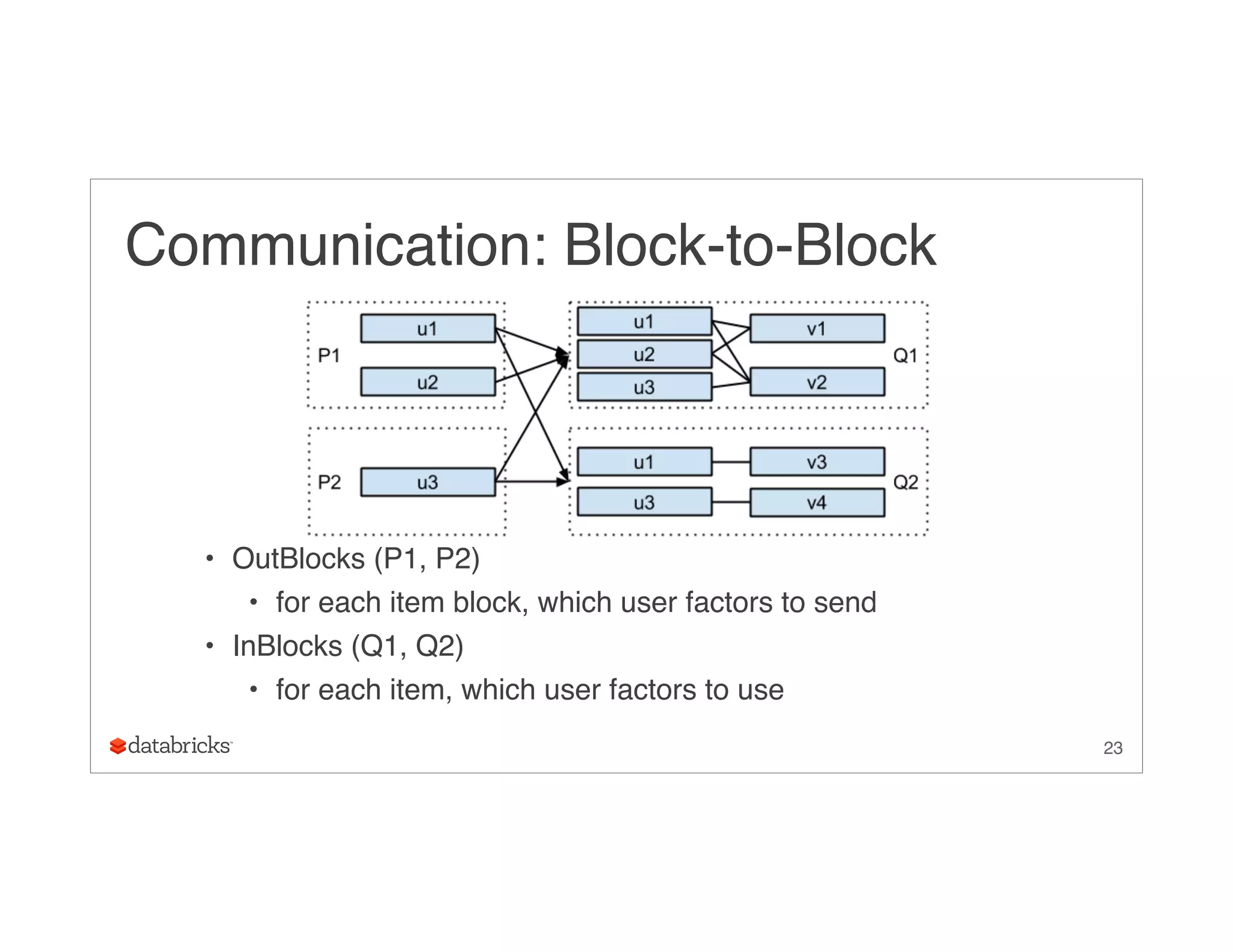
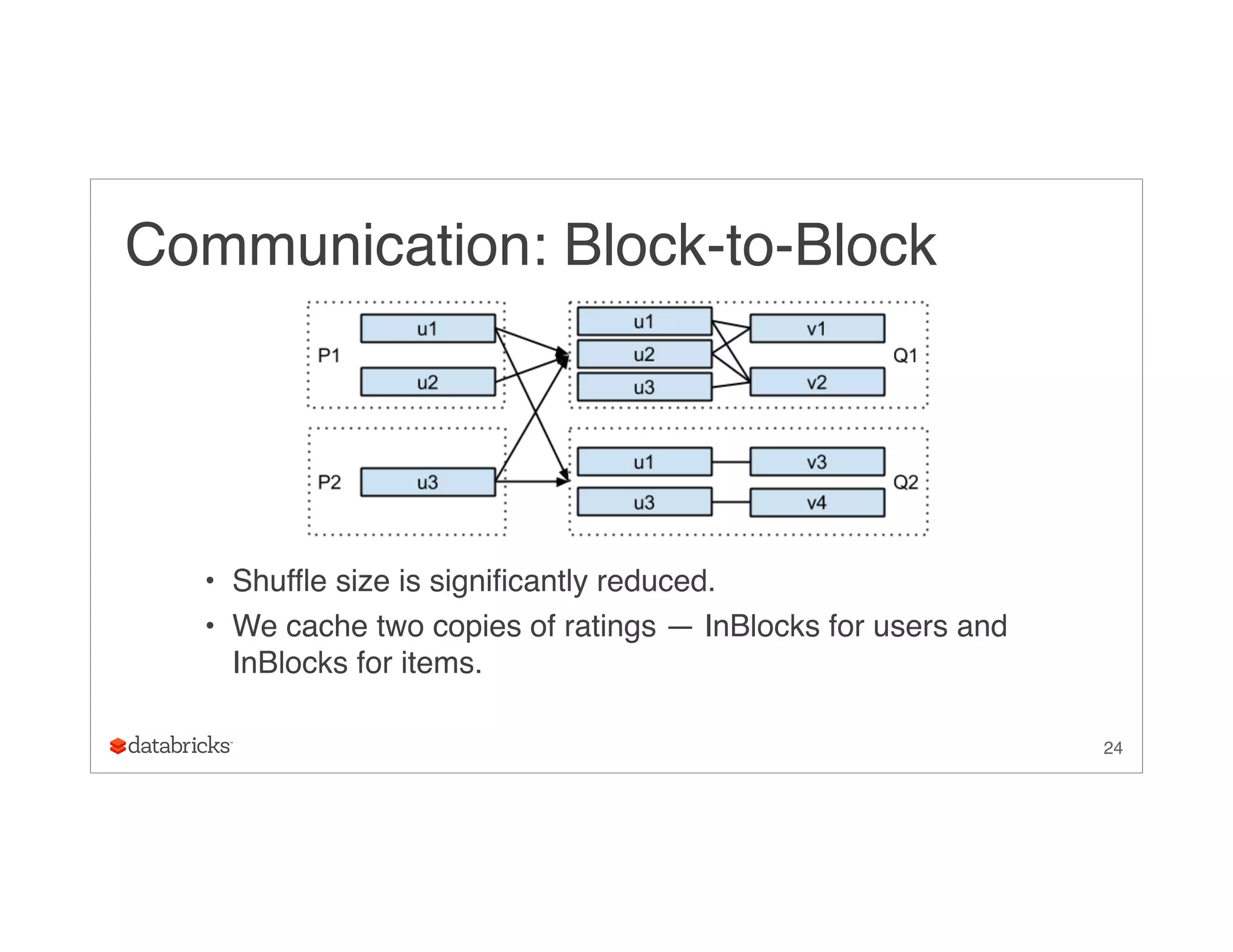
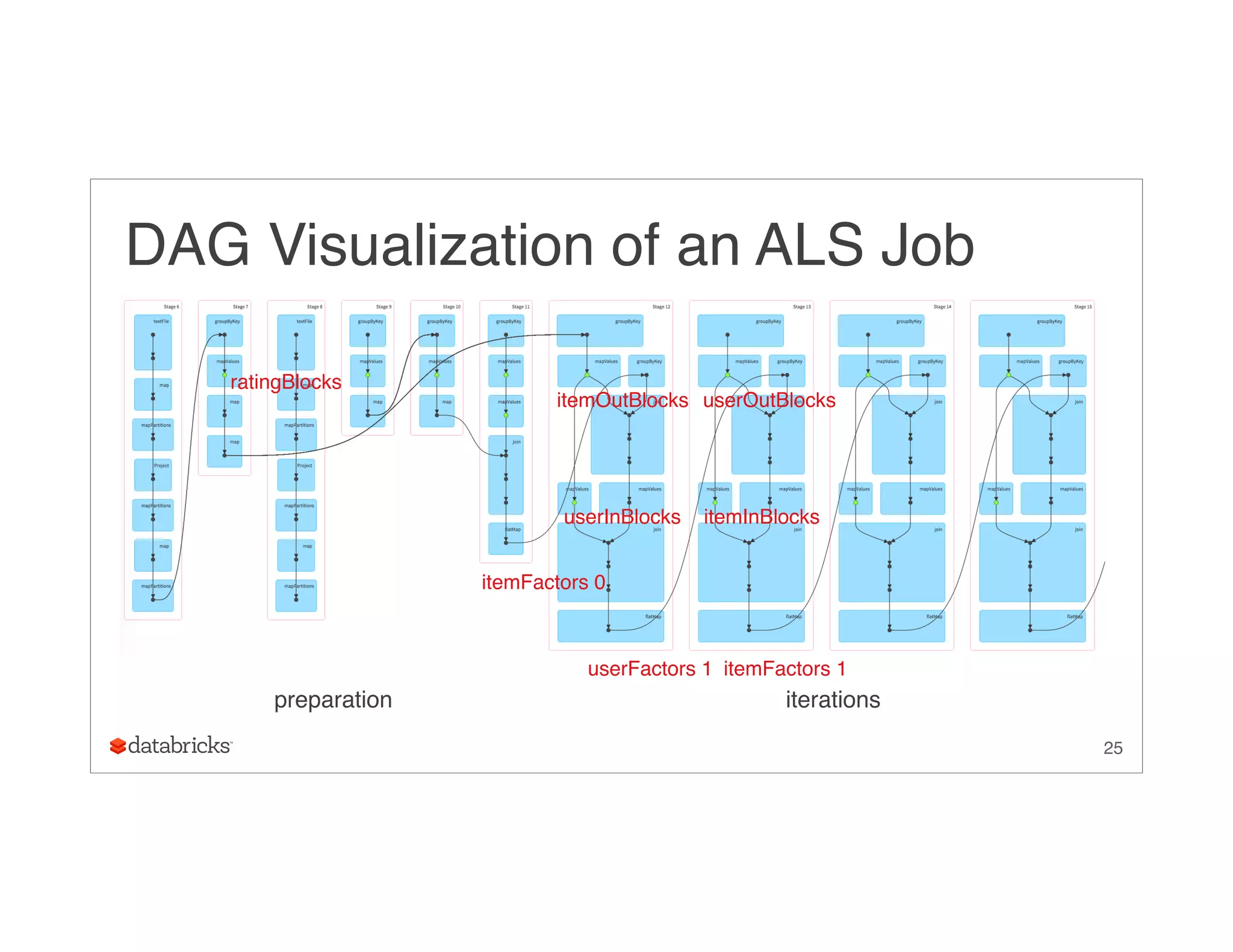
Download as PDF, PPTX






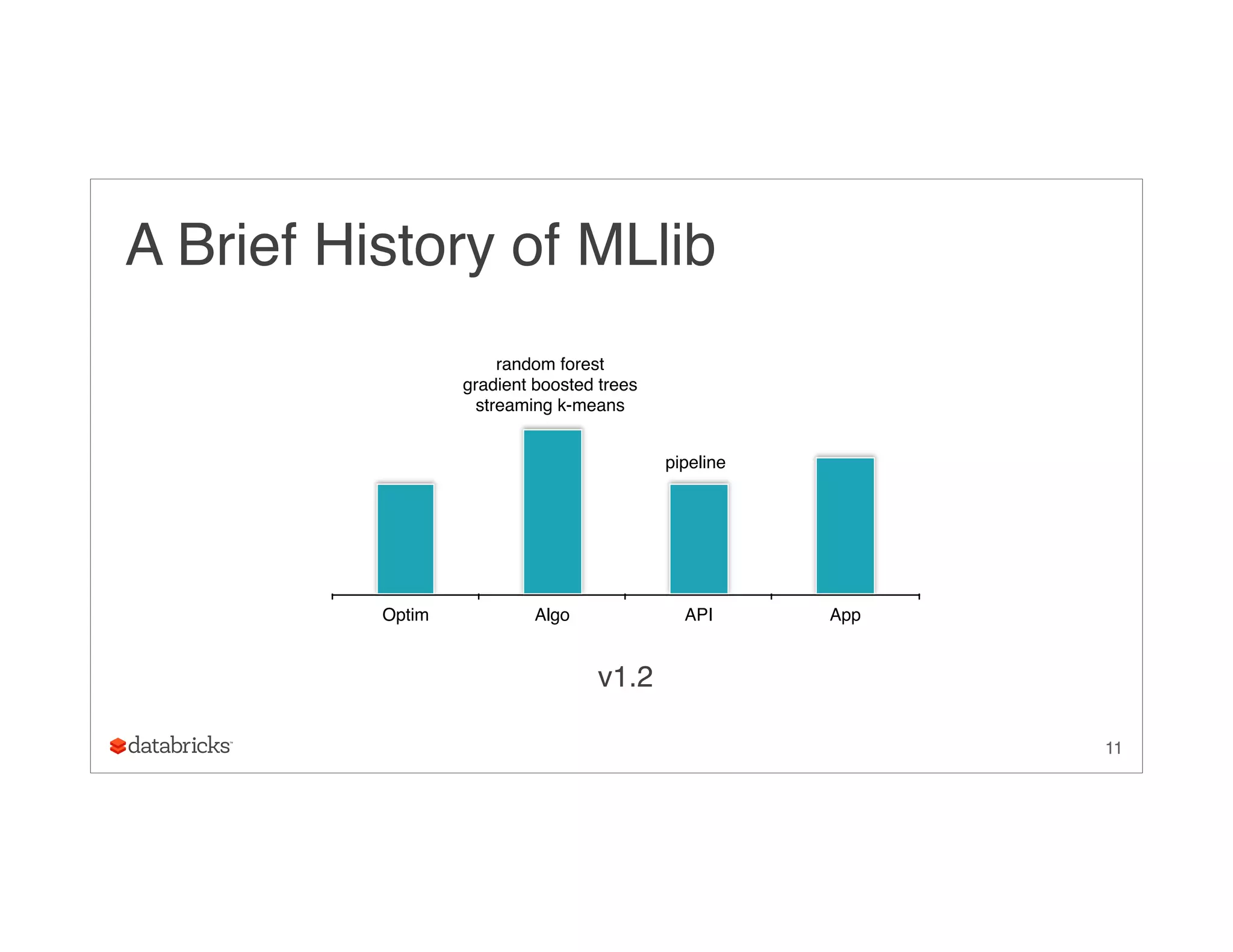







![Compressed Storage for InBlocks
Array of rating tuples
• huge storage overhead
• high garbage collection (GC) pressure
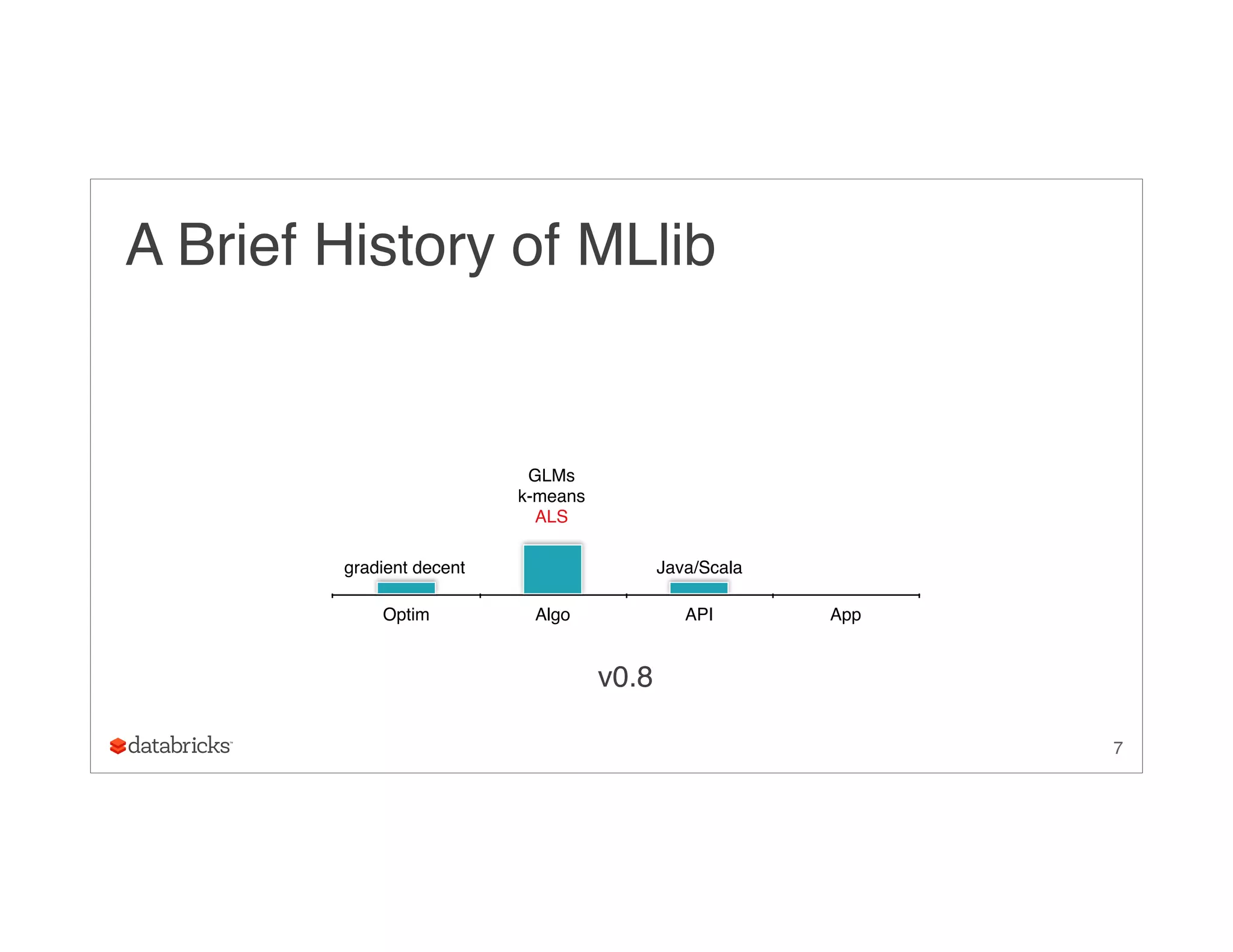
26
[(v1, u1, a11), (v2, u1, a12), (v1, u2, a21), (v2, u2, a22), (v2, u3, a32)]](https://image.slidesharecdn.com/ug9w968zrqosfrn8pjge-signature-2d63aa7ce78cf6cf6dc1997c333a9968cd9d59466a3de20e482334e6352ca045-poli-150624172757-lva1-app6891/75/A-More-Scaleable-Way-of-Making-Recommendations-with-MLlib-Xiangrui-Meng-Databricks-26-2048.jpg)
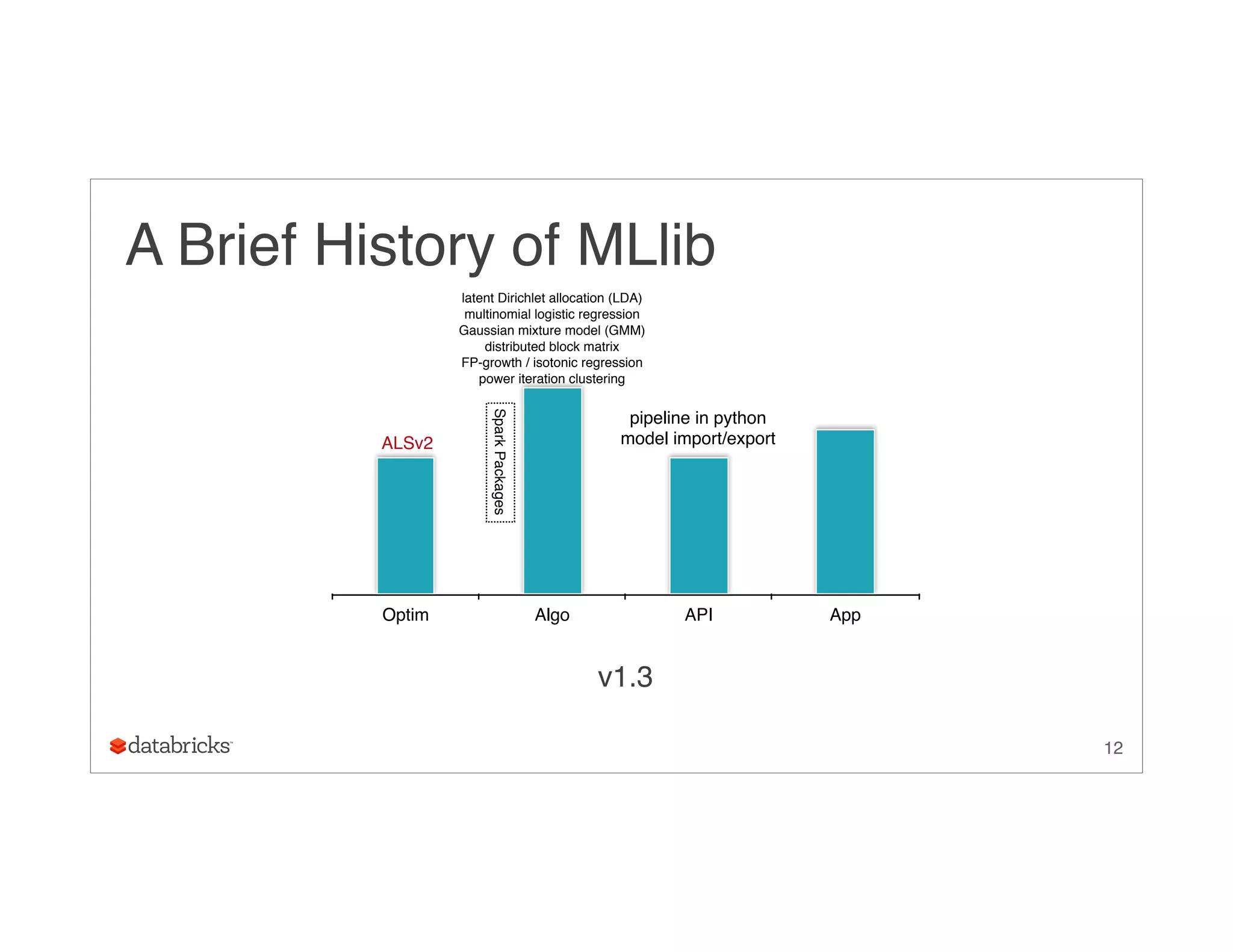
![Compressed Storage for InBlocks
Three primitive arrays
• low GC pressure
• constructing all sub-problems together
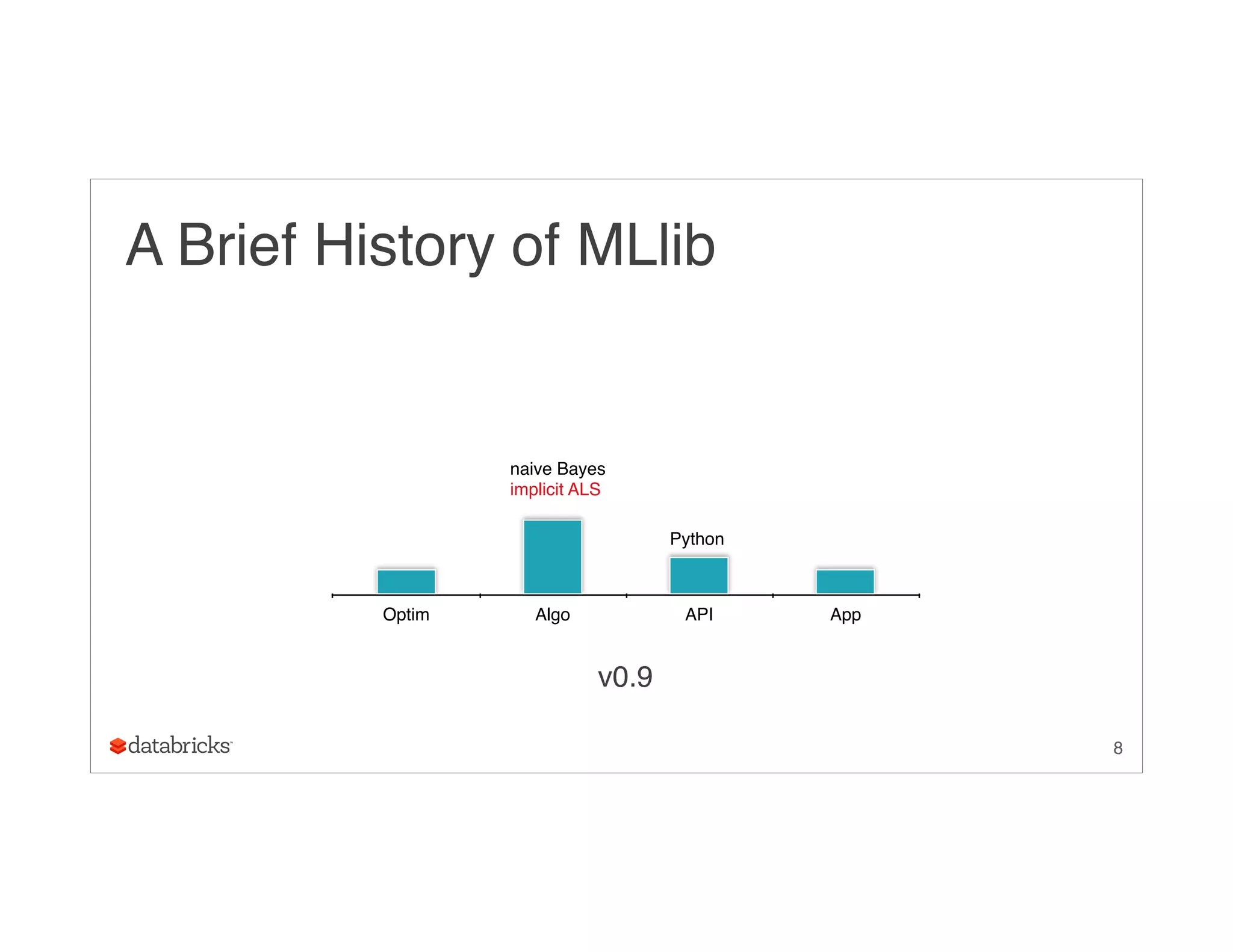
• O(nj k2) storage
27
([v1, v2, v1, v2, v2], [u1, u1, u2, u2, u3], [a11, a12, a21, a22, a32])](https://image.slidesharecdn.com/ug9w968zrqosfrn8pjge-signature-2d63aa7ce78cf6cf6dc1997c333a9968cd9d59466a3de20e482334e6352ca045-poli-150624172757-lva1-app6891/75/A-More-Scaleable-Way-of-Making-Recommendations-with-MLlib-Xiangrui-Meng-Databricks-27-2048.jpg)
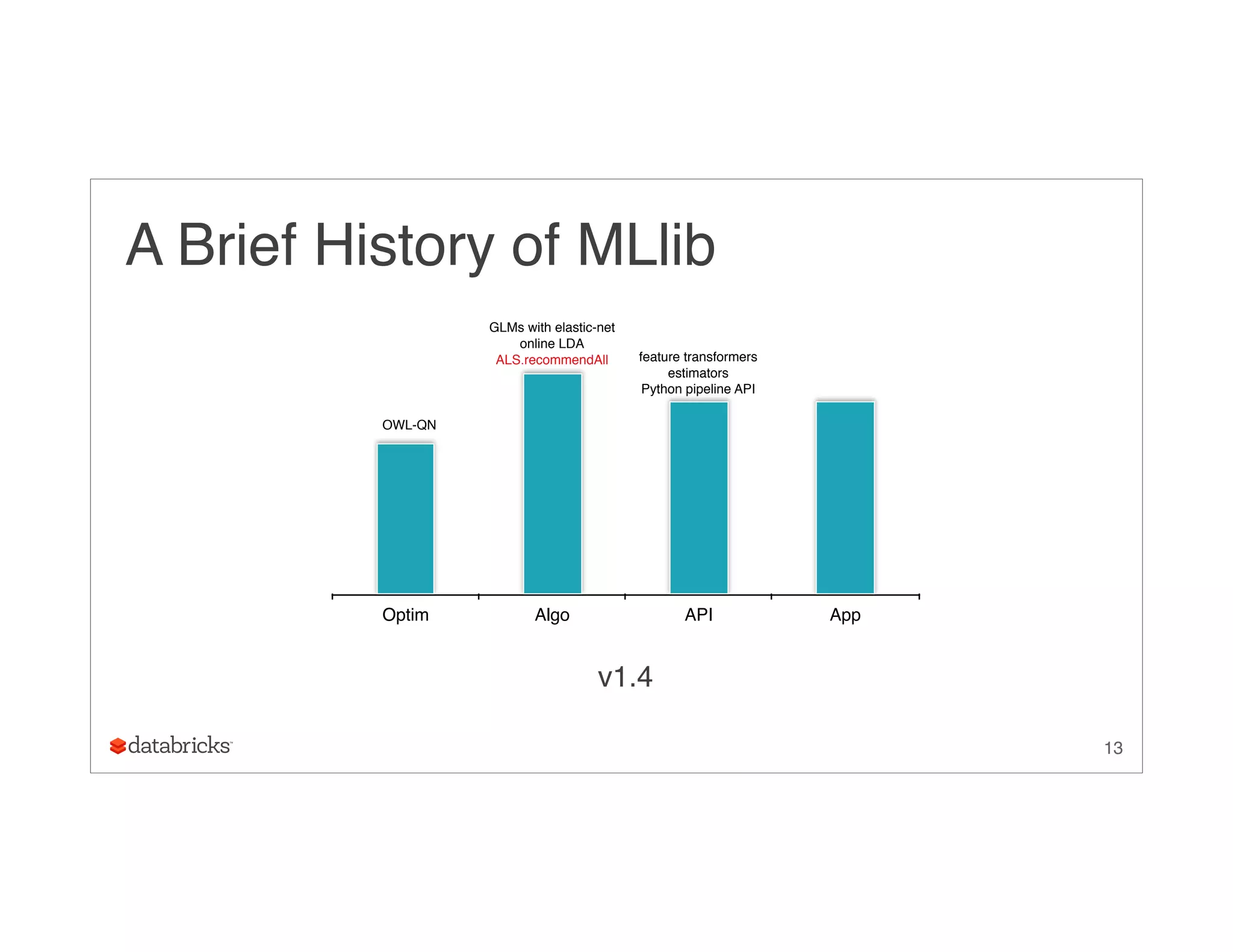
![Compressed Storage for InBlocks
Primitive arrays with items ordered:
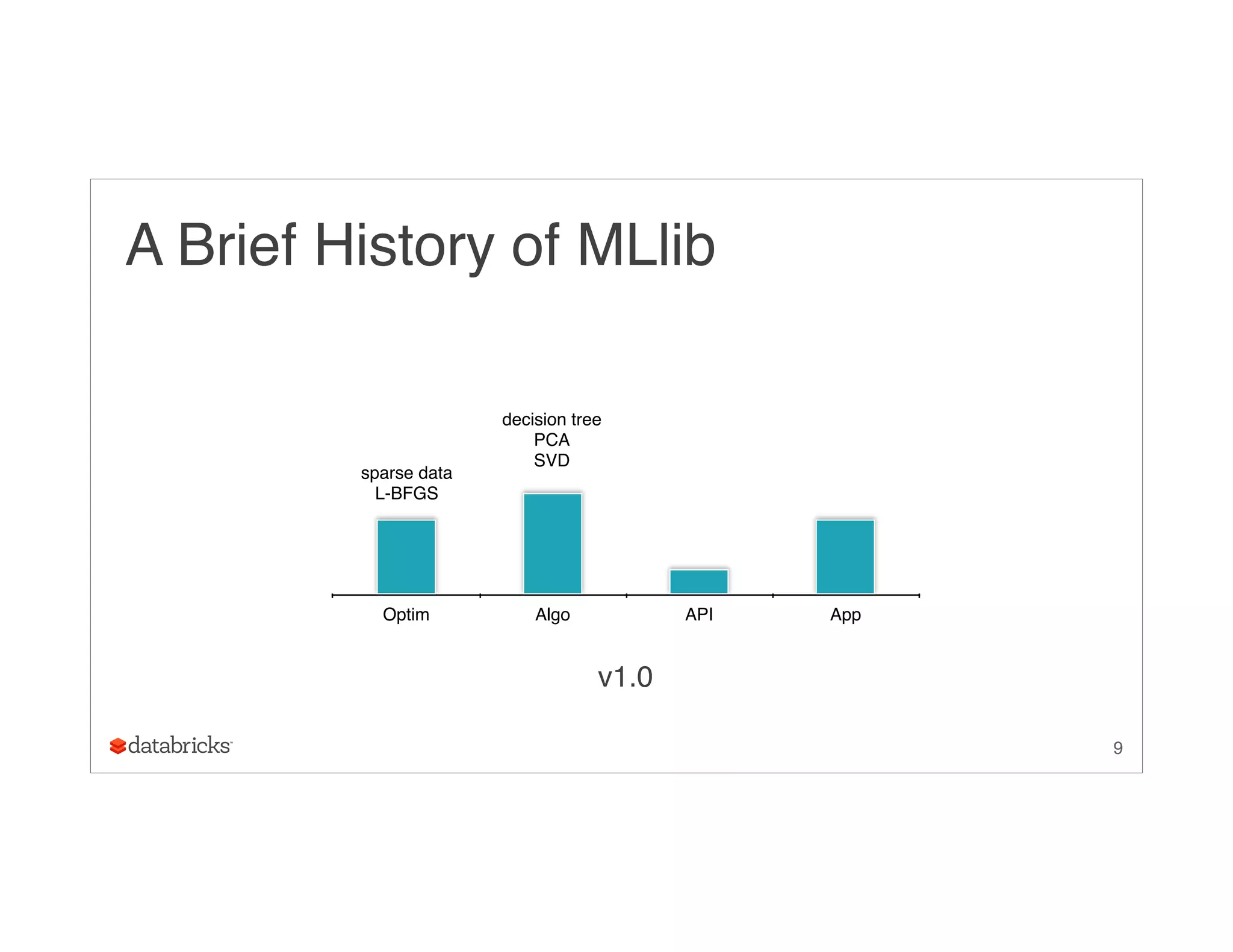
• solving sub-problems in sequence:
• O(k2) storage
• TimSort
28
([v1, v1, v2, v2, v2], [u1, u2, u1, u2, u3], [a11, a21, a12, a22, a32])](https://image.slidesharecdn.com/ug9w968zrqosfrn8pjge-signature-2d63aa7ce78cf6cf6dc1997c333a9968cd9d59466a3de20e482334e6352ca045-poli-150624172757-lva1-app6891/75/A-More-Scaleable-Way-of-Making-Recommendations-with-MLlib-Xiangrui-Meng-Databricks-28-2048.jpg)
![Compressed Storage for InBlocks
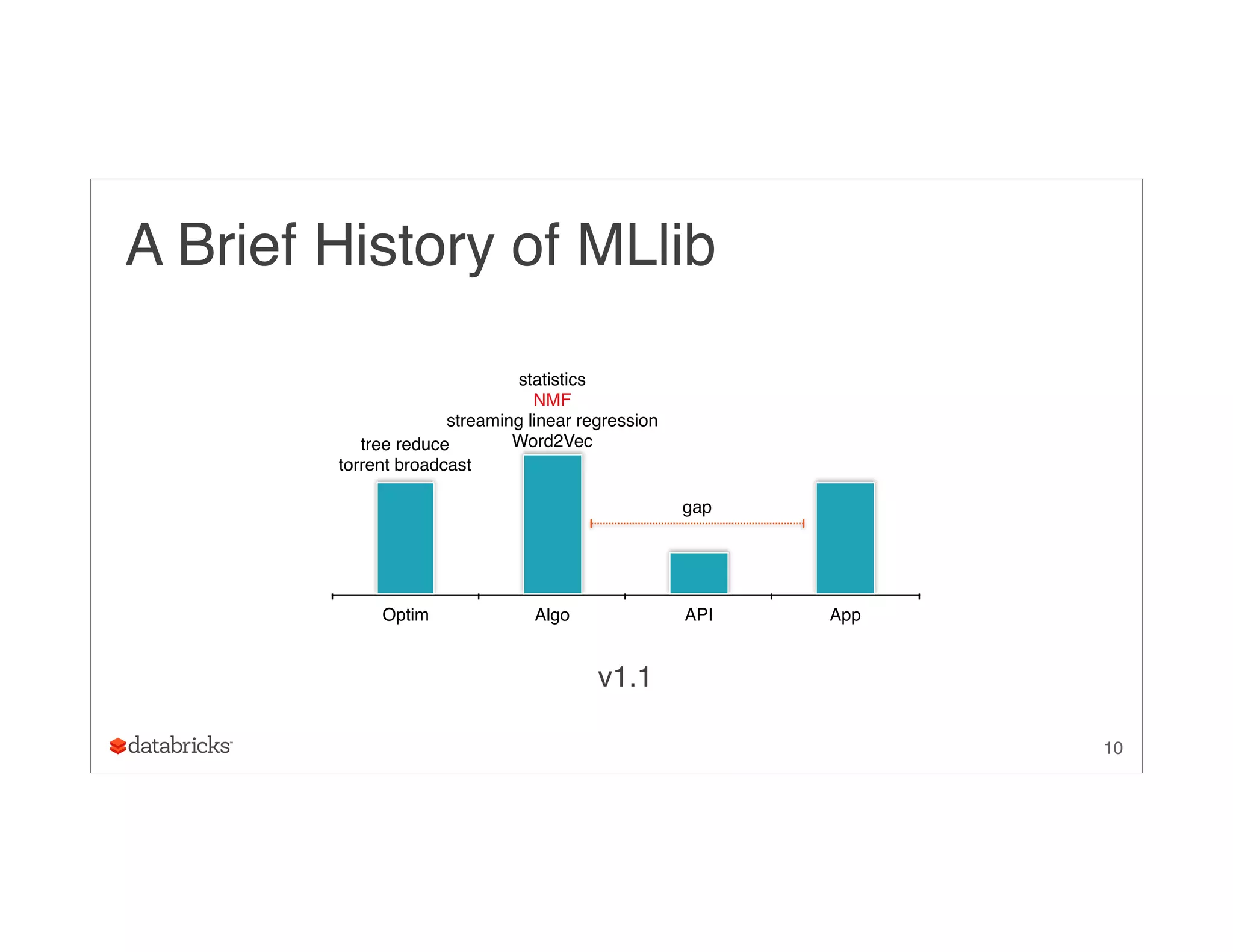
Compressed items:
• no duplicated items
• map lookup for user factors
29
([v1, v2], [0, 2, 5], [u1, u2, u1, u2, u3], [a11, a21, a12, a22, a32])](https://image.slidesharecdn.com/ug9w968zrqosfrn8pjge-signature-2d63aa7ce78cf6cf6dc1997c333a9968cd9d59466a3de20e482334e6352ca045-poli-150624172757-lva1-app6891/75/A-More-Scaleable-Way-of-Making-Recommendations-with-MLlib-Xiangrui-Meng-Databricks-29-2048.jpg)
![Compressed Storage for InBlocks
Store block IDs and local indices instead of user IDs. For example, u3
is the first vector sent from P2.
Encode (block ID, local index) into an integer
• use higher bits for block ID
• use lower bits for local index
• works for ~4 billions of unique users/items
01 | 00 0000 0000 0000
30
([v1, v2], [0, 2, 5], [0|0, 0|1, 0|0, 0|1, 1|0], [a11, a21, a12, a22, a32])](https://image.slidesharecdn.com/ug9w968zrqosfrn8pjge-signature-2d63aa7ce78cf6cf6dc1997c333a9968cd9d59466a3de20e482334e6352ca045-poli-150624172757-lva1-app6891/75/A-More-Scaleable-Way-of-Making-Recommendations-with-MLlib-Xiangrui-Meng-Databricks-30-2048.jpg)

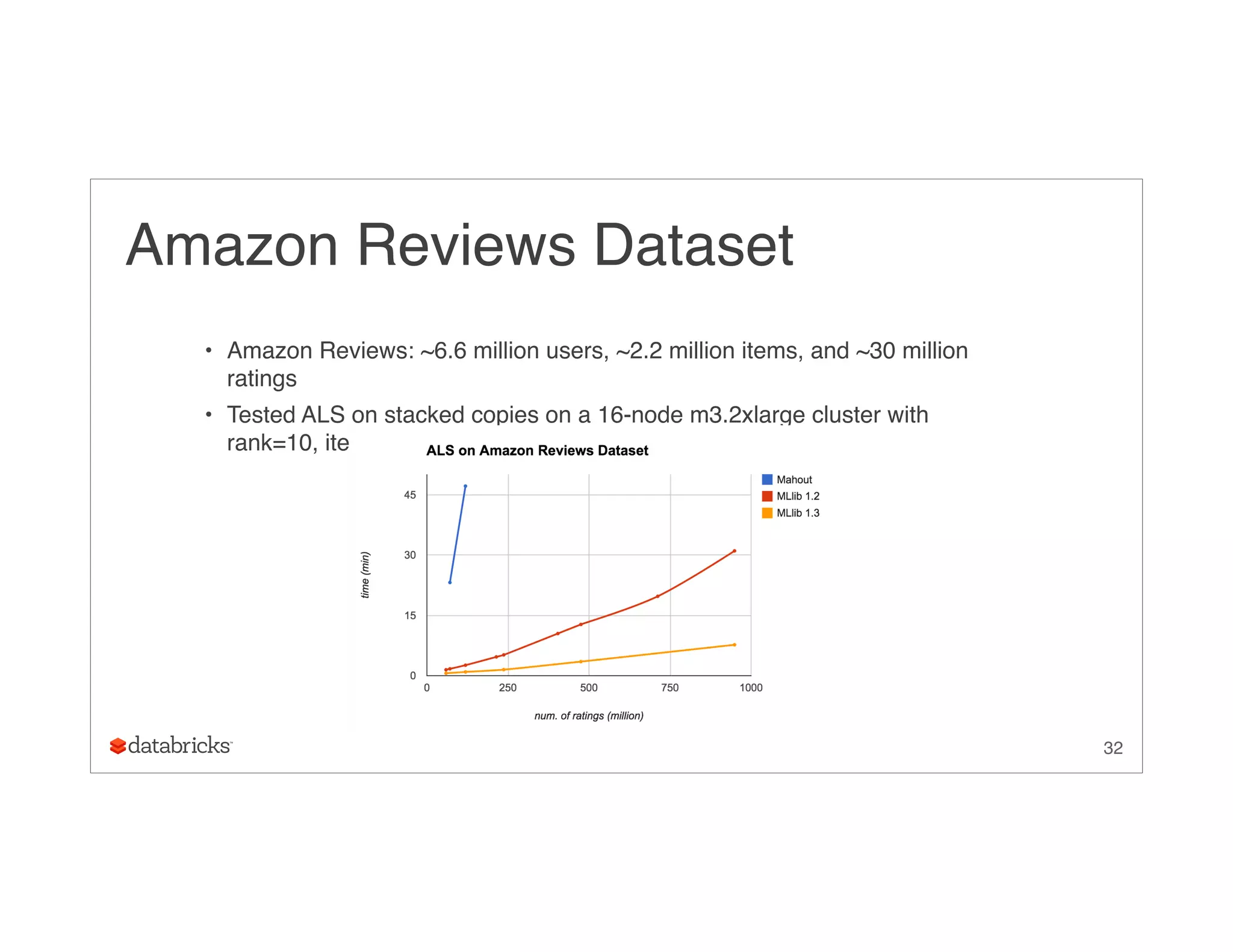
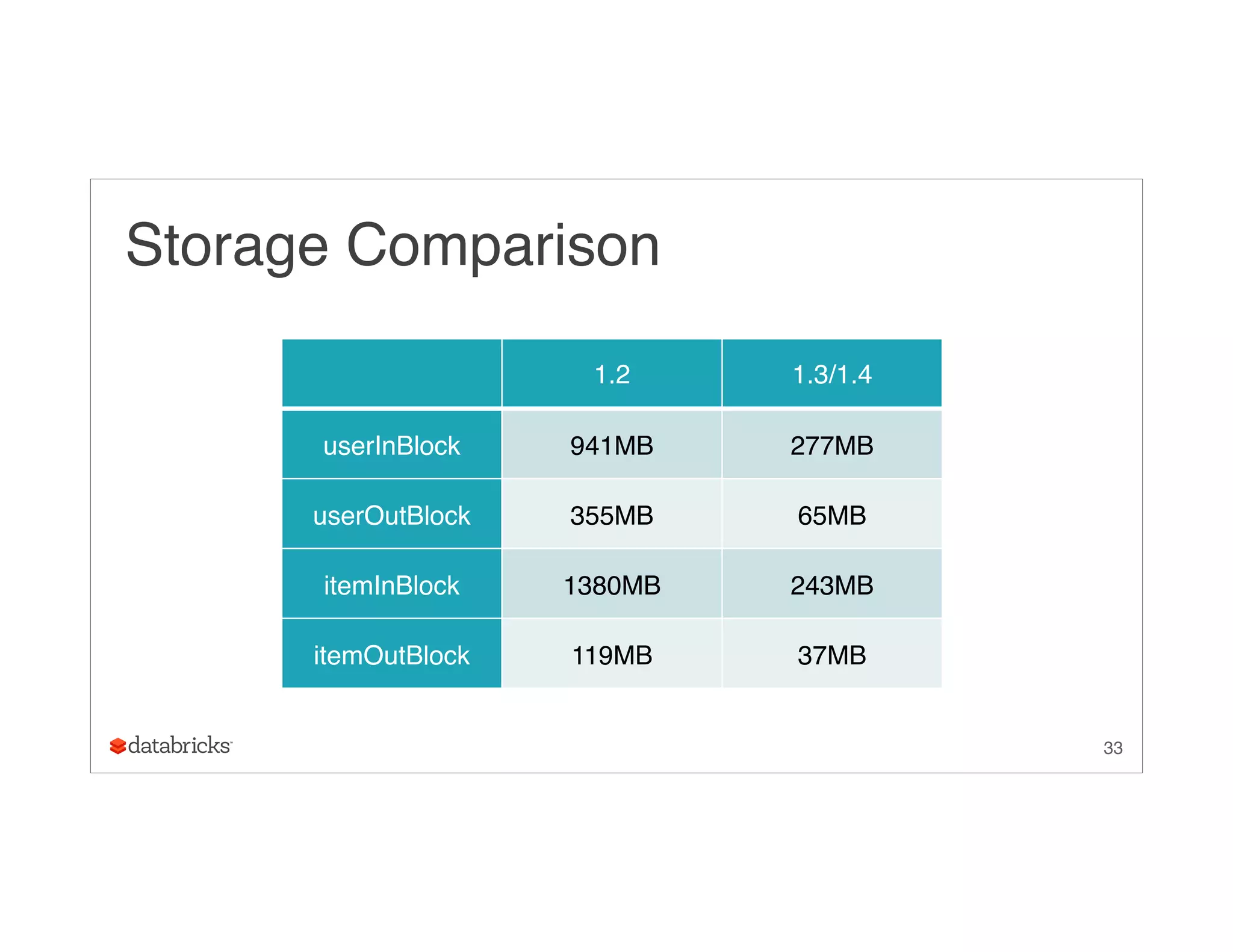





This document summarizes the implementation of Alternating Least Squares (ALS) in MLlib to make recommendations at scale. It discusses how MLlib reduces communication cost through a block-to-block approach and compressed storage formats. It also describes optimizations like avoiding garbage collection through specialized code. The ALS algorithm is tested on real-world datasets including Amazon reviews and Spotify music data involving billions of ratings.




































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

