Downloaded 46 times





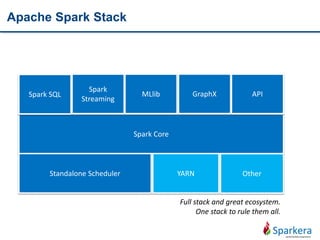





![Spark Program Flow by RDD
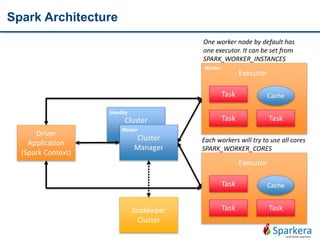
Create input
RDD
• spark context
• create from external
• create from SEQ
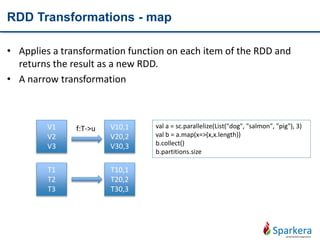
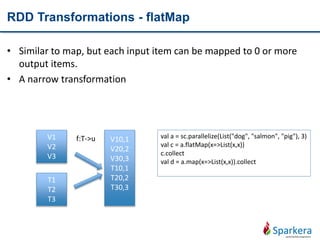
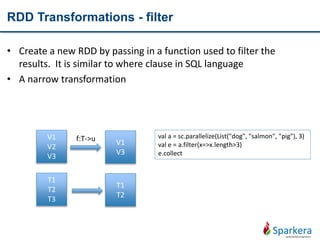
Transform
RDD
• Using map, flatmap, distinct, filter
• Wide/Narrow
Persist
intermediate
RDD
• Cache
• Persist
Action on RDD • Produce result
Example:
myRDD = sc.parallelize([1,2,3,4])
myRDD = sc.textFile("hdfs://tmp/shakepeare.txt”)](https://image.slidesharecdn.com/tentoolsfortenbigdataareas03apachespark-151219005831/85/Ten-tools-for-ten-big-data-areas-03_Apache-Spark-18-320.jpg)
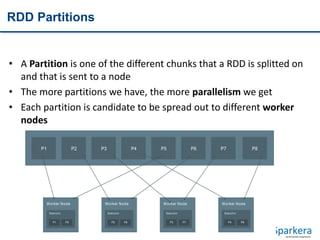
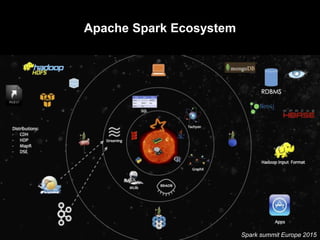
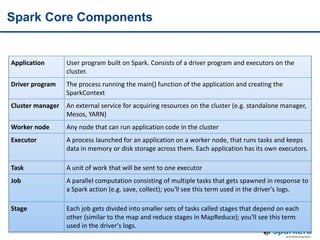
![RDD Operations
• RDD is the only data manipulation tool in Apache Spark
• Lazy and non-lazy operations
• There are two types of RDDs
Transformation – lazy – returns Array[T] by collect action
Actions – non-lazy – returns value
• Narrow and wide transformations](https://image.slidesharecdn.com/tentoolsfortenbigdataareas03apachespark-151219005831/85/Ten-tools-for-ten-big-data-areas-03_Apache-Spark-20-320.jpg)
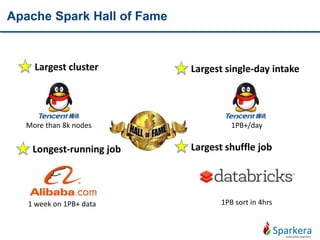
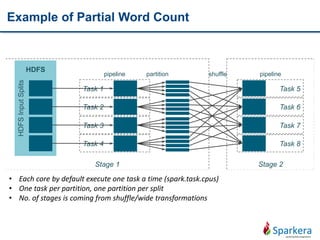
![RDD Transformations - sample
• Return a random sample subset RDD of the input RDD
• A narrow transformation
V1
V2
V3
V4
V5
V6
F:U=>v
val sam = sc.parallelize(1 to 10, 3)
sam.sample(false, 0.1, 0).collect
sam.sample(true, 0.3, 1).collect
V1
V2
V5
def sample(withReplacement: Boolean, fraction: Double, seed: Int): RDD[T]](https://image.slidesharecdn.com/tentoolsfortenbigdataareas03apachespark-151219005831/85/Ten-tools-for-ten-big-data-areas-03_Apache-Spark-24-320.jpg)
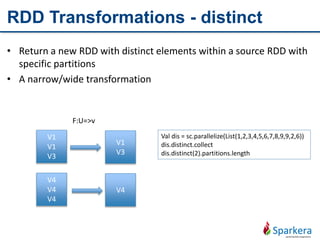
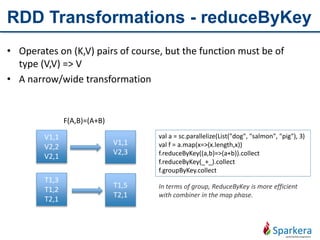
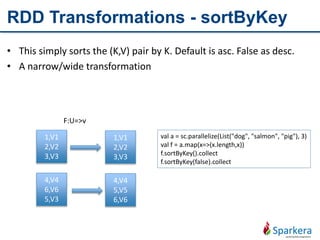
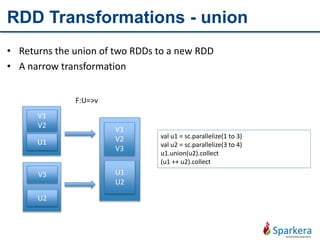









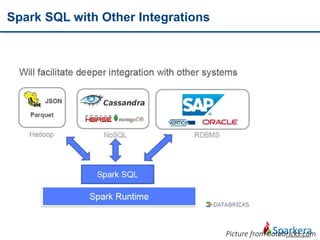

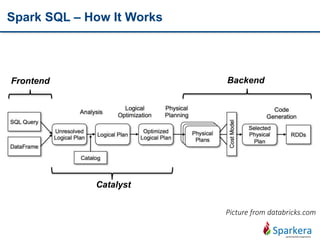

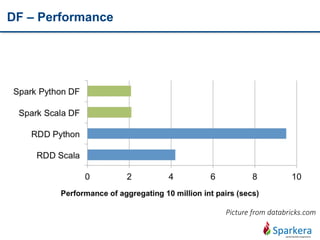





Apache Spark is a fast and general-purpose cluster computing system for large-scale data processing. It provides functions for distributed processing of large datasets across clusters using a concept called resilient distributed datasets (RDDs). RDDs allow in-memory clustering computing to improve performance. Spark also supports streaming, SQL, machine learning, and graph processing.



















































